 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheMCPCompany: Creating General-purpose Agents with Task-specific Tools
Oct 22, 2025Since the introduction of the Model Context Protocol (MCP), the number of available tools for Large Language Models (LLMs) has increased significantly. These task-specific tool sets offer an alternative to general-purpose tools such as web browsers, while being easier to develop and maintain than GUIs. However, current general-purpose agents predominantly rely on web browsers for interacting with the environment. Here, we introduce TheMCPCompany, a benchmark for evaluating tool-calling agents on tasks that involve interacting with various real-world services. We use the REST APIs of these services to create MCP servers, which include over 18,000 tools. We also provide manually annotated ground-truth tools for each task. In our experiments, we use the ground truth tools to show the potential of tool-calling agents for both improving performance and reducing costs assuming perfect tool retrieval. Next, we explore agent performance using tool retrieval to study the real-world practicality of tool-based agents. While all models with tool retrieval perform similarly or better than browser-based agents, smaller models cannot take full advantage of the available tools through retrieval. On the other hand, GPT-5's performance with tool retrieval is very close to its performance with ground-truth tools. Overall, our work shows that the most advanced reasoning models are effective at discovering tools in simpler environments, but seriously struggle with navigating complex enterprise environments. TheMCPCompany reveals that navigating tens of thousands of tools and combining them in non-trivial ways to solve complex problems is still a challenging task for current models and requires both better reasoning and better retrieval models.
Beyond Contrastive Learning: Synthetic Data Enables List-wise Training with Multiple Levels of Relevance
Mar 29, 2025Recent advancements in large language models (LLMs) have allowed the augmentation of information retrieval (IR) pipelines with synthetic data in various ways. Yet, the main training paradigm remains: contrastive learning with binary relevance labels and the InfoNCE loss, where one positive document is compared against one or more negatives. This objective treats all documents that are not explicitly annotated as relevant on an equally negative footing, regardless of their actual degree of relevance, thus (a) missing subtle nuances that are useful for ranking and (b) being susceptible to annotation noise. To overcome this limitation, in this work we forgo real training documents and annotations altogether and use open-source LLMs to directly generate synthetic documents that answer real user queries according to several different levels of relevance. This fully synthetic ranking context of graduated relevance, together with an appropriate list-wise loss (Wasserstein distance), enables us to train dense retrievers in a way that better captures the ranking task. Experiments on various IR datasets show that our proposed approach outperforms conventional training with InfoNCE by a large margin. Without using any real documents for training, our dense retriever significantly outperforms the same retriever trained through self-supervision. More importantly, it matches the performance of the same retriever trained on real, labeled training documents of the same dataset, while being more robust to distribution shift and clearly outperforming it when evaluated zero-shot on the BEIR dataset collection.
If CLIP Could Talk: Understanding Vision-Language Model Representations Through Their Preferred Concept Descriptions
Mar 25, 2024Recent works often assume that Vision-Language Model (VLM) representations are based on visual attributes like shape. However, it is unclear to what extent VLMs prioritize this information to represent concepts. We propose Extract and Explore (EX2), a novel approach to characterize important textual features for VLMs. EX2 uses reinforcement learning to align a large language model with VLM preferences and generates descriptions that incorporate the important features for the VLM. Then, we inspect the descriptions to identify the features that contribute to VLM representations. We find that spurious descriptions have a major role in VLM representations despite providing no helpful information, e.g., Click to enlarge photo of CONCEPT. More importantly, among informative descriptions, VLMs rely significantly on non-visual attributes like habitat to represent visual concepts. Also, our analysis reveals that different VLMs prioritize different attributes in their representations. Overall, we show that VLMs do not simply match images to scene descriptions and that non-visual or even spurious descriptions significantly influence their representations.
Follow-Up Differential Descriptions: Language Models Resolve Ambiguities for Image Classification
Nov 10, 2023
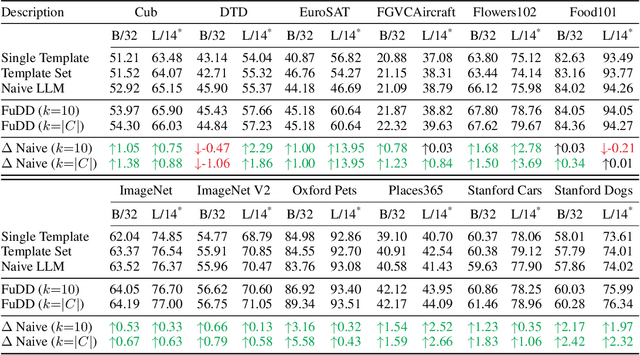
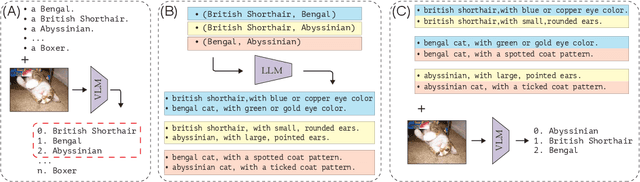
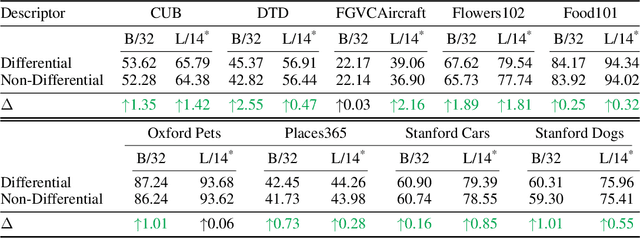
A promising approach for improving the performance of vision-language models like CLIP for image classification is to extend the class descriptions (i.e., prompts) with related attributes, e.g., using brown sparrow instead of sparrow. However, current zero-shot methods select a subset of attributes regardless of commonalities between the target classes, potentially providing no useful information that would have helped to distinguish between them. For instance, they may use color instead of bill shape to distinguish between sparrows and wrens, which are both brown. We propose Follow-up Differential Descriptions (FuDD), a zero-shot approach that tailors the class descriptions to each dataset and leads to additional attributes that better differentiate the target classes. FuDD first identifies the ambiguous classes for each image, and then uses a Large Language Model (LLM) to generate new class descriptions that differentiate between them. The new class descriptions resolve the initial ambiguity and help predict the correct label. In our experiments, FuDD consistently outperforms generic description ensembles and naive LLM-generated descriptions on 12 datasets. We show that differential descriptions are an effective tool to resolve class ambiguities, which otherwise significantly degrade the performance. We also show that high quality natural language class descriptions produced by FuDD result in comparable performance to few-shot adaptation methods.
An Adaptive Method for Weak Supervision with Drifting Data
Jun 02, 2023We introduce an adaptive method with formal quality guarantees for weak supervision in a non-stationary setting. Our goal is to infer the unknown labels of a sequence of data by using weak supervision sources that provide independent noisy signals of the correct classification for each data point. This setting includes crowdsourcing and programmatic weak supervision. We focus on the non-stationary case, where the accuracy of the weak supervision sources can drift over time, e.g., because of changes in the underlying data distribution. Due to the drift, older data could provide misleading information to infer the label of the current data point. Previous work relied on a priori assumptions on the magnitude of the drift to decide how much data to use from the past. Comparatively, our algorithm does not require any assumptions on the drift, and it adapts based on the input. In particular, at each step, our algorithm guarantees an estimation of the current accuracies of the weak supervision sources over a window of past observations that minimizes a trade-off between the error due to the variance of the estimation and the error due to the drift. Experiments on synthetic and real-world labelers show that our approach indeed adapts to the drift. Unlike fixed-window-size strategies, it dynamically chooses a window size that allows it to consistently maintain good performance.
Pseudo Shots: Few-Shot Learning with Auxiliary Data
Jan 16, 2021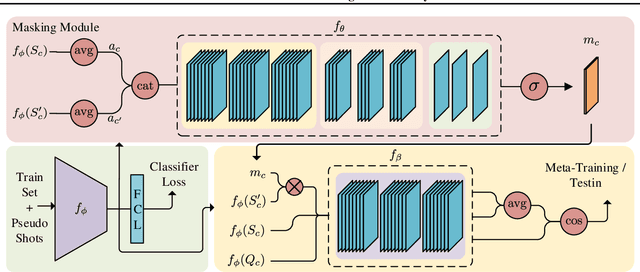
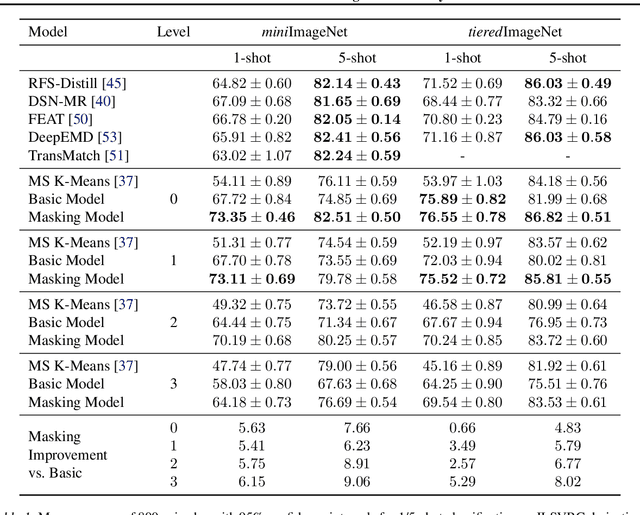
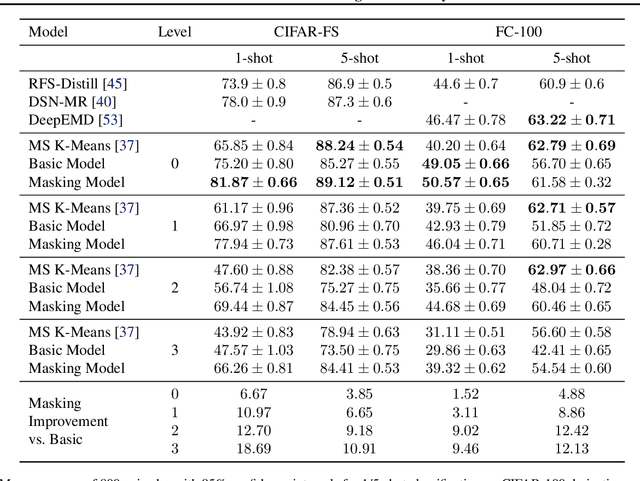

In many practical few-shot learning problems, even though labeled examples are scarce, there are abundant auxiliary data sets that potentially contain useful information. We propose a framework to address the challenges of efficiently selecting and effectively using auxiliary data in image classification. Given an auxiliary dataset and a notion of semantic similarity among classes, we automatically select pseudo shots, which are labeled examples from other classes related to the target task. We show that naively assuming that these additional examples come from the same distribution as the target task examples does not significantly improve accuracy. Instead, we propose a masking module that adjusts the features of auxiliary data to be more similar to those of the target classes. We show that this masking module can improve accuracy by up to 18 accuracy points, particularly when the auxiliary data is semantically distant from the target task. We also show that incorporating pseudo shots improves over the current state-of-the-art few-shot image classification scores by an average of 4.81 percentage points of accuracy on 1-shot tasks and an average of 0.31 percentage points on 5-shot tasks.
Multiple Abnormality Detection for Automatic Medical Image Diagnosis Using Bifurcated Convolutional Neural Network
Oct 15, 2018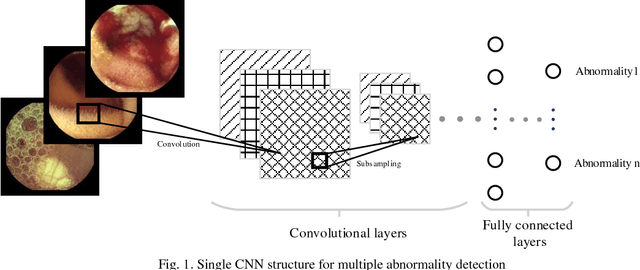
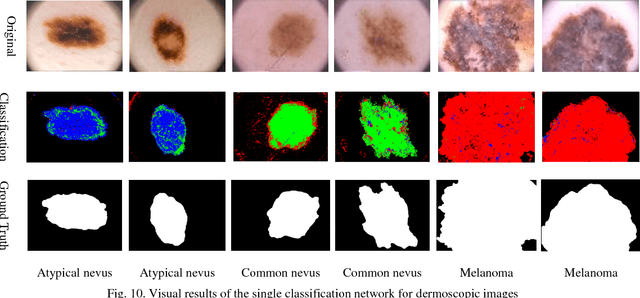
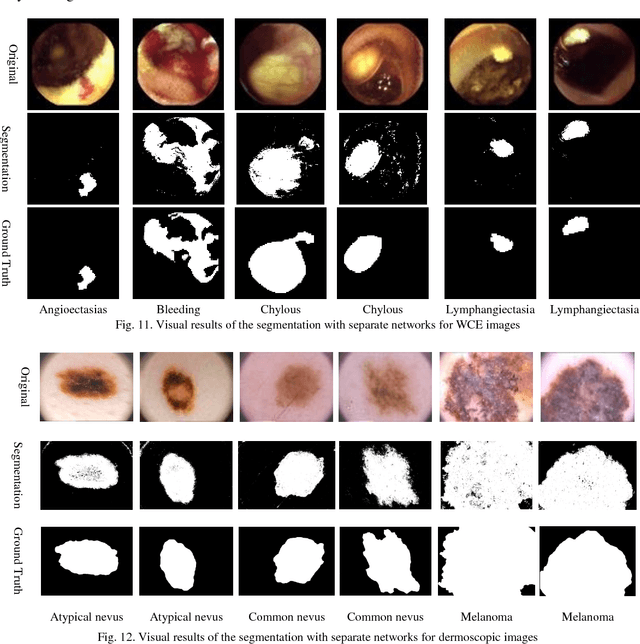
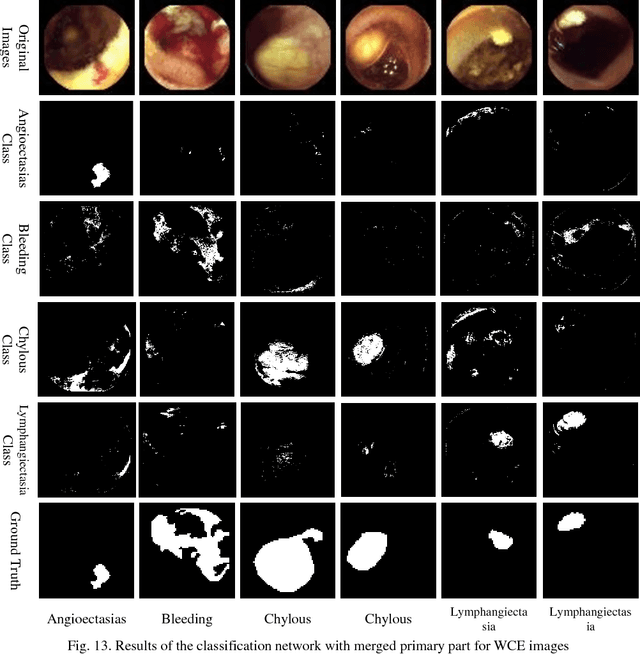
Automating classification and segmentation process of abnormal regions in different body organs has a crucial role in most of medical imaging applications such as funduscopy, endoscopy, and dermoscopy. Detecting multiple abnormalities in each type of images is necessary for better and more accurate diagnosis procedure and medical decisions. In recent years portable medical imaging devices such as capsule endoscopy and digital dermatoscope have been introduced and made the diagnosis procedure easier and more efficient. However, these portable devices have constrained power resources and limited computational capability. To address this problem, we propose a bifurcated structure for convolutional neural networks performing both classification and segmentation of multiple abnormalities simultaneously. The proposed network is first trained by each abnormality separately. Then the network is trained using all abnormalities. In order to reduce the computational complexity, the network is redesigned to share some features which are common among all abnormalities. Later, these shared features are used in different settings (directions) to segment and classify the abnormal region of the image. Finally, results of the classification and segmentation directions are fused to obtain the classified segmentation map. Proposed framework is simulated using four frequent gastrointestinal abnormalities as well as three dermoscopic lesions and for evaluation of the proposed framework the results are compared with the corresponding ground truth map. Properties of the bifurcated network like low complexity and resource sharing make it suitable to be implemented as a part of portable medical imaging devices.
Segmentation of Bleeding Regions in Wireless Capsule Endoscopy for Detection of Informative Frames
Aug 23, 2018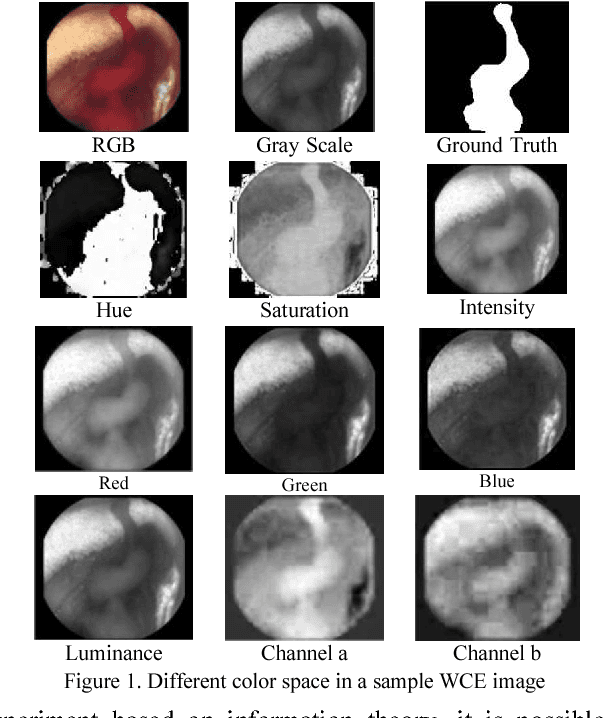
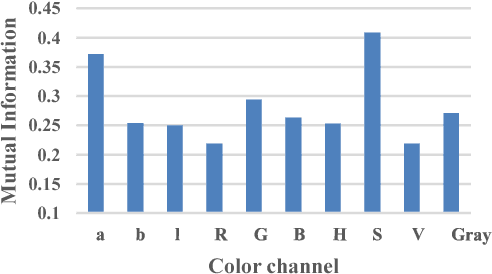
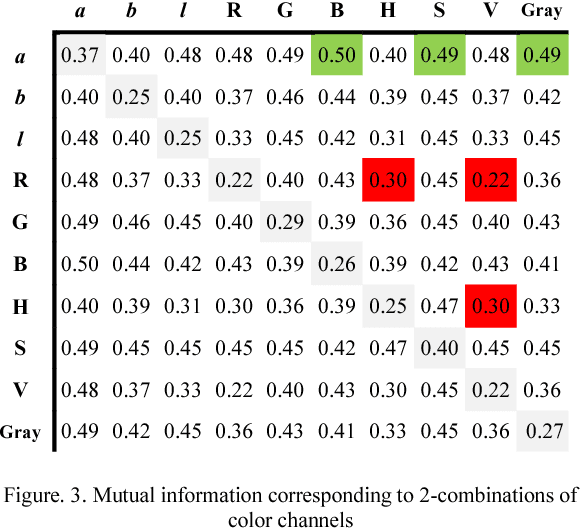
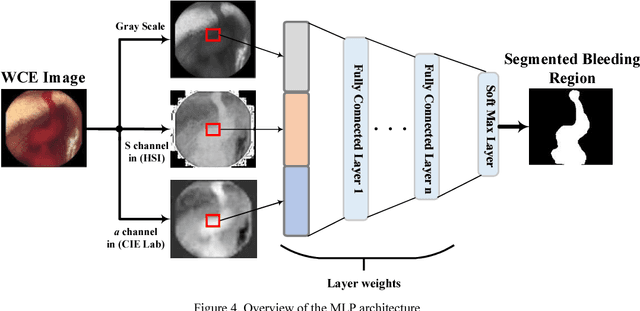
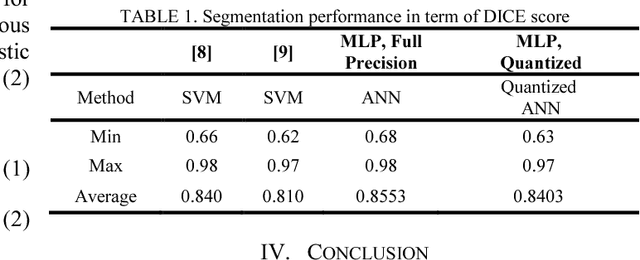
Wireless capsule endoscopy (WCE) is an effective mean for diagnosis of gastrointestinal disorders. Detection of informative scenes in WCE video could reduce the length of transmitted videos and help the diagnosis procedure. In this paper, we investigate the problem of simplification of neural networks for automatic bleeding region detection inside capsule endoscopy device. Suitable color channels are selected as neural networks inputs, and image classification is conducted using a multi-layer perceptron (MLP) and a convolutional neural network (CNN) separately. Both CNN and MLP structures are simplified to reduce the number of computational operations. Performances of two simplified networks are evaluated on a WCE bleeding image dataset using the DICE score. Simulation results show that applying simplification methods on both MLP and CNN structures reduces the number of computational operations significantly with AUC greater than 0.97. Although CNN performs better in comparison with simplified MLP, the simplified MLP segments bleeding regions with a significantly smaller number of computational operations. Concerning the importance of having a simple structure or a more accurate model, each of the designed structures could be selected for inside capsule implementation.
Segmentation of Bleeding Regions in Wireless Capsule Endoscopy Images an Approach for inside Capsule Video Summarization
Feb 21, 2018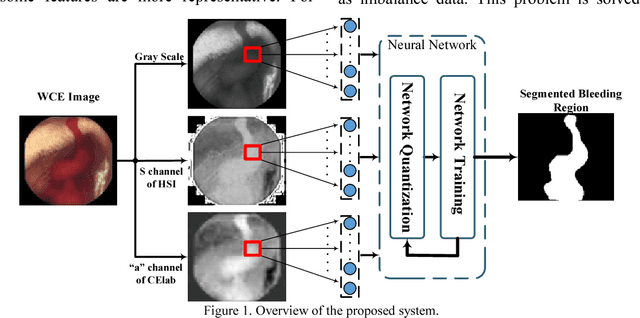
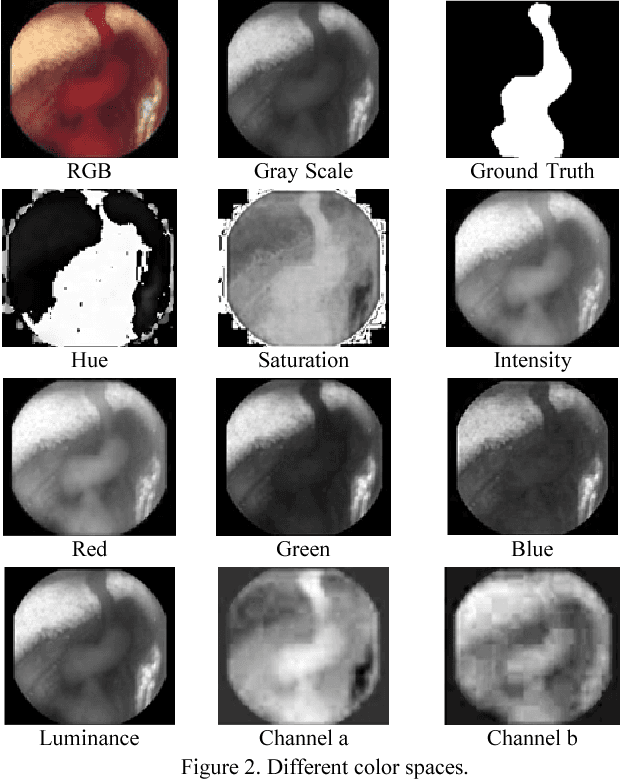
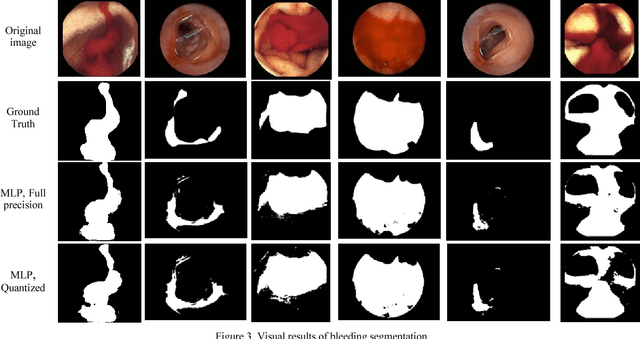
Wireless capsule endoscopy (WCE) is an effective means of diagnosis of gastrointestinal disorders. Detection of informative scenes by WCE could reduce the length of transmitted videos and can help with the diagnosis. In this paper we propose a simple and efficient method for segmentation of the bleeding regions in WCE captured images. Suitable color channels are selected and classified by a multi-layer perceptron (MLP) structure. The MLP structure is quantized such that the implementation does not require multiplications. The proposed method is tested by simulation on WCE bleeding image dataset. The proposed structure is designed considering hardware resource constrains that exist in WCE systems.