 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo Shots: Few-Shot Learning with Auxiliary Data
Paper and Code
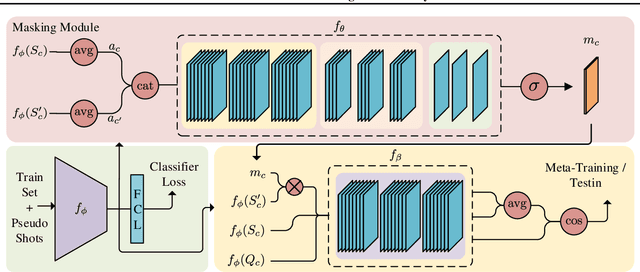
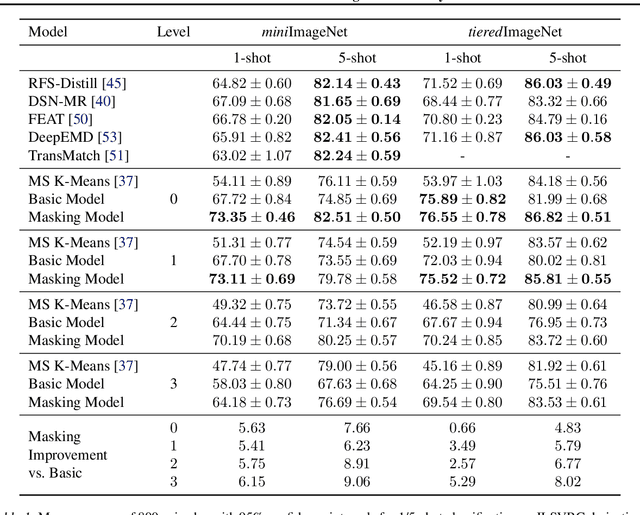
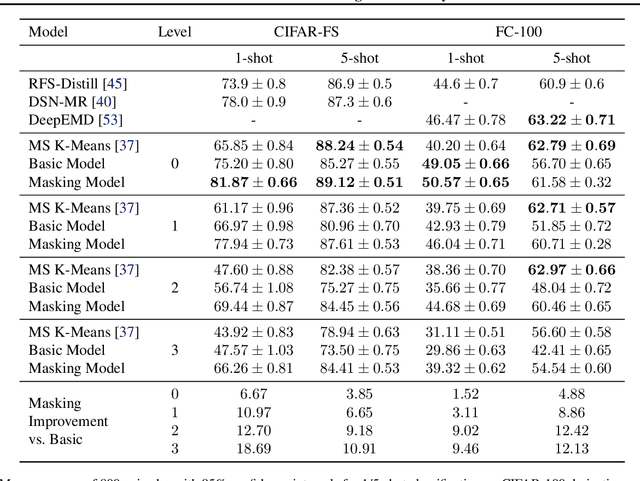

In many practical few-shot learning problems, even though labeled examples are scarce, there are abundant auxiliary data sets that potentially contain useful information. We propose a framework to address the challenges of efficiently selecting and effectively using auxiliary data in image classification. Given an auxiliary dataset and a notion of semantic similarity among classes, we automatically select pseudo shots, which are labeled examples from other classes related to the target task. We show that naively assuming that these additional examples come from the same distribution as the target task examples does not significantly improve accuracy. Instead, we propose a masking module that adjusts the features of auxiliary data to be more similar to those of the target classes. We show that this masking module can improve accuracy by up to 18 accuracy points, particularly when the auxiliary data is semantically distant from the target task. We also show that incorporating pseudo shots improves over the current state-of-the-art few-shot image classification scores by an average of 4.81 percentage points of accuracy on 1-shot tasks and an average of 0.31 percentage points on 5-shot tasks.