 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgetensorFM: Low-Rank Approximations of Cross-Order Feature Interactions
Feb 16, 2026We address prediction problems on tabular categorical data, where each instance is defined by multiple categorical attributes, each taking values from a finite set. These attributes are often referred to as fields, and their categorical values as features. Such problems frequently arise in practical applications, including click-through rate prediction and social sciences. We introduce and analyze {tensorFM}, a new model that efficiently captures high-order interactions between attributes via a low-rank tensor approximation representing the strength of these interactions. Our model generalizes field-weighted factorization machines. Empirically, tensorFM demonstrates competitive performance with state-of-the-art methods. Additionally, its low latency makes it well-suited for time-sensitive applications, such as online advertising.
An Improved Algorithm for Learning Drifting Discrete Distributions
Mar 08, 2024We present a new adaptive algorithm for learning discrete distributions under distribution drift. In this setting, we observe a sequence of independent samples from a discrete distribution that is changing over time, and the goal is to estimate the current distribution. Since we have access to only a single sample for each time step, a good estimation requires a careful choice of the number of past samples to use. To use more samples, we must resort to samples further in the past, and we incur a drift error due to the bias introduced by the change in distribution. On the other hand, if we use a small number of past samples, we incur a large statistical error as the estimation has a high variance. We present a novel adaptive algorithm that can solve this trade-off without any prior knowledge of the drift. Unlike previous adaptive results, our algorithm characterizes the statistical error using data-dependent bounds. This technicality enables us to overcome the limitations of the previous work that require a fixed finite support whose size is known in advance and that cannot change over time. Additionally, we can obtain tighter bounds depending on the complexity of the drifting distribution, and also consider distributions with infinite support.
An Adaptive Method for Weak Supervision with Drifting Data
Jun 02, 2023

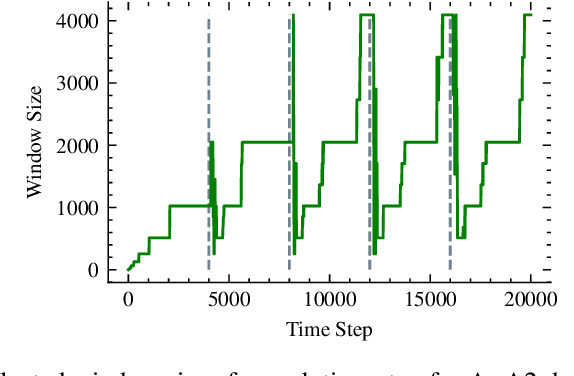

We introduce an adaptive method with formal quality guarantees for weak supervision in a non-stationary setting. Our goal is to infer the unknown labels of a sequence of data by using weak supervision sources that provide independent noisy signals of the correct classification for each data point. This setting includes crowdsourcing and programmatic weak supervision. We focus on the non-stationary case, where the accuracy of the weak supervision sources can drift over time, e.g., because of changes in the underlying data distribution. Due to the drift, older data could provide misleading information to infer the label of the current data point. Previous work relied on a priori assumptions on the magnitude of the drift to decide how much data to use from the past. Comparatively, our algorithm does not require any assumptions on the drift, and it adapts based on the input. In particular, at each step, our algorithm guarantees an estimation of the current accuracies of the weak supervision sources over a window of past observations that minimizes a trade-off between the error due to the variance of the estimation and the error due to the drift. Experiments on synthetic and real-world labelers show that our approach indeed adapts to the drift. Unlike fixed-window-size strategies, it dynamically chooses a window size that allows it to consistently maintain good performance.
An Adaptive Algorithm for Learning with Unknown Distribution Drift
May 03, 2023We develop and analyze a general technique for learning with an unknown distribution drift. Given a sequence of independent observations from the last $T$ steps of a drifting distribution, our algorithm agnostically learns a family of functions with respect to the current distribution at time $T$. Unlike previous work, our technique does not require prior knowledge about the magnitude of the drift. Instead, the algorithm adapts to the sample data. Without explicitly estimating the drift, the algorithm learns a family of functions with almost the same error as a learning algorithm that knows the magnitude of the drift in advance. Furthermore, since our algorithm adapts to the data, it can guarantee a better learning error than an algorithm that relies on loose bounds on the drift.
Nonparametric Density Estimation under Distribution Drift
Feb 05, 2023
We study nonparametric density estimation in non-stationary drift settings. Given a sequence of independent samples taken from a distribution that gradually changes in time, the goal is to compute the best estimate for the current distribution. We prove tight minimax risk bounds for both discrete and continuous smooth densities, where the minimum is over all possible estimates and the maximum is over all possible distributions that satisfy the drift constraints. Our technique handles a broad class of drift models, and generalizes previous results on agnostic learning under drift.
Tight Lower Bounds on Worst-Case Guarantees for Zero-Shot Learning with Attributes
May 25, 2022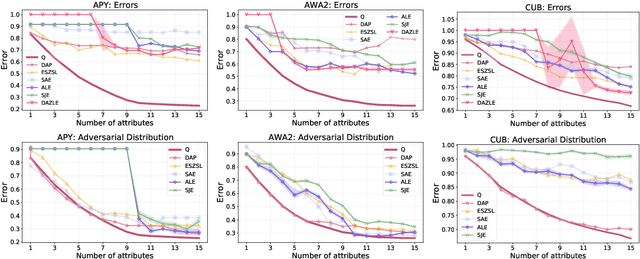
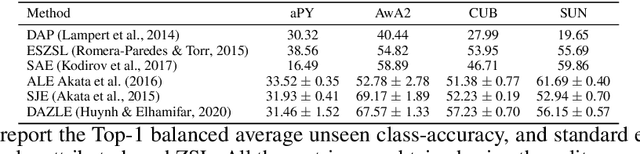
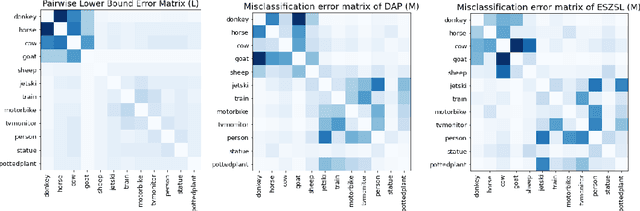
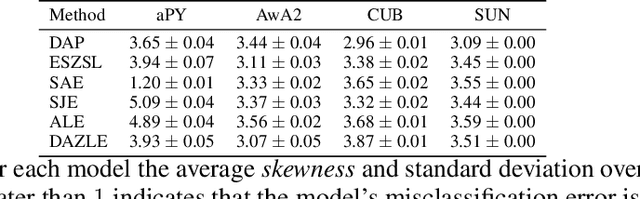
We develop a rigorous mathematical analysis of zero-shot learning with attributes. In this setting, the goal is to label novel classes with no training data, only detectors for attributes and a description of how those attributes are correlated with the target classes, called the class-attribute matrix. We develop the first non-trivial lower bound on the worst-case error of the best map from attributes to classes for this setting, even with perfect attribute detectors. The lower bound characterizes the theoretical intrinsic difficulty of the zero-shot problem based on the available information -- the class-attribute matrix -- and the bound is practically computable from it. Our lower bound is tight, as we show that we can always find a randomized map from attributes to classes whose expected error is upper bounded by the value of the lower bound. We show that our analysis can be predictive of how standard zero-shot methods behave in practice, including which classes will likely be confused with others.