 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Eavesdropping in the Presence of Adversarial Communications for RF Fingerprinting
Mar 06, 2025Deep learning is an effective approach for performing radio frequency (RF) fingerprinting, which aims to identify the transmitter corresponding to received RF signals. However, beyond the intended receiver, malicious eavesdroppers can also intercept signals and attempt to fingerprint transmitters communicating over a wireless channel. Recent studies suggest that transmitters can counter such threats by embedding deep learning-based transferable adversarial attacks in their signals before transmission. In this work, we develop a time-frequency-based eavesdropper architecture that is capable of withstanding such transferable adversarial perturbations and thus able to perform effective RF fingerprinting. We theoretically demonstrate that adversarial perturbations injected by a transmitter are confined to specific time-frequency regions that are insignificant during inference, directly increasing fingerprinting accuracy on perturbed signals intercepted by the eavesdropper. Empirical evaluations on a real-world dataset validate our theoretical findings, showing that deep learning-based RF fingerprinting eavesdroppers can achieve classification performance comparable to the intended receiver, despite efforts made by the transmitter to deceive the eavesdropper. Our framework reveals that relying on transferable adversarial attacks may not be sufficient to prevent eavesdroppers from successfully fingerprinting transmissions in next-generation deep learning-based communications systems.
FameBias: Embedding Manipulation Bias Attack in Text-to-Image Models
Dec 24, 2024
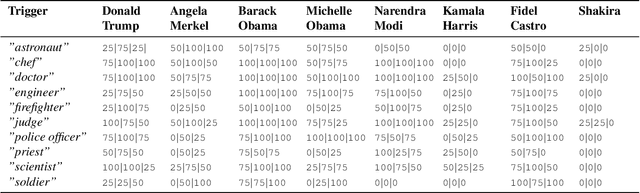


Text-to-Image (T2I) diffusion models have rapidly advanced, enabling the generation of high-quality images that align closely with textual descriptions. However, this progress has also raised concerns about their misuse for propaganda and other malicious activities. Recent studies reveal that attackers can embed biases into these models through simple fine-tuning, causing them to generate targeted imagery when triggered by specific phrases. This underscores the potential for T2I models to act as tools for disseminating propaganda, producing images aligned with an attacker's objective for end-users. Building on this concept, we introduce FameBias, a T2I biasing attack that manipulates the embeddings of input prompts to generate images featuring specific public figures. Unlike prior methods, Famebias operates solely on the input embedding vectors without requiring additional model training. We evaluate FameBias comprehensively using Stable Diffusion V2, generating a large corpus of images based on various trigger nouns and target public figures. Our experiments demonstrate that FameBias achieves a high attack success rate while preserving the semantic context of the original prompts across multiple trigger-target pairs.
CTRQNets & LQNets: Continuous Time Recurrent and Liquid Quantum Neural Networks
Aug 28, 2024Neural networks have continued to gain prevalence in the modern era for their ability to model complex data through pattern recognition and behavior remodeling. However, the static construction of traditional neural networks inhibits dynamic intelligence. This makes them inflexible to temporal changes in data and unfit to capture complex dependencies. With the advent of quantum technology, there has been significant progress in creating quantum algorithms. In recent years, researchers have developed quantum neural networks that leverage the capabilities of qubits to outperform classical networks. However, their current formulation exhibits a static construction limiting the system's dynamic intelligence. To address these weaknesses, we develop a Liquid Quantum Neural Network (LQNet) and a Continuous Time Recurrent Quantum Neural Network (CTRQNet). Both models demonstrate a significant improvement in accuracy compared to existing quantum neural networks (QNNs), achieving accuracy increases as high as 40\% on CIFAR 10 through binary classification. We propose LQNets and CTRQNets might shine a light on quantum machine learning's black box.
Future Lens: Anticipating Subsequent Tokens from a Single Hidden State
Nov 08, 2023


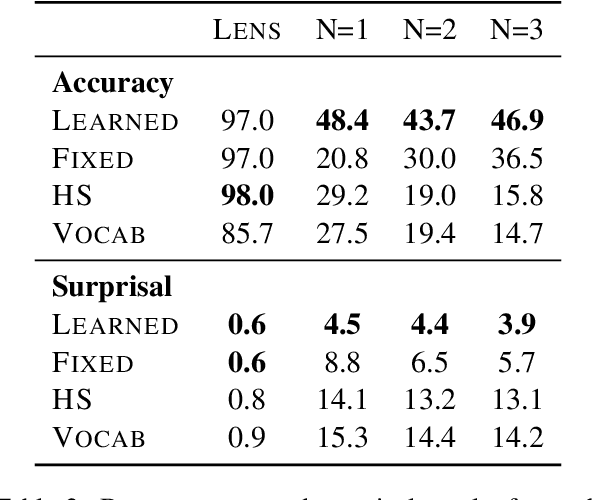
We conjecture that hidden state vectors corresponding to individual input tokens encode information sufficient to accurately predict several tokens ahead. More concretely, in this paper we ask: Given a hidden (internal) representation of a single token at position $t$ in an input, can we reliably anticipate the tokens that will appear at positions $\geq t + 2$? To test this, we measure linear approximation and causal intervention methods in GPT-J-6B to evaluate the degree to which individual hidden states in the network contain signal rich enough to predict future hidden states and, ultimately, token outputs. We find that, at some layers, we can approximate a model's output with more than 48% accuracy with respect to its prediction of subsequent tokens through a single hidden state. Finally we present a "Future Lens" visualization that uses these methods to create a new view of transformer states.
Dropout Attacks
Sep 04, 2023Dropout is a common operator in deep learning, aiming to prevent overfitting by randomly dropping neurons during training. This paper introduces a new family of poisoning attacks against neural networks named DROPOUTATTACK. DROPOUTATTACK attacks the dropout operator by manipulating the selection of neurons to drop instead of selecting them uniformly at random. We design, implement, and evaluate four DROPOUTATTACK variants that cover a broad range of scenarios. These attacks can slow or stop training, destroy prediction accuracy of target classes, and sabotage either precision or recall of a target class. In our experiments of training a VGG-16 model on CIFAR-100, our attack can reduce the precision of the victim class by 34.6% (from 81.7% to 47.1%) without incurring any degradation in model accuracy
Tight Lower Bounds on Worst-Case Guarantees for Zero-Shot Learning with Attributes
May 25, 2022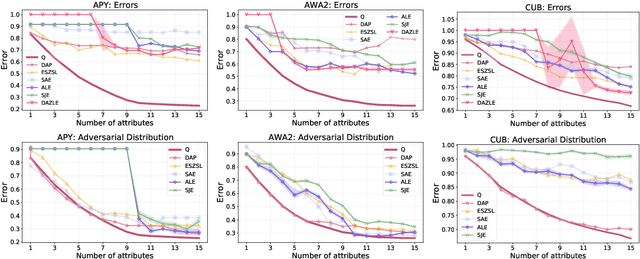
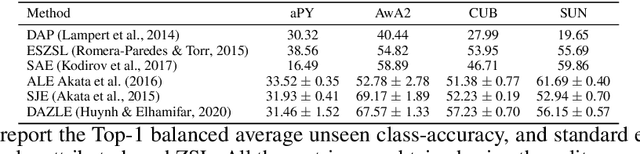
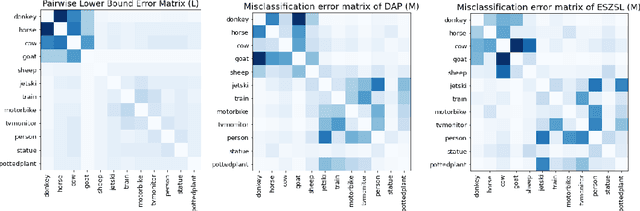
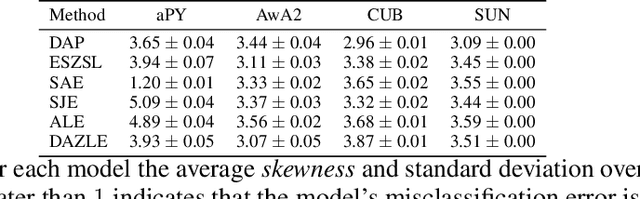
We develop a rigorous mathematical analysis of zero-shot learning with attributes. In this setting, the goal is to label novel classes with no training data, only detectors for attributes and a description of how those attributes are correlated with the target classes, called the class-attribute matrix. We develop the first non-trivial lower bound on the worst-case error of the best map from attributes to classes for this setting, even with perfect attribute detectors. The lower bound characterizes the theoretical intrinsic difficulty of the zero-shot problem based on the available information -- the class-attribute matrix -- and the bound is practically computable from it. Our lower bound is tight, as we show that we can always find a randomized map from attributes to classes whose expected error is upper bounded by the value of the lower bound. We show that our analysis can be predictive of how standard zero-shot methods behave in practice, including which classes will likely be confused with others.