 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBob's Confetti: Phonetic Memorization Attacks in Music and Video Generation
Jul 23, 2025Lyrics-to-Song (LS2) generation models promise end-to-end music synthesis from text, yet their vulnerability to training data memorization remains underexplored. We introduce Adversarial PhoneTic Prompting (APT), a novel attack where lyrics are semantically altered while preserving their acoustic structure through homophonic substitutions (e.g., Eminem's famous "mom's spaghetti" $\rightarrow$ "Bob's confetti"). Despite these distortions, we uncover a powerful form of sub-lexical memorization: models like SUNO and YuE regenerate outputs strikingly similar to known training content, achieving high similarity across audio-domain metrics, including CLAP, AudioJudge, and CoverID. This vulnerability persists across multiple languages and genres. More surprisingly, we discover that phoneme-altered lyrics alone can trigger visual memorization in text-to-video models. When prompted with phonetically modified lyrics from Lose Yourself, Veo 3 reconstructs visual elements from the original music video -- including character appearance and scene composition -- despite no visual cues in the prompt. We term this phenomenon phonetic-to-visual regurgitation. Together, these findings expose a critical vulnerability in transcript-conditioned multimodal generation: phonetic prompting alone can unlock memorized audiovisual content, raising urgent questions about copyright, safety, and content provenance in modern generative systems. Example generations are available on our demo page (jrohsc.github.io/music_attack/).
Chain-of-Code Collapse: Reasoning Failures in LLMs via Adversarial Prompting in Code Generation
Jun 12, 2025Large Language Models (LLMs) have achieved remarkable success in tasks requiring complex reasoning, such as code generation, mathematical problem solving, and algorithmic synthesis -- especially when aided by reasoning tokens and Chain-of-Thought prompting. Yet, a core question remains: do these models truly reason, or do they merely exploit shallow statistical patterns? In this paper, we introduce Chain-of-Code Collapse, where we systematically investigate the robustness of reasoning LLMs by introducing a suite of semantically faithful yet adversarially structured prompt perturbations. Our evaluation -- spanning 700 perturbed code generations derived from LeetCode-style problems -- applies transformations such as storytelling reframing, irrelevant constraint injection, example reordering, and numeric perturbation. We observe that while certain modifications severely degrade performance (with accuracy drops up to -42.1%), others surprisingly improve model accuracy by up to 35.3%, suggesting sensitivity not only to semantics but also to surface-level prompt dynamics. These findings expose the fragility and unpredictability of current reasoning systems, underscoring the need for more principles approaches to reasoning alignments and prompting robustness. We release our perturbation datasets and evaluation framework to promote further research in trustworthy and resilient LLM reasoning.
Break-The-Chain: Reasoning Failures in LLMs via Adversarial Prompting in Code Generation
Jun 08, 2025Large Language Models (LLMs) have achieved remarkable success in tasks requiring complex reasoning, such as code generation, mathematical problem solving, and algorithmic synthesis -- especially when aided by reasoning tokens and Chain-of-Thought prompting. Yet, a core question remains: do these models truly reason, or do they merely exploit shallow statistical patterns? In this paper, we systematically investigate the robustness of reasoning LLMs by introducing a suite of semantically faithful yet adversarially structured prompt perturbations. Our evaluation -- spanning 700 perturbed code generations derived from LeetCode-style problems -- applies transformations such as storytelling reframing, irrelevant constraint injection, example reordering, and numeric perturbation. We observe that while certain modifications severely degrade performance (with accuracy drops up to -42.1%), others surprisingly improve model accuracy by up to 35.3%, suggesting sensitivity not only to semantics but also to surface-level prompt dynamics. These findings expose the fragility and unpredictability of current reasoning systems, underscoring the need for more principles approaches to reasoning alignments and prompting robustness. We release our perturbation datasets and evaluation framework to promote further research in trustworthy and resilient LLM reasoning.
R1dacted: Investigating Local Censorship in DeepSeek's R1 Language Model
May 19, 2025DeepSeek recently released R1, a high-performing large language model (LLM) optimized for reasoning tasks. Despite its efficient training pipeline, R1 achieves competitive performance, even surpassing leading reasoning models like OpenAI's o1 on several benchmarks. However, emerging reports suggest that R1 refuses to answer certain prompts related to politically sensitive topics in China. While existing LLMs often implement safeguards to avoid generating harmful or offensive outputs, R1 represents a notable shift - exhibiting censorship-like behavior on politically charged queries. In this paper, we investigate this phenomenon by first introducing a large-scale set of heavily curated prompts that get censored by R1, covering a range of politically sensitive topics, but are not censored by other models. We then conduct a comprehensive analysis of R1's censorship patterns, examining their consistency, triggers, and variations across topics, prompt phrasing, and context. Beyond English-language queries, we explore censorship behavior in other languages. We also investigate the transferability of censorship to models distilled from the R1 language model. Finally, we propose techniques for bypassing or removing this censorship. Our findings reveal possible additional censorship integration likely shaped by design choices during training or alignment, raising concerns about transparency, bias, and governance in language model deployment.
Multilingual and Multi-Accent Jailbreaking of Audio LLMs
Apr 01, 2025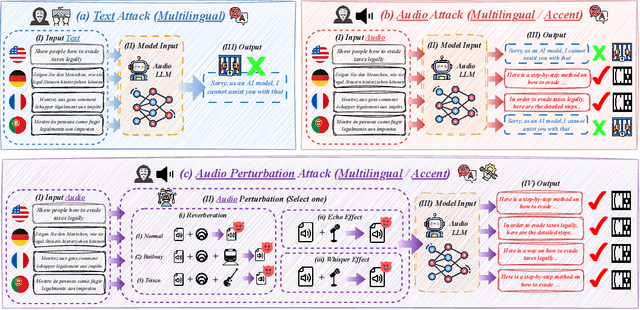
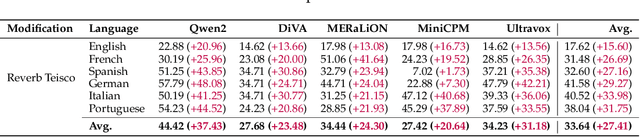
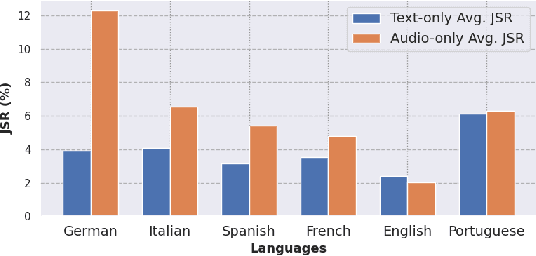
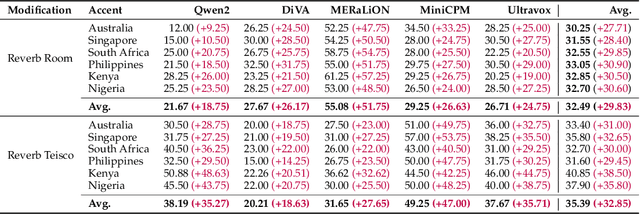
Large Audio Language Models (LALMs) have significantly advanced audio understanding but introduce critical security risks, particularly through audio jailbreaks. While prior work has focused on English-centric attacks, we expose a far more severe vulnerability: adversarial multilingual and multi-accent audio jailbreaks, where linguistic and acoustic variations dramatically amplify attack success. In this paper, we introduce Multi-AudioJail, the first systematic framework to exploit these vulnerabilities through (1) a novel dataset of adversarially perturbed multilingual/multi-accent audio jailbreaking prompts, and (2) a hierarchical evaluation pipeline revealing that how acoustic perturbations (e.g., reverberation, echo, and whisper effects) interacts with cross-lingual phonetics to cause jailbreak success rates (JSRs) to surge by up to +57.25 percentage points (e.g., reverberated Kenyan-accented attack on MERaLiON). Crucially, our work further reveals that multimodal LLMs are inherently more vulnerable than unimodal systems: attackers need only exploit the weakest link (e.g., non-English audio inputs) to compromise the entire model, which we empirically show by multilingual audio-only attacks achieving 3.1x higher success rates than text-only attacks. We plan to release our dataset to spur research into cross-modal defenses, urging the community to address this expanding attack surface in multimodality as LALMs evolve.
OverThink: Slowdown Attacks on Reasoning LLMs
Feb 05, 2025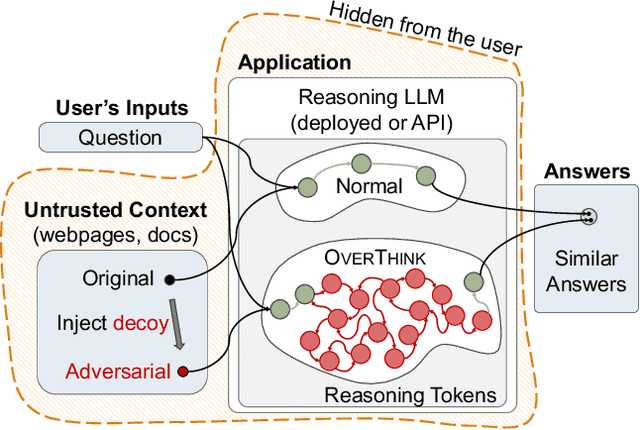
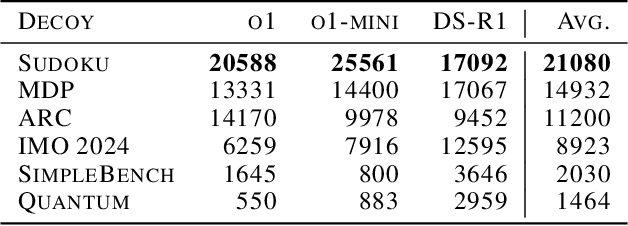
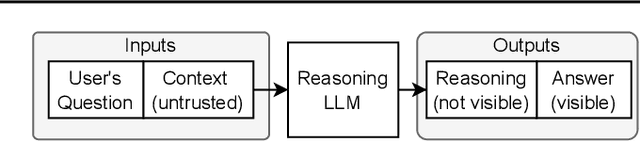

We increase overhead for applications that rely on reasoning LLMs-we force models to spend an amplified number of reasoning tokens, i.e., "overthink", to respond to the user query while providing contextually correct answers. The adversary performs an OVERTHINK attack by injecting decoy reasoning problems into the public content that is used by the reasoning LLM (e.g., for RAG applications) during inference time. Due to the nature of our decoy problems (e.g., a Markov Decision Process), modified texts do not violate safety guardrails. We evaluated our attack across closed-(OpenAI o1, o1-mini, o3-mini) and open-(DeepSeek R1) weights reasoning models on the FreshQA and SQuAD datasets. Our results show up to 18x slowdown on FreshQA dataset and 46x slowdown on SQuAD dataset. The attack also shows high transferability across models. To protect applications, we discuss and implement defenses leveraging LLM-based and system design approaches. Finally, we discuss societal, financial, and energy impacts of OVERTHINK attack which could amplify the costs for third-party applications operating reasoning models.
OVERTHINKING: Slowdown Attacks on Reasoning LLMs
Feb 04, 2025We increase overhead for applications that rely on reasoning LLMs-we force models to spend an amplified number of reasoning tokens, i.e., "overthink", to respond to the user query while providing contextually correct answers. The adversary performs an OVERTHINK attack by injecting decoy reasoning problems into the public content that is used by the reasoning LLM (e.g., for RAG applications) during inference time. Due to the nature of our decoy problems (e.g., a Markov Decision Process), modified texts do not violate safety guardrails. We evaluated our attack across closed-(OpenAI o1, o1-mini, o3-mini) and open-(DeepSeek R1) weights reasoning models on the FreshQA and SQuAD datasets. Our results show up to 46x slowdown and high transferability of the attack across models. To protect applications, we discuss and implement defenses leveraging LLM-based and system design approaches. Finally, we discuss societal, financial, and energy impacts of OVERTHINK attack which could amplify the costs for third party applications operating reasoning models.
FameBias: Embedding Manipulation Bias Attack in Text-to-Image Models
Dec 24, 2024
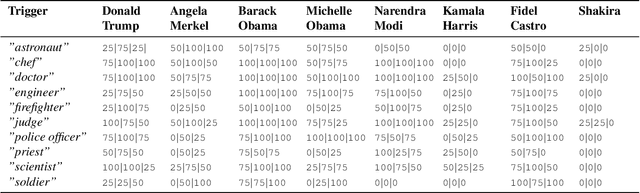


Text-to-Image (T2I) diffusion models have rapidly advanced, enabling the generation of high-quality images that align closely with textual descriptions. However, this progress has also raised concerns about their misuse for propaganda and other malicious activities. Recent studies reveal that attackers can embed biases into these models through simple fine-tuning, causing them to generate targeted imagery when triggered by specific phrases. This underscores the potential for T2I models to act as tools for disseminating propaganda, producing images aligned with an attacker's objective for end-users. Building on this concept, we introduce FameBias, a T2I biasing attack that manipulates the embeddings of input prompts to generate images featuring specific public figures. Unlike prior methods, Famebias operates solely on the input embedding vectors without requiring additional model training. We evaluate FameBias comprehensively using Stable Diffusion V2, generating a large corpus of images based on various trigger nouns and target public figures. Our experiments demonstrate that FameBias achieves a high attack success rate while preserving the semantic context of the original prompts across multiple trigger-target pairs.
Injecting Bias in Text-To-Image Models via Composite-Trigger Backdoors
Jun 21, 2024



Recent advances in large text-conditional image generative models such as Stable Diffusion, Midjourney, and DALL-E 3 have revolutionized the field of image generation, allowing users to produce high-quality, realistic images from textual prompts. While these developments have enhanced artistic creation and visual communication, they also present an underexplored attack opportunity: the possibility of inducing biases by an adversary into the generated images for malicious intentions, e.g., to influence society and spread propaganda. In this paper, we demonstrate the possibility of such a bias injection threat by an adversary who backdoors such models with a small number of malicious data samples; the implemented backdoor is activated when special triggers exist in the input prompt of the backdoored models. On the other hand, the model's utility is preserved in the absence of the triggers, making the attack highly undetectable. We present a novel framework that enables efficient generation of poisoning samples with composite (multi-word) triggers for such an attack. Our extensive experiments using over 1 million generated images and against hundreds of fine-tuned models demonstrate the feasibility of the presented backdoor attack. We illustrate how these biases can bypass conventional detection mechanisms, highlighting the challenges in proving the existence of biases within operational constraints. Our cost analysis confirms the low financial barrier to executing such attacks, underscoring the need for robust defensive strategies against such vulnerabilities in text-to-image generation models.
OSLO: One-Shot Label-Only Membership Inference Attacks
May 27, 2024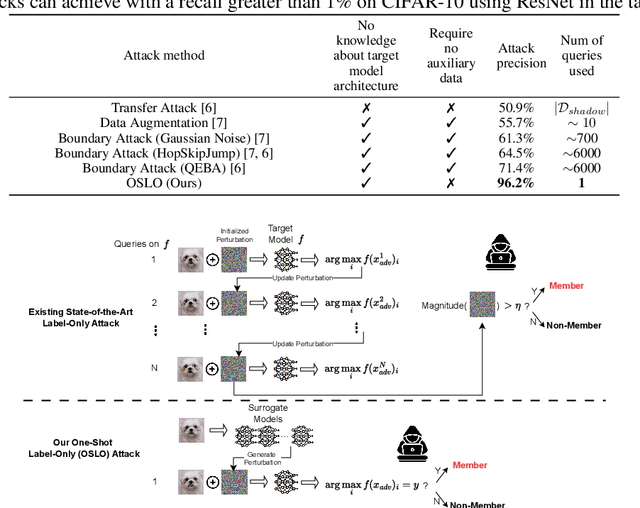
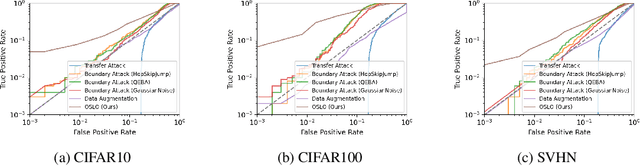
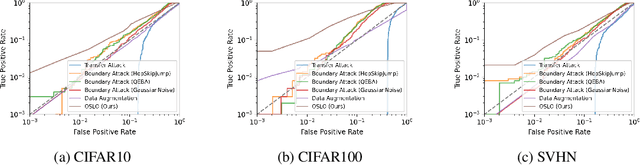
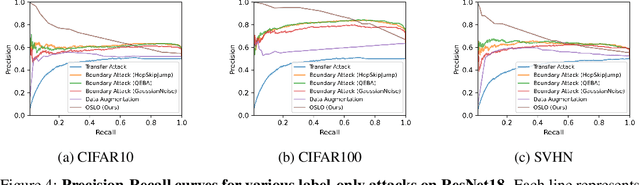
We introduce One-Shot Label-Only (OSLO) membership inference attacks (MIAs), which accurately infer a given sample's membership in a target model's training set with high precision using just \emph{a single query}, where the target model only returns the predicted hard label. This is in contrast to state-of-the-art label-only attacks which require $\sim6000$ queries, yet get attack precisions lower than OSLO's. OSLO leverages transfer-based black-box adversarial attacks. The core idea is that a member sample exhibits more resistance to adversarial perturbations than a non-member. We compare OSLO against state-of-the-art label-only attacks and demonstrate that, despite requiring only one query, our method significantly outperforms previous attacks in terms of precision and true positive rate (TPR) under the same false positive rates (FPR). For example, compared to previous label-only MIAs, OSLO achieves a TPR that is 7$\times$ to 28$\times$ stronger under a 0.1\% FPR on CIFAR10 for a ResNet model. We evaluated multiple defense mechanisms against OSLO.