 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Link Formation Prediction in Social Learning Networks Using Graph Neural Networks
Apr 20, 2026Social learning networks (SLNs) are graphical representations that capture student interactions within educational settings (e.g., a classroom), with nodes representing students and edges denoting interactions. Accurately predicting future interactions in these networks (i.e., link prediction) is crucial for enabling effective collaborative learning, supporting timely instructional interventions, and informing the design of effective group-based learning activities. However, traditional link prediction approaches are typically tuned to general online social networks (OSNs), often overlooking the complex, non-Euclidean, and dynamically evolving structure of SLNs, thus limiting their effectiveness in educational settings. In this work, we propose a graph neural network (GNN) framework that jointly considers the temporal evolution within classrooms and spatial aggregation across classrooms to perform link prediction in SLNs. Specifically, we analyze link prediction performance of GNNs over the SLNs of four distinct classrooms across their (i) temporal evolutions (varying time instances), (ii) spatial aggregations (joint SLN analysis), and (iii) varying spatial aggregations at varying temporal evolutions throughout the course. Our results indicate statistically significant performance improvements in the prediction of future links as the courses progress temporally. Aggregating SLNs from multiple classrooms generally enhances model performance as well, especially in sparser datasets. Moreover, we find that jointly leveraging both the temporal evolution and spatial aggregation of SLNs significantly outperforms conventional baseline approaches that analyze classrooms in isolation. Our findings demonstrate the efficacy of educationally meaningful link predictions, with direct implications for early-course decision-making and scalable learning analytics in and across classroom settings.
REVERB-FL: Server-Side Adversarial and Reserve-Enhanced Federated Learning for Robust Audio Classification
Dec 15, 2025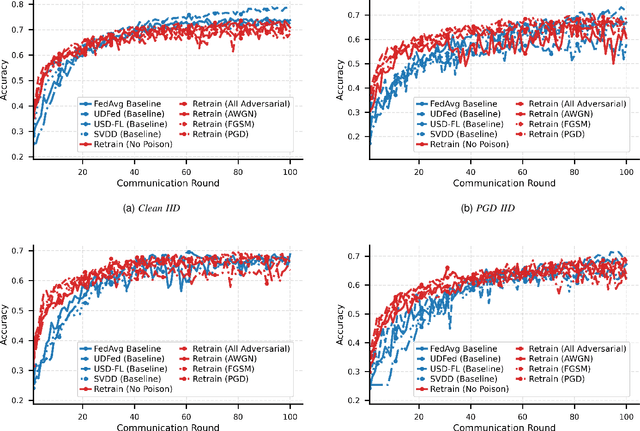
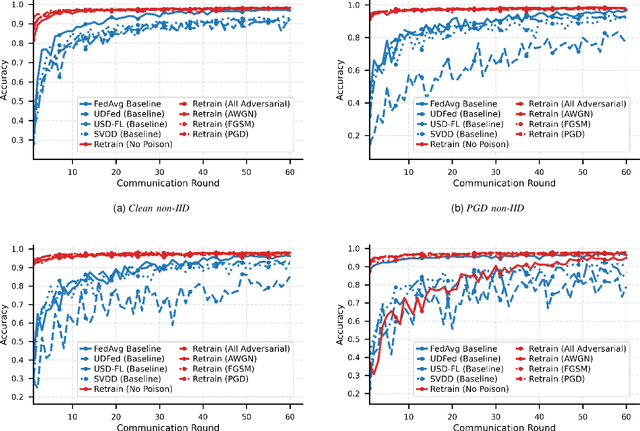
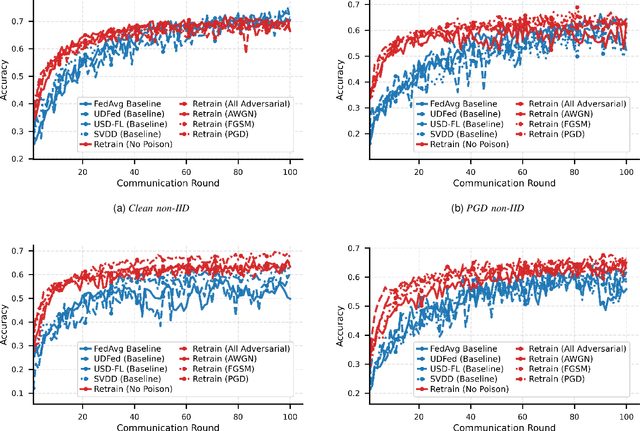
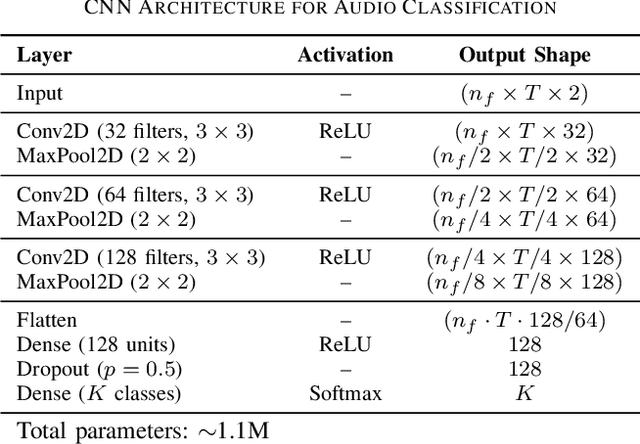
Federated learning (FL) enables a privacy-preserving training paradigm for audio classification but is highly sensitive to client heterogeneity and poisoning attacks, where adversarially compromised clients can bias the global model and hinder the performance of audio classifiers. To mitigate the effects of model poisoning for audio signal classification, we present REVERB-FL, a lightweight, server-side defense that couples a small reserve set (approximately 5%) with pre- and post-aggregation retraining and adversarial training. After each local training round, the server refines the global model on the reserve set with either clean or additional adversarially perturbed data, thereby counteracting non-IID drift and mitigating potential model poisoning without adding substantial client-side cost or altering the aggregation process. We theoretically demonstrate the feasibility of our framework, showing faster convergence and a reduced steady-state error relative to baseline federated averaging. We validate our framework on two open-source audio classification datasets with varying IID and Dirichlet non-IID partitions and demonstrate that REVERB-FL mitigates global model poisoning under multiple designs of local data poisoning.
A Speculative GLRT-Backed Approach for Adversarial Resilience on Deep Learning-Based Array Processing
Dec 10, 2025Classical array processing methods such as the generalized likelihood ratio test (GLRT) provide statistically grounded solutions for signal detection and direction-of-arrival (DoA) estimation, but their high computational cost limits their use in low-latency settings. Deep learning (DL) has recently emerged as an efficient alternative, offering fast inference for array processing tasks. However, DL models lack statistical guarantees and, moreover, are highly susceptible to adversarial perturbations, raising fundamental concerns about their reliability in adversarial wireless environments. To address these challenges, we propose an adversarially resilient speculative array processing framework that consists of a low-latency DL classifier backed by a theoretically-grounded GLRT validator, where DL is used for fast speculative inference and later confirmed with the GLRT. We show that second order statistics of the received array, which the GLRT operates on, are spatially invariant to L-p bounded adversarial perturbations, providing adversarial robustness and theoretically-grounded validation of DL predictions. Empirical evaluations under multiple L-p bounds, perturbation designs, and perturbation magnitudes corroborate our theoretical findings, demonstrating the superior performance of our proposed framework in comparison to multiple state-of-the-art baselines.
Bringing Multi-Modal Multi-Task Federated Foundation Models to Education Domain: Prospects and Challenges
Sep 09, 2025Multi-modal multi-task (M3T) foundation models (FMs) have recently shown transformative potential in artificial intelligence, with emerging applications in education. However, their deployment in real-world educational settings is hindered by privacy regulations, data silos, and limited domain-specific data availability. We introduce M3T Federated Foundation Models (FedFMs) for education: a paradigm that integrates federated learning (FL) with M3T FMs to enable collaborative, privacy-preserving training across decentralized institutions while accommodating diverse modalities and tasks. Subsequently, this position paper aims to unveil M3T FedFMs as a promising yet underexplored approach to the education community, explore its potentials, and reveal its related future research directions. We outline how M3T FedFMs can advance three critical pillars of next-generation intelligent education systems: (i) privacy preservation, by keeping sensitive multi-modal student and institutional data local; (ii) personalization, through modular architectures enabling tailored models for students, instructors, and institutions; and (iii) equity and inclusivity, by facilitating participation from underrepresented and resource-constrained entities. We finally identify various open research challenges, including studying of (i) inter-institution heterogeneous privacy regulations, (ii) the non-uniformity of data modalities' characteristics, (iii) the unlearning approaches for M3T FedFMs, (iv) the continual learning frameworks for M3T FedFMs, and (v) M3T FedFM model interpretability, which must be collectively addressed for practical deployment.
FLAME: A Federated Learning Approach for Multi-Modal RF Fingerprinting
Mar 06, 2025Authorization systems are increasingly relying on processing radio frequency (RF) waveforms at receivers to fingerprint (i.e., determine the identity) of the corresponding transmitter. Federated learning (FL) has emerged as a popular paradigm to perform RF fingerprinting in networks with multiple access points (APs), as they allow effective deep learning-based device identification without requiring the centralization of locally collected RF signals stored at multiple APs. Yet, FL algorithms that operate merely on in-phase and quadrature (IQ) time samples incur high convergence rates, resulting in excessive training rounds and inefficient training times. In this work, we propose FLAME: an FL approach for multimodal RF fingerprinting. Our framework consists of simultaneously representing received RF waveforms in multiple complimentary modalities beyond IQ samples in an effort to reduce training times. We theoretically demonstrate the feasibility and efficiency of our methodology and derive a convergence bound that incurs lower loss and thus higher accuracies in the same training round in comparison to single-modal FL-based RF fingerprinting. Extensive empirical evaluations validate our theoretical results and demonstrate the superiority of FLAME with with improvements of up to 30% in comparison to multiple considered baselines.
An Uncertainty Quantification Framework for Deep Learning-Based Automatic Modulation Classification
Mar 06, 2025
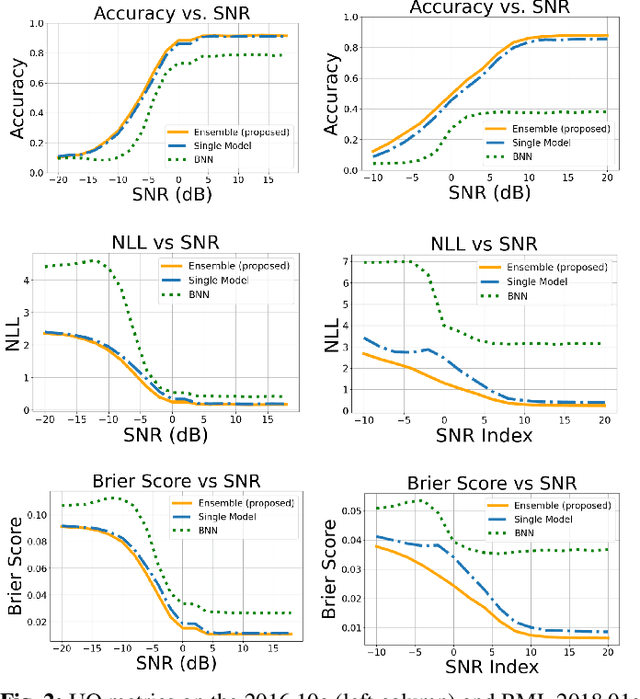
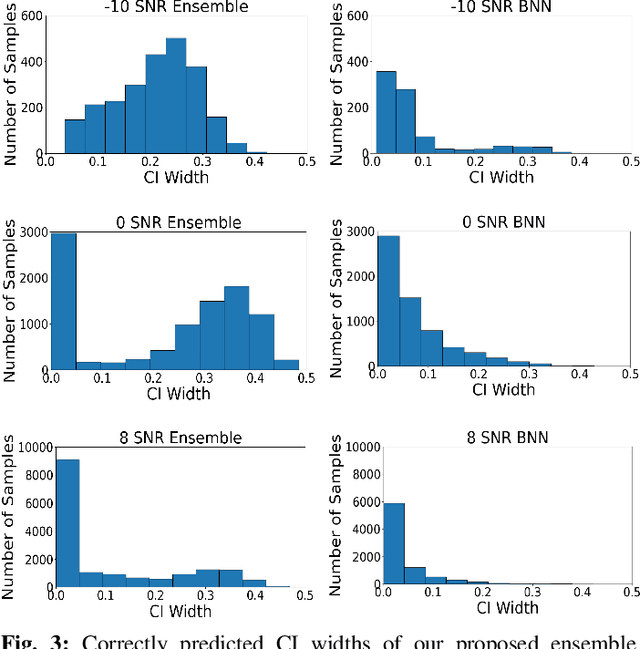
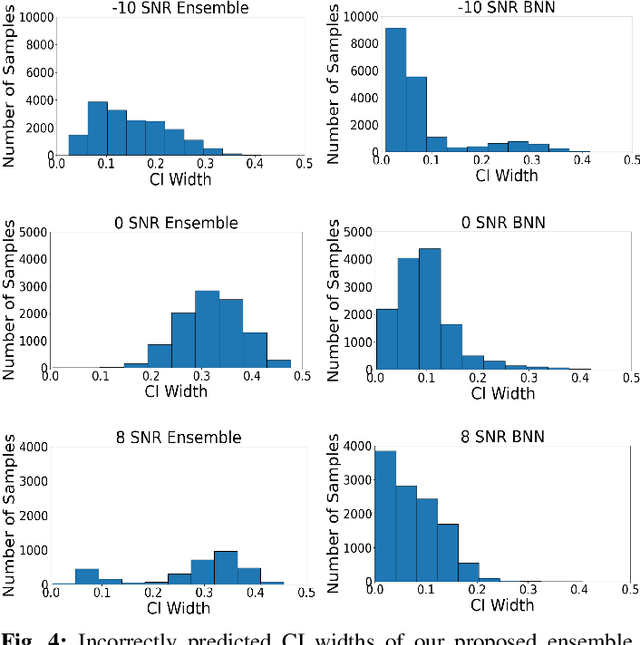
Deep learning has been shown to be highly effective for automatic modification classification (AMC), which is a pivotal technology for next-generation cognitive communications. Yet, existing deep learning methods for AMC often lack robust mechanisms for uncertainty quantification (UQ). This limitation restricts their ability to produce accurate and reliable predictions in real-world environments, where signals can be perturbed as a result of several factors such as interference and low signal-to-noise ratios (SNR). To address this problem, we propose a deep ensemble approach that leverages multiple convolutional neural networks (CNNs) to generate predictive distributions, as opposed to point estimates produced by standard deep learning models, which produce statistical characteristics that quantify the uncertainty associated with each prediction. We validate our approach using real-world AMC data, evaluating performance through multiple UQ metrics in a variety of signal environments. Our results show that our proposed ensemble-based framework captures uncertainty to a greater degree compared to previously proposed baselines in multiple settings, including in-distribution samples, out-of-distribution samples, and low SNR signals. These findings highlight the strong UQ capabilities of our ensemble-based AMC approach, paving the way for more robust deep learning-based AMC.
Robust Eavesdropping in the Presence of Adversarial Communications for RF Fingerprinting
Mar 06, 2025Deep learning is an effective approach for performing radio frequency (RF) fingerprinting, which aims to identify the transmitter corresponding to received RF signals. However, beyond the intended receiver, malicious eavesdroppers can also intercept signals and attempt to fingerprint transmitters communicating over a wireless channel. Recent studies suggest that transmitters can counter such threats by embedding deep learning-based transferable adversarial attacks in their signals before transmission. In this work, we develop a time-frequency-based eavesdropper architecture that is capable of withstanding such transferable adversarial perturbations and thus able to perform effective RF fingerprinting. We theoretically demonstrate that adversarial perturbations injected by a transmitter are confined to specific time-frequency regions that are insignificant during inference, directly increasing fingerprinting accuracy on perturbed signals intercepted by the eavesdropper. Empirical evaluations on a real-world dataset validate our theoretical findings, showing that deep learning-based RF fingerprinting eavesdroppers can achieve classification performance comparable to the intended receiver, despite efforts made by the transmitter to deceive the eavesdropper. Our framework reveals that relying on transferable adversarial attacks may not be sufficient to prevent eavesdroppers from successfully fingerprinting transmissions in next-generation deep learning-based communications systems.
The Transition from Centralized Machine Learning to Federated Learning for Mental Health in Education: A Survey of Current Methods and Future Directions
Jan 20, 2025



Research has increasingly explored the application of artificial intelligence (AI) and machine learning (ML) within the mental health domain to enhance both patient care and healthcare provider efficiency. Given that mental health challenges frequently emerge during early adolescence -- the critical years of high school and college -- investigating AI/ML-driven mental health solutions within the education domain is of paramount importance. Nevertheless, conventional AI/ML techniques follow a centralized model training architecture, which poses privacy risks due to the need for transferring students' sensitive data from institutions, universities, and clinics to central servers. Federated learning (FL) has emerged as a solution to address these risks by enabling distributed model training while maintaining data privacy. Despite its potential, research on applying FL to analyze students' mental health remains limited. In this paper, we aim to address this limitation by proposing a roadmap for integrating FL into mental health data analysis within educational settings. We begin by providing an overview of mental health issues among students and reviewing existing studies where ML has been applied to address these challenges. Next, we examine broader applications of FL in the mental health domain to emphasize the lack of focus on educational contexts. Finally, we propose promising research directions focused on using FL to address mental health issues in the education sector, which entails discussing the synergies between the proposed directions with broader human-centered domains. By categorizing the proposed research directions into short- and long-term strategies and highlighting the unique challenges at each stage, we aim to encourage the development of privacy-conscious AI/ML-driven mental health solutions.
Mitigating Evasion Attacks in Federated Learning-Based Signal Classifiers
Jun 08, 2023There has been recent interest in leveraging federated learning (FL) for radio signal classification tasks. In FL, model parameters are periodically communicated from participating devices, which train on local datasets, to a central server which aggregates them into a global model. While FL has privacy/security advantages due to raw data not leaving the devices, it is still susceptible to adversarial attacks. In this work, we first reveal the susceptibility of FL-based signal classifiers to model poisoning attacks, which compromise the training process despite not observing data transmissions. In this capacity, we develop an attack framework that significantly degrades the training process of the global model. Our attack framework induces a more potent model poisoning attack to the global classifier than existing baselines while also being able to compromise existing server-driven defenses. In response to this gap, we develop Underlying Server Defense of Federated Learning (USD-FL), a novel defense methodology for FL-based signal classifiers. We subsequently compare the defensive efficacy, runtimes, and false positive detection rates of USD-FL relative to existing server-driven defenses, showing that USD-FL has notable advantages over the baseline defenses in all three areas.
How Potent are Evasion Attacks for Poisoning Federated Learning-Based Signal Classifiers?
Jan 21, 2023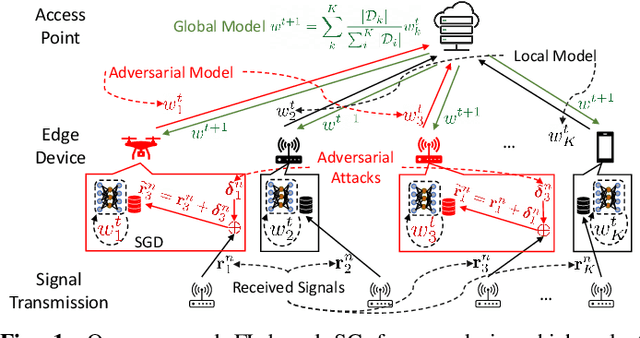
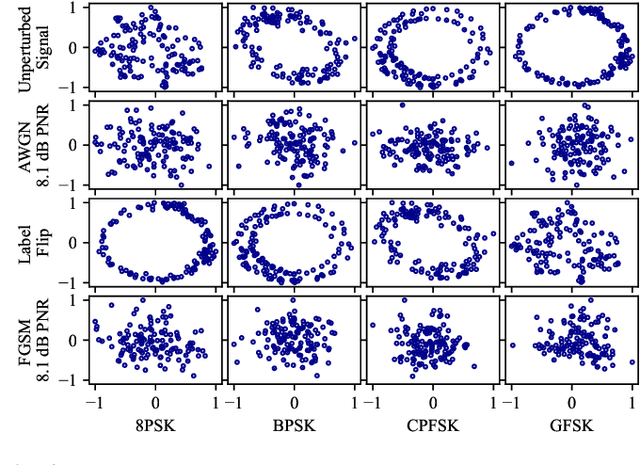
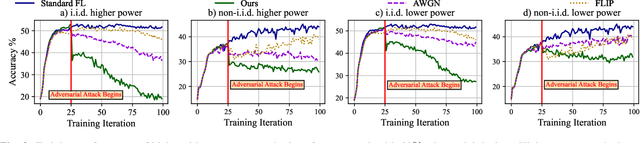
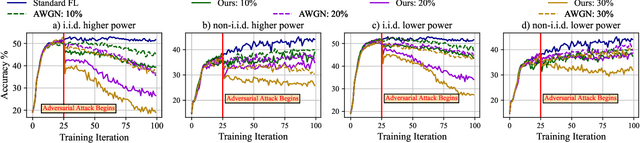
There has been recent interest in leveraging federated learning (FL) for radio signal classification tasks. In FL, model parameters are periodically communicated from participating devices, training on their own local datasets, to a central server which aggregates them into a global model. While FL has privacy/security advantages due to raw data not leaving the devices, it is still susceptible to several adversarial attacks. In this work, we reveal the susceptibility of FL-based signal classifiers to model poisoning attacks, which compromise the training process despite not observing data transmissions. In this capacity, we develop an attack framework in which compromised FL devices perturb their local datasets using adversarial evasion attacks. As a result, the training process of the global model significantly degrades on in-distribution signals (i.e., signals received over channels with identical distributions at each edge device). We compare our work to previously proposed FL attacks and reveal that as few as one adversarial device operating with a low-powered perturbation under our attack framework can induce the potent model poisoning attack to the global classifier. Moreover, we find that more devices partaking in adversarial poisoning will proportionally degrade the classification performance.