 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAS: Blockchain Enabled Asynchronous & Secure Federated Machine Learning
Feb 06, 2022



Federated Learning (FL) enables multiple parties to distributively train a ML model without revealing their private datasets. However, it assumes trust in the centralized aggregator which stores and aggregates model updates. This makes it prone to gradient tampering and privacy leakage by a malicious aggregator. Malicious parties can also introduce backdoors into the joint model by poisoning the training data or model gradients. To address these issues, we present BEAS, the first blockchain-based framework for N-party FL that provides strict privacy guarantees of training data using gradient pruning (showing improved differential privacy compared to existing noise and clipping based techniques). Anomaly detection protocols are used to minimize the risk of data-poisoning attacks, along with gradient pruning that is further used to limit the efficacy of model-poisoning attacks. We also define a novel protocol to prevent premature convergence in heterogeneous learning environments. We perform extensive experiments on multiple datasets with promising results: BEAS successfully prevents privacy leakage from dataset reconstruction attacks, and minimizes the efficacy of poisoning attacks. Moreover, it achieves an accuracy similar to centralized frameworks, and its communication and computation overheads scale linearly with the number of participants.
Scotch: An Efficient Secure Computation Framework for Secure Aggregation
Jan 19, 2022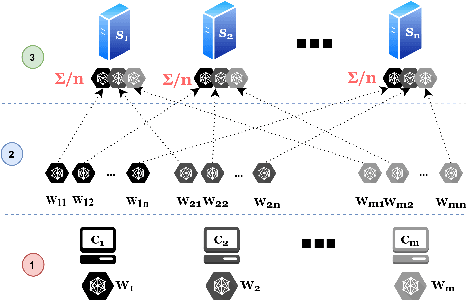


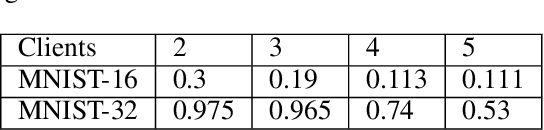
Federated learning enables multiple data owners to jointly train a machine learning model without revealing their private datasets. However, a malicious aggregation server might use the model parameters to derive sensitive information about the training dataset used. To address such leakage, differential privacy and cryptographic techniques have been investigated in prior work, but these often result in large communication overheads or impact model performance. To mitigate this centralization of power, we propose \textsc{Scotch}, a decentralized \textit{m-party} secure-computation framework for federated aggregation that deploys MPC primitives, such as \textit{secret sharing}. Our protocol is simple, efficient, and provides strict privacy guarantees against curious aggregators or colluding data-owners with minimal communication overheads compared to other existing \textit{state-of-the-art} privacy-preserving federated learning frameworks. We evaluate our framework by performing extensive experiments on multiple datasets with promising results. \textsc{Scotch} can train the standard MLP NN with the training dataset split amongst 3 participating users and 3 aggregating servers with 96.57\% accuracy on MNIST, and 98.40\% accuracy on the Extended MNIST (digits) dataset, while providing various optimizations.