 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomly Sampled Language Reasoning Problems Reveal Limits of LLMs
Jan 07, 2025



Can LLMs pick up language structure from examples? Evidence in prior work seems to indicate yes, as pretrained models repeatedly demonstrate the ability to adapt to new language structures and vocabularies. However, this line of research typically considers languages that are present within common pretraining datasets, or otherwise share notable similarities with these seen languages. In contrast, in this work we attempt to measure models' language understanding capacity while circumventing the risk of dataset recall. We parameterize large families of language tasks recognized by deterministic finite automata (DFAs), and can thus sample novel language reasoning problems to fairly evaulate LLMs regardless of training data. We find that, even in the strikingly simple setting of 3-state DFAs, LLMs underperform unparameterized ngram models on both language recognition and synthesis tasks. These results suggest that LLMs struggle to match the ability of basic language models in recognizing and reasoning over languages that are sufficiently distinct from the ones they see at training time, underscoring the distinction between learning individual languages and possessing a general theory of language.
SPARLING: Learning Latent Representations with Extremely Sparse Activations
Feb 03, 2023Real-world processes often contain intermediate state that can be modeled as an extremely sparse tensor. We introduce Sparling, a new kind of informational bottleneck that explicitly models this state by enforcing extreme activation sparsity. We additionally demonstrate that this technique can be used to learn the true intermediate representation with no additional supervision (i.e., from only end-to-end labeled examples), and thus improve the interpretability of the resulting models. On our DigitCircle domain, we are able to get an intermediate state prediction accuracy of 98.84%, even as we only train end-to-end.
Synthesize, Execute and Debug: Learning to Repair for Neural Program Synthesis
Jul 16, 2020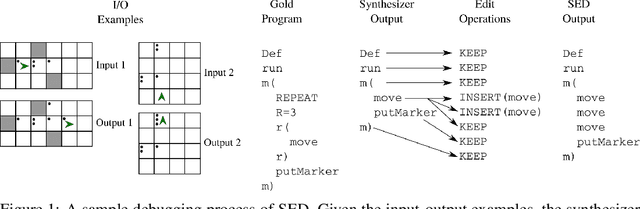

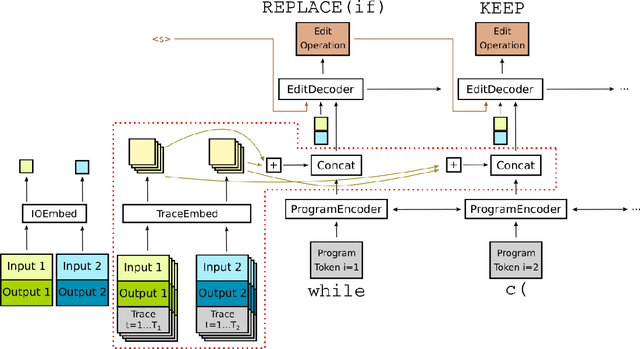
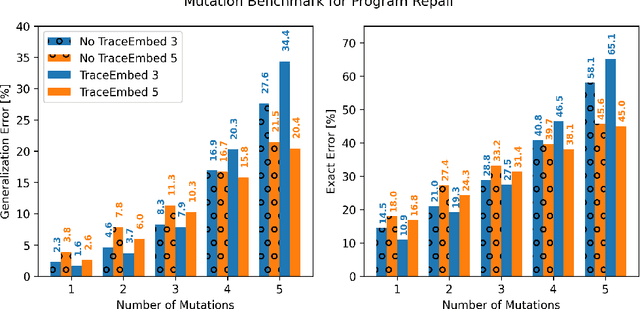
The use of deep learning techniques has achieved significant progress for program synthesis from input-output examples. However, when the program semantics become more complex, it still remains a challenge to synthesize programs consistent with the specification. In this work, we propose SED, a neural program generation framework that incorporates synthesis, execution, and debugging stages. Instead of purely relying on the neural program synthesizer to generate the final program, SED first produces initial programs using the neural program synthesizer component, then utilizes a neural program debugger to iteratively repair the generated programs. The integration of the debugger component enables SED to modify the programs based on the execution results and specification, which resembles the coding process of human programmers. On Karel, a challenging input-output program synthesis benchmark, SED reduces the error rate of the neural program synthesizer itself by at least 7.5%, and outperforms the standard beam search for decoding.
Synthetic Datasets for Neural Program Synthesis
Dec 27, 2019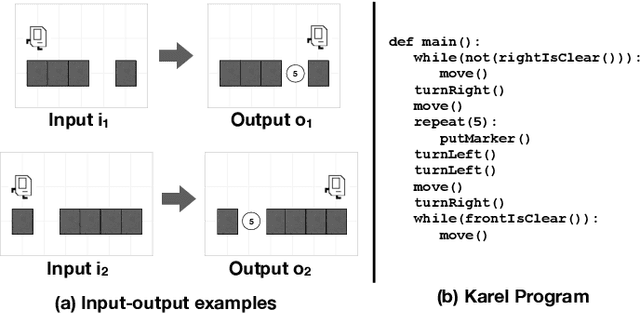



The goal of program synthesis is to automatically generate programs in a particular language from corresponding specifications, e.g. input-output behavior. Many current approaches achieve impressive results after training on randomly generated I/O examples in limited domain-specific languages (DSLs), as with string transformations in RobustFill. However, we empirically discover that applying test input generation techniques for languages with control flow and rich input space causes deep networks to generalize poorly to certain data distributions; to correct this, we propose a new methodology for controlling and evaluating the bias of synthetic data distributions over both programs and specifications. We demonstrate, using the Karel DSL and a small Calculator DSL, that training deep networks on these distributions leads to improved cross-distribution generalization performance.