 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Text Classification With Large Pre-Trained Language Models
Dec 04, 2018


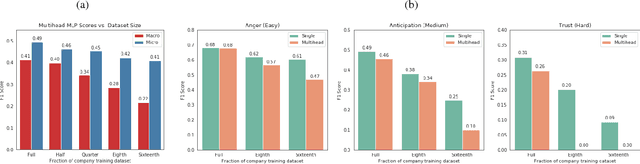
Multi-emotion sentiment classification is a natural language processing (NLP) problem with valuable use cases on real-world data. We demonstrate that large-scale unsupervised language modeling combined with finetuning offers a practical solution to this task on difficult datasets, including those with label class imbalance and domain-specific context. By training an attention-based Transformer network (Vaswani et al. 2017) on 40GB of text (Amazon reviews) (McAuley et al. 2015) and fine-tuning on the training set, our model achieves a 0.69 F1 score on the SemEval Task 1:E-c multi-dimensional emotion classification problem (Mohammad et al. 2018), based on the Plutchik wheel of emotions (Plutchik 1979). These results are competitive with state of the art models, including strong F1 scores on difficult (emotion) categories such as Fear (0.73), Disgust (0.77) and Anger (0.78), as well as competitive results on rare categories such as Anticipation (0.42) and Surprise (0.37). Furthermore, we demonstrate our application on a real world text classification task. We create a narrowly collected text dataset of real tweets on several topics, and show that our finetuned model outperforms general purpose commercially available APIs for sentiment and multidimensional emotion classification on this dataset by a significant margin. We also perform a variety of additional studies, investigating properties of deep learning architectures, datasets and algorithms for achieving practical multidimensional sentiment classification. Overall, we find that unsupervised language modeling and finetuning is a simple framework for achieving high quality results on real-world sentiment classification.
Large Scale Language Modeling: Converging on 40GB of Text in Four Hours
Aug 11, 2018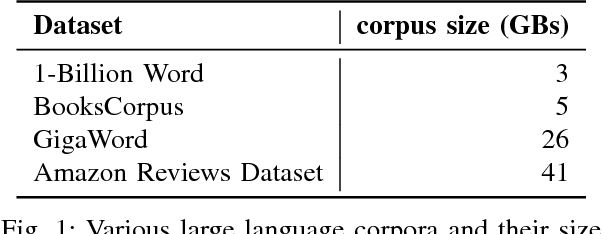
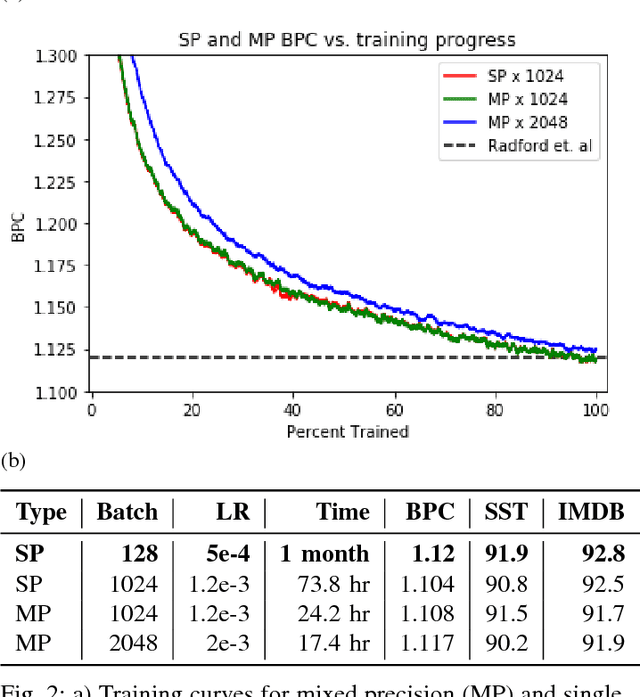
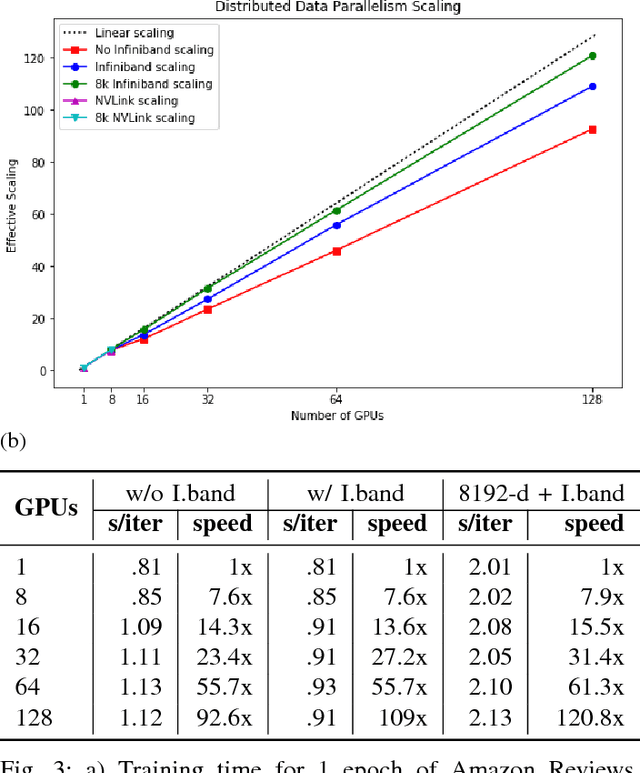
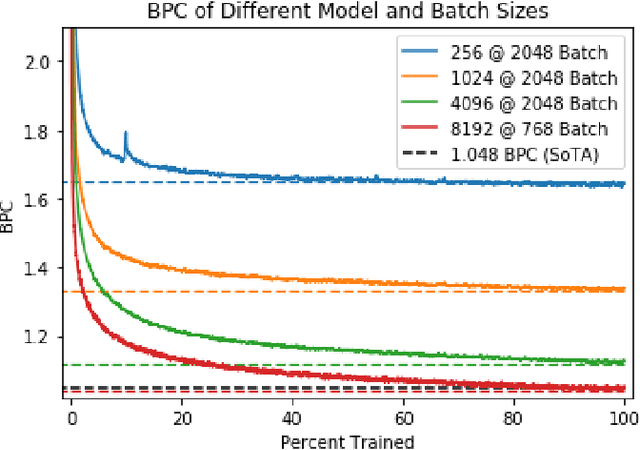
Recent work has shown how to train Convolutional Neural Networks (CNNs) rapidly on large image datasets, then transfer the knowledge gained from these models to a variety of tasks. Following [Radford 2017], in this work, we demonstrate similar scalability and transfer for Recurrent Neural Networks (RNNs) for Natural Language tasks. By utilizing mixed precision arithmetic and a 32k batch size distributed across 128 NVIDIA Tesla V100 GPUs, we are able to train a character-level 4096-dimension multiplicative LSTM (mLSTM) for unsupervised text reconstruction over 3 epochs of the 40 GB Amazon Reviews dataset in four hours. This runtime compares favorably with previous work taking one month to train the same size and configuration for one epoch over the same dataset. Converging large batch RNN models can be challenging. Recent work has suggested scaling the learning rate as a function of batch size, but we find that simply scaling the learning rate as a function of batch size leads either to significantly worse convergence or immediate divergence for this problem. We provide a learning rate schedule that allows our model to converge with a 32k batch size. Since our model converges over the Amazon Reviews dataset in hours, and our compute requirement of 128 Tesla V100 GPUs, while substantial, is commercially available, this work opens up large scale unsupervised NLP training to most commercial applications and deep learning researchers. A model can be trained over most public or private text datasets overnight.
Poker-CNN: A Pattern Learning Strategy for Making Draws and Bets in Poker Games
Sep 22, 2015
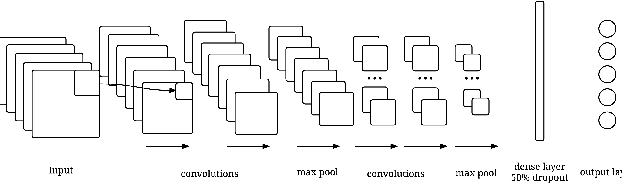
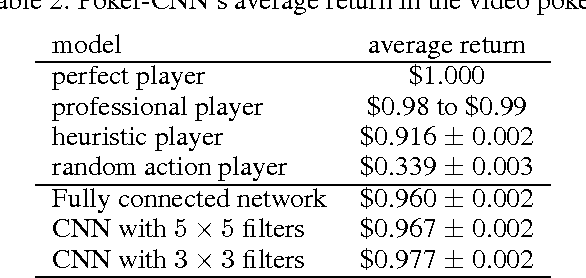
Poker is a family of card games that includes many variations. We hypothesize that most poker games can be solved as a pattern matching problem, and propose creating a strong poker playing system based on a unified poker representation. Our poker player learns through iterative self-play, and improves its understanding of the game by training on the results of its previous actions without sophisticated domain knowledge. We evaluate our system on three poker games: single player video poker, two-player Limit Texas Hold'em, and finally two-player 2-7 triple draw poker. We show that our model can quickly learn patterns in these very different poker games while it improves from zero knowledge to a competitive player against human experts. The contributions of this paper include: (1) a novel representation for poker games, extendable to different poker variations, (2) a CNN based learning model that can effectively learn the patterns in three different games, and (3) a self-trained system that significantly beats the heuristic-based program on which it is trained, and our system is competitive against human expert players.