 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Sentiment Analysis via Pre-trained Features from End-to-end ASR Models
Nov 21, 2019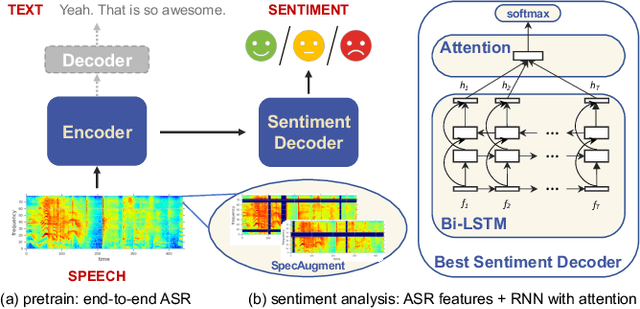

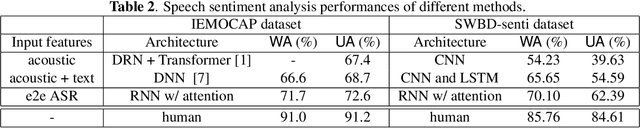

In this paper, we propose to use pre-trained features from end-to-end ASR models to solve the speech sentiment analysis problem as a down-stream task. We show that end-to-end ASR features, which integrate both acoustic and text information from speech, achieve promising results. We use RNN with self-attention as the sentiment classifier, which also provides an easy visualization through attention weights to help interpret model predictions. We use well benchmarked IEMOCAP dataset and a new large-scale sentiment analysis dataset SWBD-senti for evaluation. Our approach improves the-state-of-the-art accuracy on IEMOCAP from 66.6% to 71.7%, and achieves an accuracy of 70.10% on SWBD-senti with more than 49,500 utterances.
Poker-CNN: A Pattern Learning Strategy for Making Draws and Bets in Poker Games
Sep 22, 2015
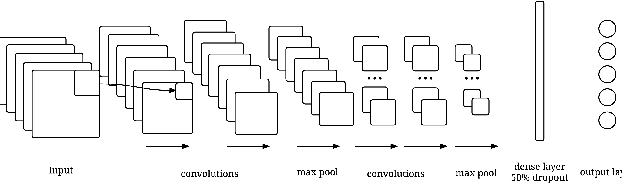
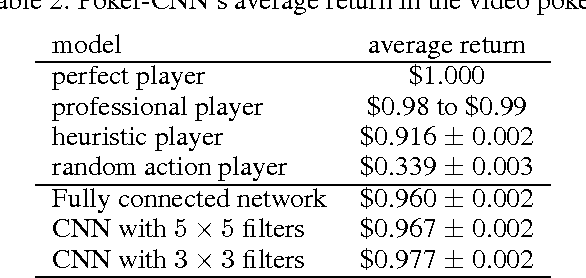
Poker is a family of card games that includes many variations. We hypothesize that most poker games can be solved as a pattern matching problem, and propose creating a strong poker playing system based on a unified poker representation. Our poker player learns through iterative self-play, and improves its understanding of the game by training on the results of its previous actions without sophisticated domain knowledge. We evaluate our system on three poker games: single player video poker, two-player Limit Texas Hold'em, and finally two-player 2-7 triple draw poker. We show that our model can quickly learn patterns in these very different poker games while it improves from zero knowledge to a competitive player against human experts. The contributions of this paper include: (1) a novel representation for poker games, extendable to different poker variations, (2) a CNN based learning model that can effectively learn the patterns in three different games, and (3) a self-trained system that significantly beats the heuristic-based program on which it is trained, and our system is competitive against human expert players.
Analysis of Watson's Strategies for Playing Jeopardy!
Feb 04, 2014



Major advances in Question Answering technology were needed for IBM Watson to play Jeopardy! at championship level -- the show requires rapid-fire answers to challenging natural language questions, broad general knowledge, high precision, and accurate confidence estimates. In addition, Jeopardy! features four types of decision making carrying great strategic importance: (1) Daily Double wagering; (2) Final Jeopardy wagering; (3) selecting the next square when in control of the board; (4) deciding whether to attempt to answer, i.e., "buzz in." Using sophisticated strategies for these decisions, that properly account for the game state and future event probabilities, can significantly boost a players overall chances to win, when compared with simple "rule of thumb" strategies. This article presents our approach to developing Watsons game-playing strategies, comprising development of a faithful simulation model, and then using learning and Monte-Carlo methods within the simulator to optimize Watsons strategic decision-making. After giving a detailed description of each of our game-strategy algorithms, we then focus in particular on validating the accuracy of the simulators predictions, and documenting performance improvements using our methods. Quantitative performance benefits are shown with respect to both simple heuristic strategies, and actual human contestant performance in historical episodes. We further extend our analysis of human play to derive a number of valuable and counterintuitive examples illustrating how human contestants may improve their performance on the show.