Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Sentiment Analysis via Pre-trained Features from End-to-end ASR Models
Paper and Code
Nov 21, 2019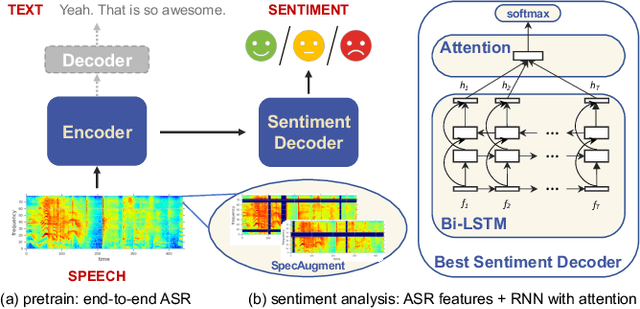

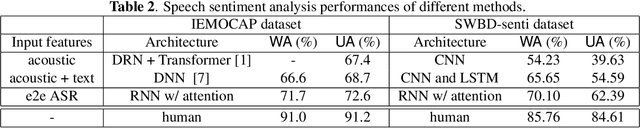

In this paper, we propose to use pre-trained features from end-to-end ASR models to solve the speech sentiment analysis problem as a down-stream task. We show that end-to-end ASR features, which integrate both acoustic and text information from speech, achieve promising results. We use RNN with self-attention as the sentiment classifier, which also provides an easy visualization through attention weights to help interpret model predictions. We use well benchmarked IEMOCAP dataset and a new large-scale sentiment analysis dataset SWBD-senti for evaluation. Our approach improves the-state-of-the-art accuracy on IEMOCAP from 66.6% to 71.7%, and achieves an accuracy of 70.10% on SWBD-senti with more than 49,500 utterances.
View paper on