 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Language Modeling: Converging on 40GB of Text in Four Hours
Paper and Code
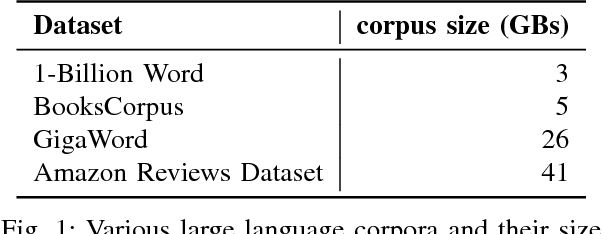
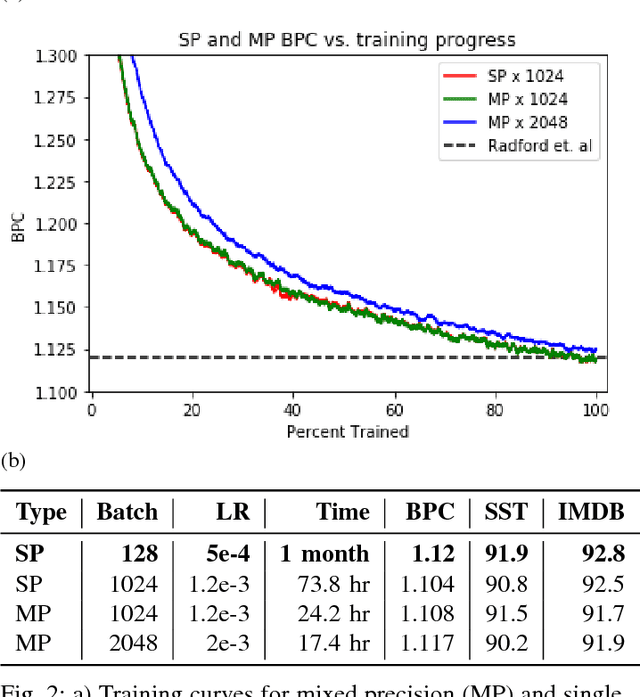
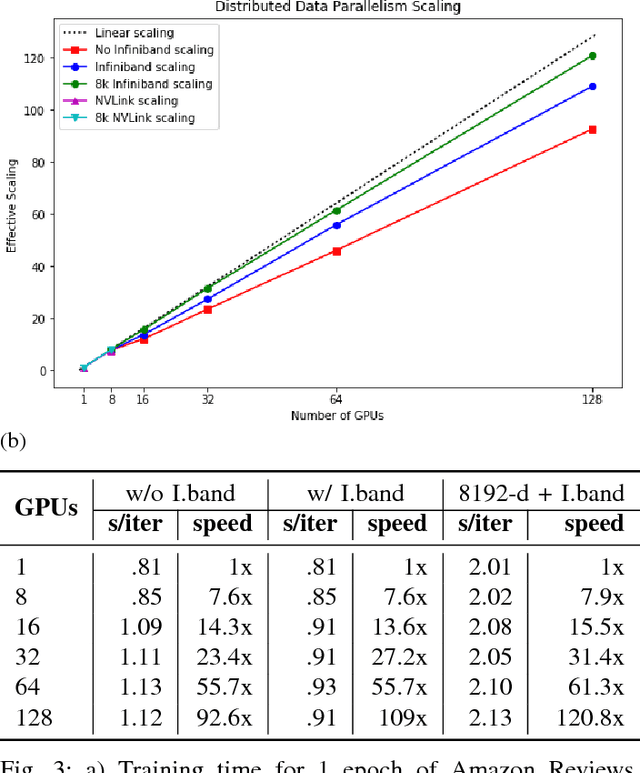
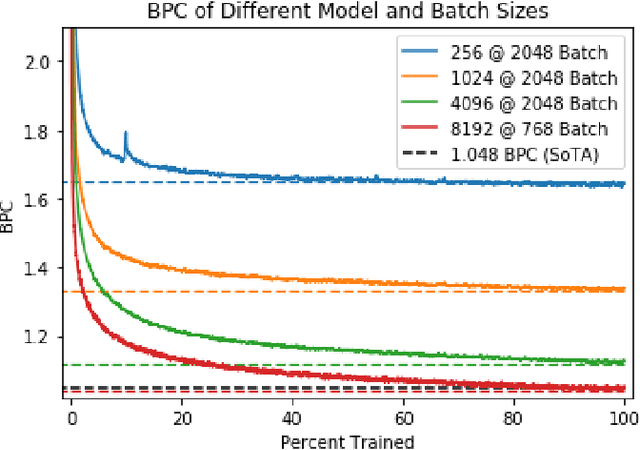
Recent work has shown how to train Convolutional Neural Networks (CNNs) rapidly on large image datasets, then transfer the knowledge gained from these models to a variety of tasks. Following [Radford 2017], in this work, we demonstrate similar scalability and transfer for Recurrent Neural Networks (RNNs) for Natural Language tasks. By utilizing mixed precision arithmetic and a 32k batch size distributed across 128 NVIDIA Tesla V100 GPUs, we are able to train a character-level 4096-dimension multiplicative LSTM (mLSTM) for unsupervised text reconstruction over 3 epochs of the 40 GB Amazon Reviews dataset in four hours. This runtime compares favorably with previous work taking one month to train the same size and configuration for one epoch over the same dataset. Converging large batch RNN models can be challenging. Recent work has suggested scaling the learning rate as a function of batch size, but we find that simply scaling the learning rate as a function of batch size leads either to significantly worse convergence or immediate divergence for this problem. We provide a learning rate schedule that allows our model to converge with a 32k batch size. Since our model converges over the Amazon Reviews dataset in hours, and our compute requirement of 128 Tesla V100 GPUs, while substantial, is commercially available, this work opens up large scale unsupervised NLP training to most commercial applications and deep learning researchers. A model can be trained over most public or private text datasets overnight.