 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Local Gradients at the Edge
Paper and Code
Aug 17, 2022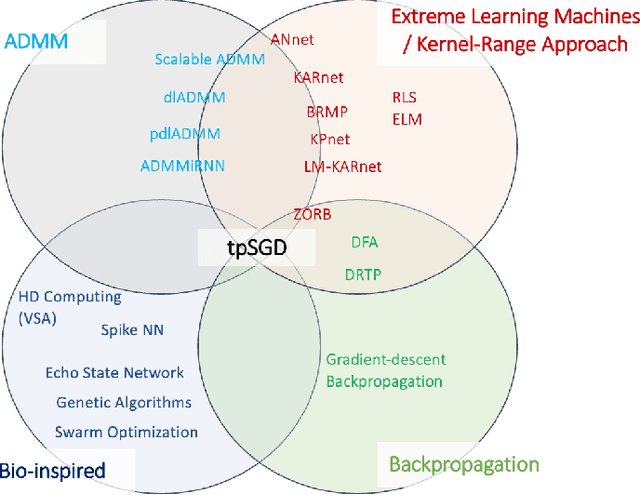
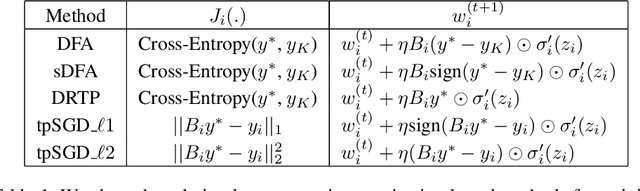
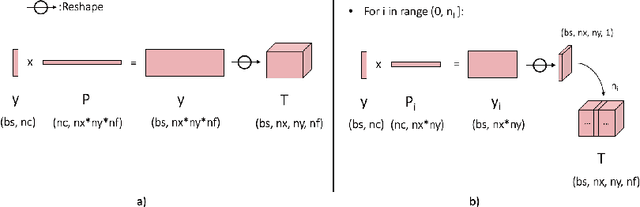

To enable learning on edge devices with fast convergence and low memory, we present a novel backpropagation-free optimization algorithm dubbed Target Projection Stochastic Gradient Descent (tpSGD). tpSGD generalizes direct random target projection to work with arbitrary loss functions and extends target projection for training recurrent neural networks (RNNs) in addition to feedforward networks. tpSGD uses layer-wise stochastic gradient descent (SGD) and local targets generated via random projections of the labels to train the network layer-by-layer with only forward passes. tpSGD doesn't require retaining gradients during optimization, greatly reducing memory allocation compared to SGD backpropagation (BP) methods that require multiple instances of the entire neural network weights, input/output, and intermediate results. Our method performs comparably to BP gradient-descent within 5% accuracy on relatively shallow networks of fully connected layers, convolutional layers, and recurrent layers. tpSGD also outperforms other state-of-the-art gradient-free algorithms in shallow models consisting of multi-layer perceptrons, convolutional neural networks (CNNs), and RNNs with competitive accuracy and less memory and time. We evaluate the performance of tpSGD in training deep neural networks (e.g. VGG) and extend the approach to multi-layer RNNs. These experiments highlight new research directions related to optimized layer-based adaptor training for domain-shift using tpSGD at the edge.