 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Dataset Generation for Adversarial Machine Learning Research
Jul 21, 2022
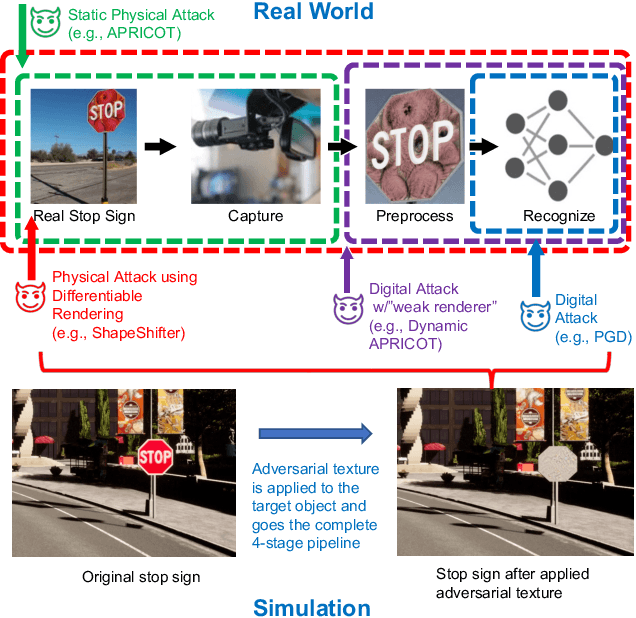


Existing adversarial example research focuses on digitally inserted perturbations on top of existing natural image datasets. This construction of adversarial examples is not realistic because it may be difficult, or even impossible, for an attacker to deploy such an attack in the real-world due to sensing and environmental effects. To better understand adversarial examples against cyber-physical systems, we propose approximating the real-world through simulation. In this paper we describe our synthetic dataset generation tool that enables scalable collection of such a synthetic dataset with realistic adversarial examples. We use the CARLA simulator to collect such a dataset and demonstrate simulated attacks that undergo the same environmental transforms and processing as real-world images. Our tools have been used to collect datasets to help evaluate the efficacy of adversarial examples, and can be found at https://github.com/carla-simulator/carla/pull/4992.
Adversarial Attack Attribution: Discovering Attributable Signals in Adversarial ML Attacks
Jan 08, 2021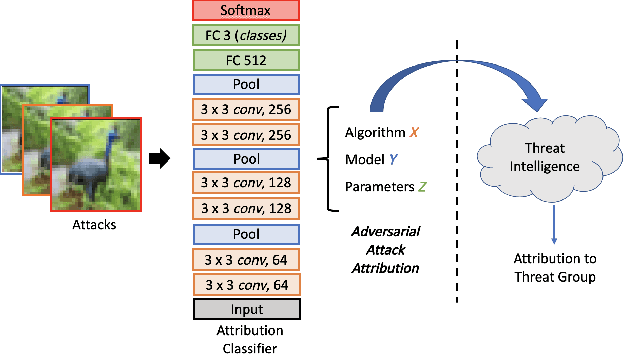

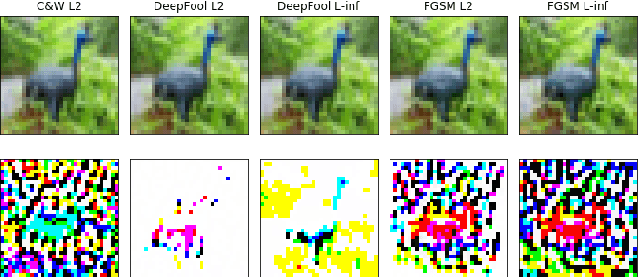
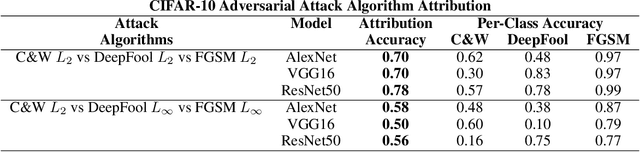
Machine Learning (ML) models are known to be vulnerable to adversarial inputs and researchers have demonstrated that even production systems, such as self-driving cars and ML-as-a-service offerings, are susceptible. These systems represent a target for bad actors. Their disruption can cause real physical and economic harm. When attacks on production ML systems occur, the ability to attribute the attack to the responsible threat group is a critical step in formulating a response and holding the attackers accountable. We pose the following question: can adversarially perturbed inputs be attributed to the particular methods used to generate the attack? In other words, is there a way to find a signal in these attacks that exposes the attack algorithm, model architecture, or hyperparameters used in the attack? We introduce the concept of adversarial attack attribution and create a simple supervised learning experimental framework to examine the feasibility of discovering attributable signals in adversarial attacks. We find that it is possible to differentiate attacks generated with different attack algorithms, models, and hyperparameters on both the CIFAR-10 and MNIST datasets.