 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership-Doctor: Comprehensive Assessment of Membership Inference Against Machine Learning Models
Paper and Code
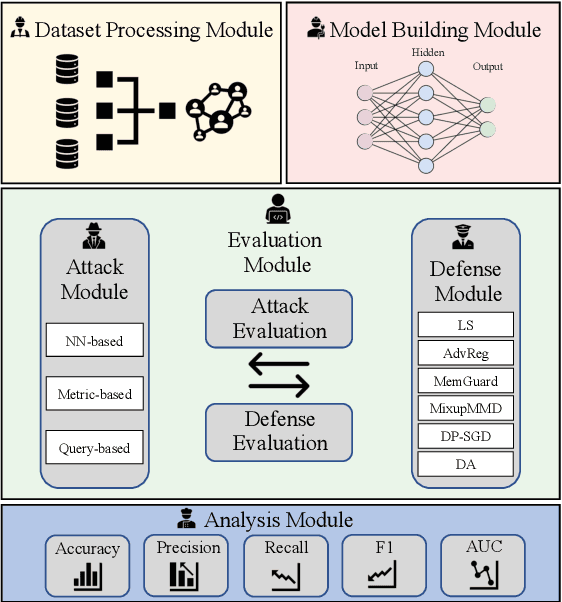
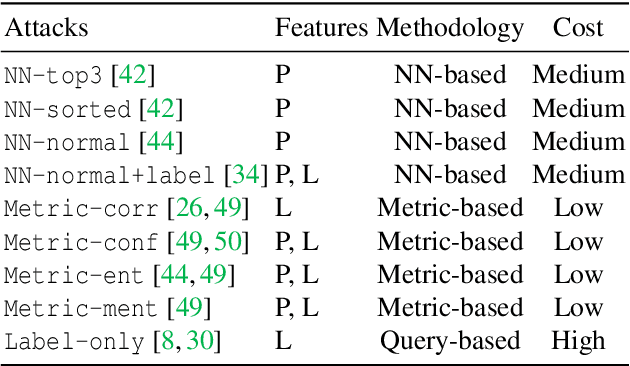


Machine learning models are prone to memorizing sensitive data, making them vulnerable to membership inference attacks in which an adversary aims to infer whether an input sample was used to train the model. Over the past few years, researchers have produced many membership inference attacks and defenses. However, these attacks and defenses employ a variety of strategies and are conducted in different models and datasets. The lack of comprehensive benchmark, however, means we do not understand the strengths and weaknesses of existing attacks and defenses. We fill this gap by presenting a large-scale measurement of different membership inference attacks and defenses. We systematize membership inference through the study of nine attacks and six defenses and measure the performance of different attacks and defenses in the holistic evaluation. We then quantify the impact of the threat model on the results of these attacks. We find that some assumptions of the threat model, such as same-architecture and same-distribution between shadow and target models, are unnecessary. We are also the first to execute attacks on the real-world data collected from the Internet, instead of laboratory datasets. We further investigate what determines the performance of membership inference attacks and reveal that the commonly believed overfitting level is not sufficient for the success of the attacks. Instead, the Jensen-Shannon distance of entropy/cross-entropy between member and non-member samples correlates with attack performance much better. This gives us a new way to accurately predict membership inference risks without running the attack. Finally, we find that data augmentation degrades the performance of existing attacks to a larger extent, and we propose an adaptive attack using augmentation to train shadow and attack models that improve attack performance.