Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Squeezing Mitigates and Detects Carlini/Wagner Adversarial Examples
Paper and Code
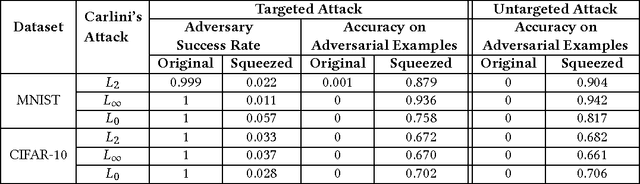

Feature squeezing is a recently-introduced framework for mitigating and detecting adversarial examples. In previous work, we showed that it is effective against several earlier methods for generating adversarial examples. In this short note, we report on recent results showing that simple feature squeezing techniques also make deep learning models significantly more robust against the Carlini/Wagner attacks, which are the best known adversarial methods discovered to date.
View paper on