 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-Accelerated Policy Dual Averaging for Reinforcement Learning in Continuous Action Spaces
Mar 10, 2026Policy Dual Averaging (PDA) offers a principled Policy Mirror Descent (PMD) framework that more naturally admits value function approximation than standard PMD, enabling the use of approximate advantage (or Q-) functions while retaining strong convergence guarantees. However, applying PDA in continuous state and action spaces remains computationally challenging, since action selection involves solving an optimization sub-problem at each decision step. In this paper, we propose \textit{actor-accelerated PDA}, which uses a learned policy network to approximate the solution of the optimization sub-problems, yielding faster runtimes while maintaining convergence guarantees. We provide a theoretical analysis that quantifies how actor approximation error impacts the convergence of PDA under suitable assumptions. We then evaluate its performance on several benchmarks in robotics, control, and operations research problems. Actor-accelerated PDA achieves superior performance compared to popular on-policy baselines such as Proximal Policy Optimization (PPO). Overall, our results bridge the gap between the theoretical advantages of PDA and its practical deployment in continuous-action problems with function approximation.
Deletion Inference, Reconstruction, and Compliance in Machine (Un)Learning
Feb 07, 2022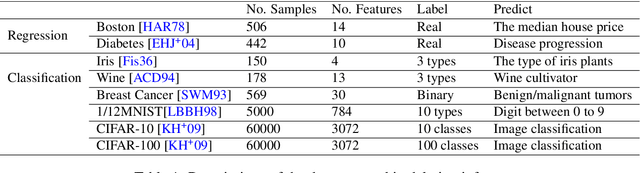
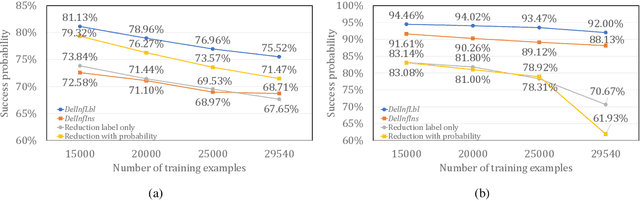
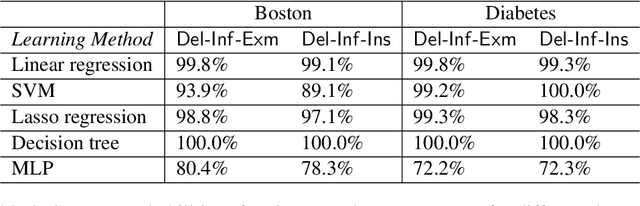
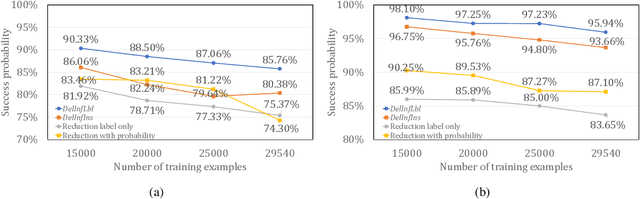
Privacy attacks on machine learning models aim to identify the data that is used to train such models. Such attacks, traditionally, are studied on static models that are trained once and are accessible by the adversary. Motivated to meet new legal requirements, many machine learning methods are recently extended to support machine unlearning, i.e., updating models as if certain examples are removed from their training sets, and meet new legal requirements. However, privacy attacks could potentially become more devastating in this new setting, since an attacker could now access both the original model before deletion and the new model after the deletion. In fact, the very act of deletion might make the deleted record more vulnerable to privacy attacks. Inspired by cryptographic definitions and the differential privacy framework, we formally study privacy implications of machine unlearning. We formalize (various forms of) deletion inference and deletion reconstruction attacks, in which the adversary aims to either identify which record is deleted or to reconstruct (perhaps part of) the deleted records. We then present successful deletion inference and reconstruction attacks for a variety of machine learning models and tasks such as classification, regression, and language models. Finally, we show that our attacks would provably be precluded if the schemes satisfy (variants of) Deletion Compliance (Garg, Goldwasser, and Vasudevan, Eurocrypt' 20).
Spotting adversarial samples for speaker verification by neural vocoders
Jul 02, 2021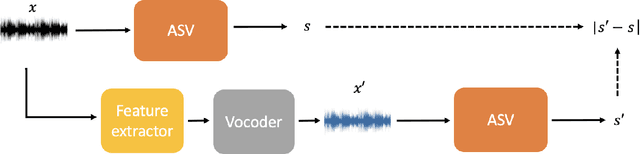
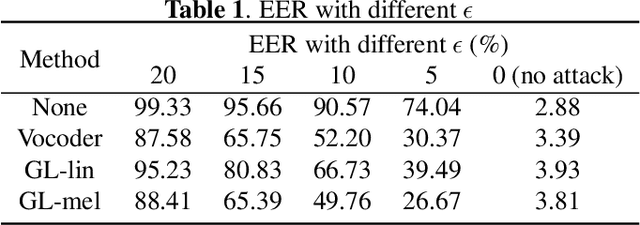
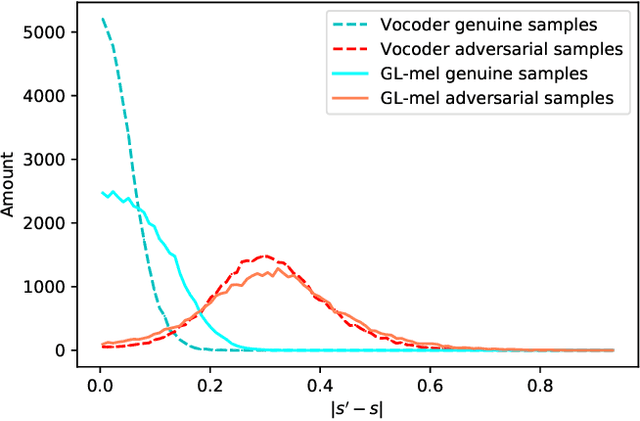
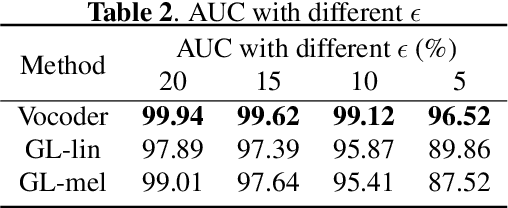
Automatic speaker verification (ASV), one of the most important technology for biometric identification, has been widely adopted in security-critical applications, including transaction authentication and access control. However, previous work has shown that ASV is seriously vulnerable to recently emerged adversarial attacks, yet effective countermeasures against them are limited. In this paper, we adopt neural vocoders to spot adversarial samples for ASV. We use the neural vocoder to re-synthesize audio and find that the difference between the ASV scores for the original and re-synthesized audio is a good indicator for discrimination between genuine and adversarial samples. This effort is, to the best of our knowledge, among the first to pursue such a technical direction for detecting adversarial samples for ASV, and hence there is a lack of established baselines for comparison. Consequently, we implement the Griffin-Lim algorithm as the detection baseline. The proposed approach achieves effective detection performance that outperforms all the baselines in all the settings. We also show that the neural vocoder adopted in the detection framework is dataset-independent. Our codes will be made open-source for future works to do comparison.
Learning and Certification under Instance-targeted Poisoning
May 18, 2021
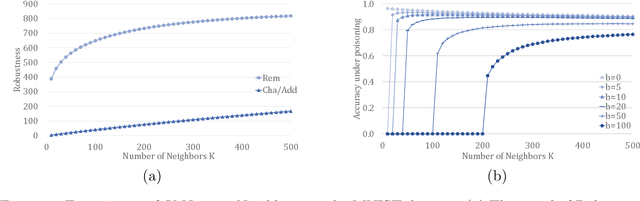
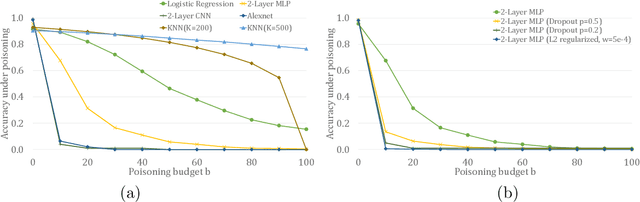
In this paper, we study PAC learnability and certification under instance-targeted poisoning attacks, where the adversary may change a fraction of the training set with the goal of fooling the learner at a specific target instance. Our first contribution is to formalize the problem in various settings, and explicitly discussing subtle aspects such as learner's randomness and whether (or not) adversary's attack can depend on it. We show that when the budget of the adversary scales sublinearly with the sample complexity, PAC learnability and certification are achievable. In contrast, when the adversary's budget grows linearly with the sample complexity, the adversary can potentially drive up the expected 0-1 loss to one. We further extend our results to distribution-specific PAC learning in the same attack model and show that proper learning with certification is possible for learning halfspaces under Gaussian distribution. Finally, we empirically study the robustness of K nearest neighbour, logistic regression, multi-layer perceptron, and convolutional neural network on real data sets, and test them against targeted-poisoning attacks. Our experimental results show that many models, especially state-of-the-art neural networks, are indeed vulnerable to these strong attacks. Interestingly, we observe that methods with high standard accuracy might be more vulnerable to instance-targeted poisoning attacks.
Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers
May 23, 2018
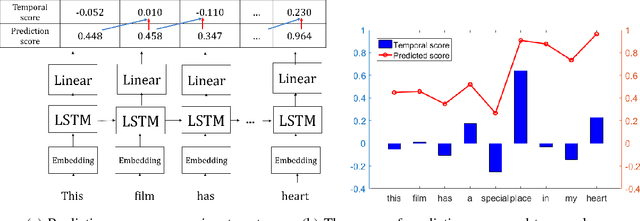
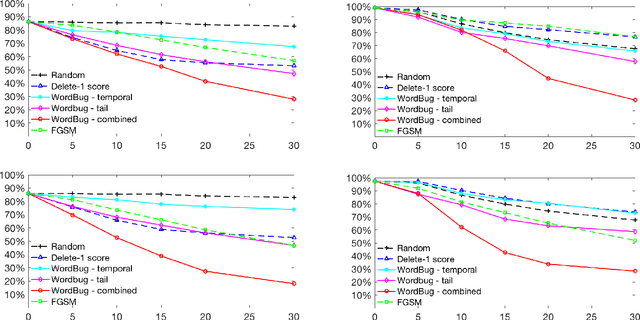
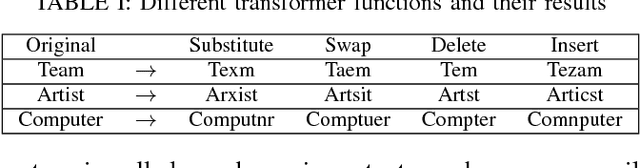
Although various techniques have been proposed to generate adversarial samples for white-box attacks on text, little attention has been paid to black-box attacks, which are more realistic scenarios. In this paper, we present a novel algorithm, DeepWordBug, to effectively generate small text perturbations in a black-box setting that forces a deep-learning classifier to misclassify a text input. We employ novel scoring strategies to identify the critical tokens that, if modified, cause the classifier to make an incorrect prediction. Simple character-level transformations are applied to the highest-ranked tokens in order to minimize the edit distance of the perturbation, yet change the original classification. We evaluated DeepWordBug on eight real-world text datasets, including text classification, sentiment analysis, and spam detection. We compare the result of DeepWordBug with two baselines: Random (Black-box) and Gradient (White-box). Our experimental results indicate that DeepWordBug reduces the prediction accuracy of current state-of-the-art deep-learning models, including a decrease of 68\% on average for a Word-LSTM model and 48\% on average for a Char-CNN model.
Exploring the Naturalness of Buggy Code with Recurrent Neural Networks
Mar 21, 2018
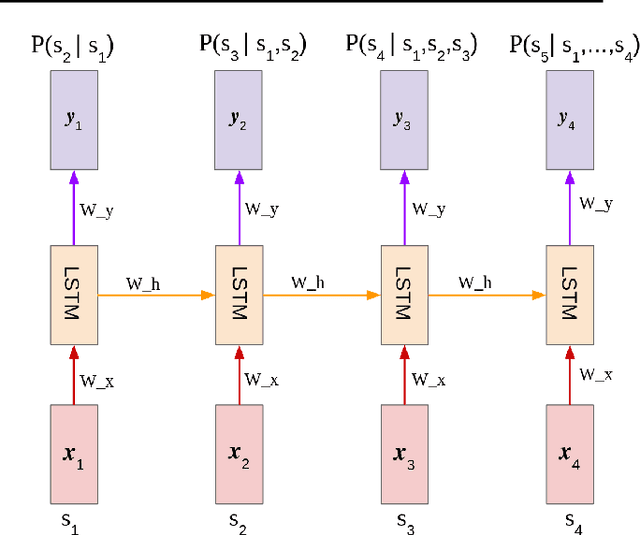
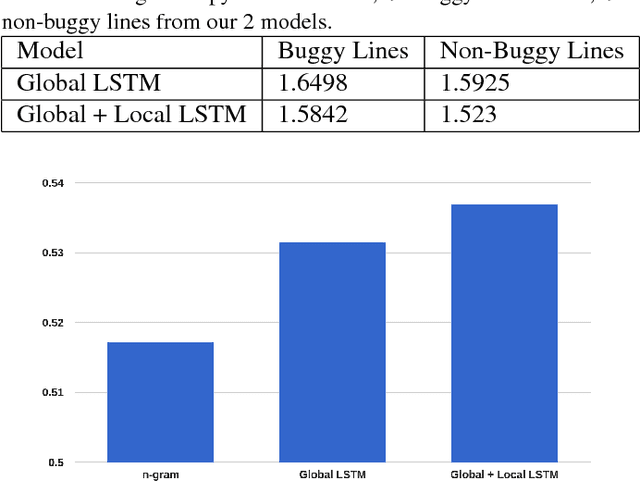
Statistical language models are powerful tools which have been used for many tasks within natural language processing. Recently, they have been used for other sequential data such as source code.(Ray et al., 2015) showed that it is possible train an n-gram source code language mode, and use it to predict buggy lines in code by determining "unnatural" lines via entropy with respect to the language model. In this work, we propose using a more advanced language modeling technique, Long Short-term Memory recurrent neural networks, to model source code and classify buggy lines based on entropy. We show that our method slightly outperforms an n-gram model in the buggy line classification task using AUC.
A Fast and Scalable Joint Estimator for Learning Multiple Related Sparse Gaussian Graphical Models
Mar 20, 2018
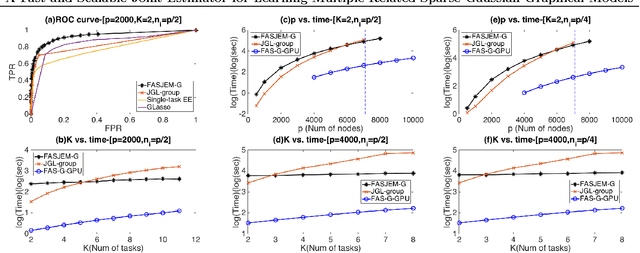

Estimating multiple sparse Gaussian Graphical Models (sGGMs) jointly for many related tasks (large $K$) under a high-dimensional (large $p$) situation is an important task. Most previous studies for the joint estimation of multiple sGGMs rely on penalized log-likelihood estimators that involve expensive and difficult non-smooth optimizations. We propose a novel approach, FASJEM for \underline{fa}st and \underline{s}calable \underline{j}oint structure-\underline{e}stimation of \underline{m}ultiple sGGMs at a large scale. As the first study of joint sGGM using the Elementary Estimator framework, our work has three major contributions: (1) We solve FASJEM through an entry-wise manner which is parallelizable. (2) We choose a proximal algorithm to optimize FASJEM. This improves the computational efficiency from $O(Kp^3)$ to $O(Kp^2)$ and reduces the memory requirement from $O(Kp^2)$ to $O(K)$. (3) We theoretically prove that FASJEM achieves a consistent estimation with a convergence rate of $O(\log(Kp)/n_{tot})$. On several synthetic and four real-world datasets, FASJEM shows significant improvements over baselines on accuracy, computational complexity, and memory costs.
A Theoretical Framework for Robustness of (Deep) Classifiers against Adversarial Examples
Sep 27, 2017
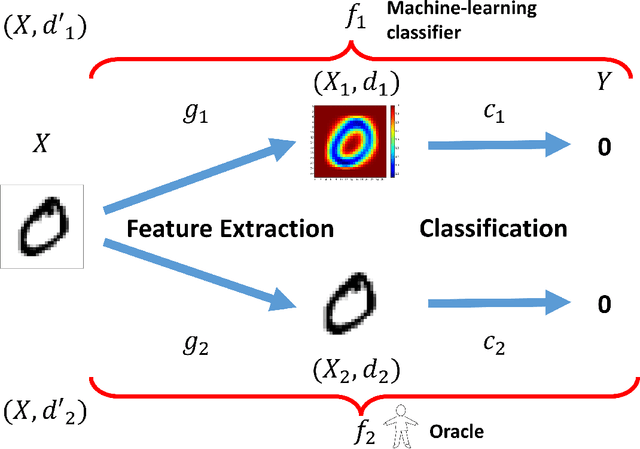
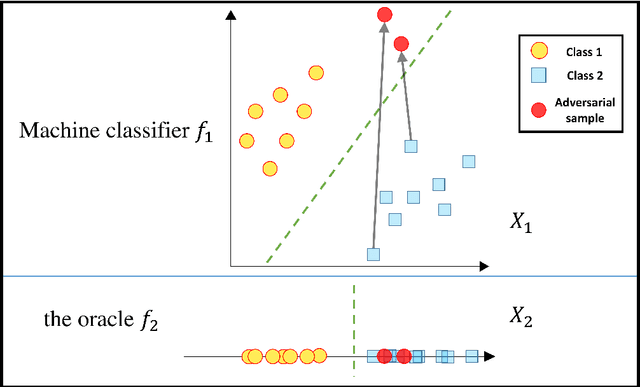
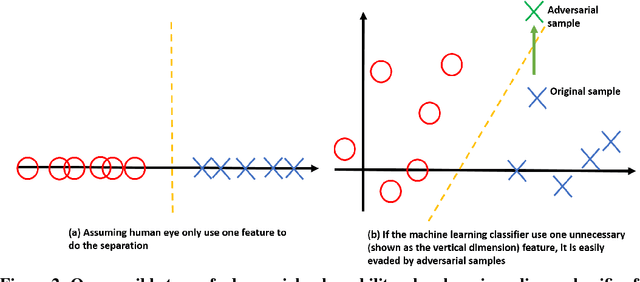
Most machine learning classifiers, including deep neural networks, are vulnerable to adversarial examples. Such inputs are typically generated by adding small but purposeful modifications that lead to incorrect outputs while imperceptible to human eyes. The goal of this paper is not to introduce a single method, but to make theoretical steps towards fully understanding adversarial examples. By using concepts from topology, our theoretical analysis brings forth the key reasons why an adversarial example can fool a classifier ($f_1$) and adds its oracle ($f_2$, like human eyes) in such analysis. By investigating the topological relationship between two (pseudo)metric spaces corresponding to predictor $f_1$ and oracle $f_2$, we develop necessary and sufficient conditions that can determine if $f_1$ is always robust (strong-robust) against adversarial examples according to $f_2$. Interestingly our theorems indicate that just one unnecessary feature can make $f_1$ not strong-robust, and the right feature representation learning is the key to getting a classifier that is both accurate and strong-robust.
DeepCloak: Masking Deep Neural Network Models for Robustness Against Adversarial Samples
Apr 17, 2017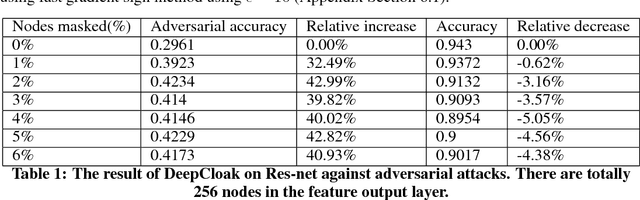
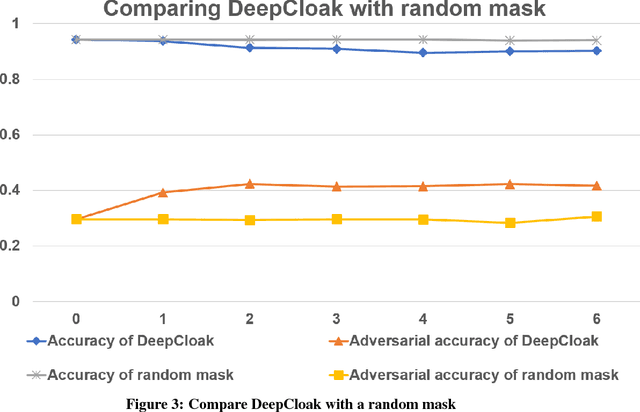
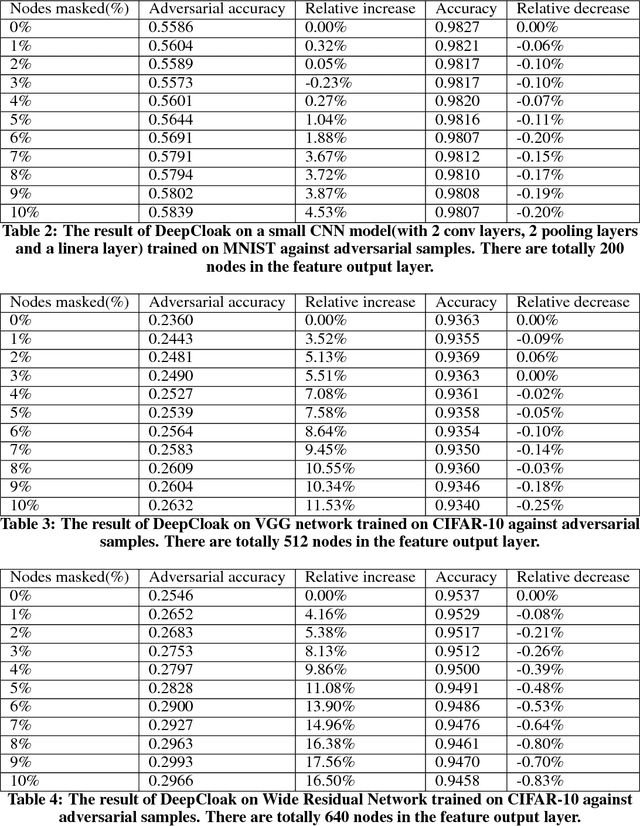
Recent studies have shown that deep neural networks (DNN) are vulnerable to adversarial samples: maliciously-perturbed samples crafted to yield incorrect model outputs. Such attacks can severely undermine DNN systems, particularly in security-sensitive settings. It was observed that an adversary could easily generate adversarial samples by making a small perturbation on irrelevant feature dimensions that are unnecessary for the current classification task. To overcome this problem, we introduce a defensive mechanism called DeepCloak. By identifying and removing unnecessary features in a DNN model, DeepCloak limits the capacity an attacker can use generating adversarial samples and therefore increase the robustness against such inputs. Comparing with other defensive approaches, DeepCloak is easy to implement and computationally efficient. Experimental results show that DeepCloak can increase the performance of state-of-the-art DNN models against adversarial samples.