 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers
Paper and Code

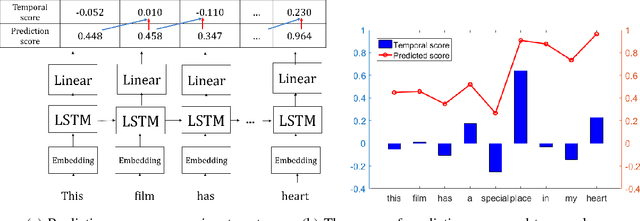
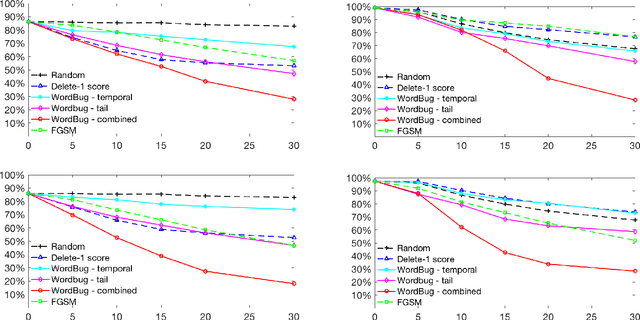
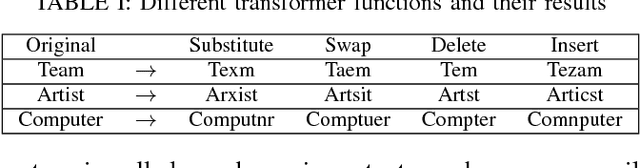
Although various techniques have been proposed to generate adversarial samples for white-box attacks on text, little attention has been paid to black-box attacks, which are more realistic scenarios. In this paper, we present a novel algorithm, DeepWordBug, to effectively generate small text perturbations in a black-box setting that forces a deep-learning classifier to misclassify a text input. We employ novel scoring strategies to identify the critical tokens that, if modified, cause the classifier to make an incorrect prediction. Simple character-level transformations are applied to the highest-ranked tokens in order to minimize the edit distance of the perturbation, yet change the original classification. We evaluated DeepWordBug on eight real-world text datasets, including text classification, sentiment analysis, and spam detection. We compare the result of DeepWordBug with two baselines: Random (Black-box) and Gradient (White-box). Our experimental results indicate that DeepWordBug reduces the prediction accuracy of current state-of-the-art deep-learning models, including a decrease of 68\% on average for a Word-LSTM model and 48\% on average for a Char-CNN model.