 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and Certification under Instance-targeted Poisoning
Paper and Code
May 18, 2021
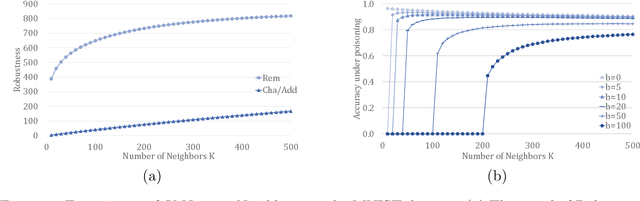
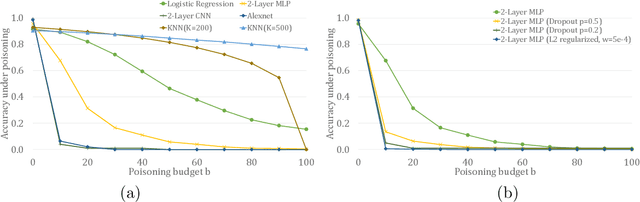
In this paper, we study PAC learnability and certification under instance-targeted poisoning attacks, where the adversary may change a fraction of the training set with the goal of fooling the learner at a specific target instance. Our first contribution is to formalize the problem in various settings, and explicitly discussing subtle aspects such as learner's randomness and whether (or not) adversary's attack can depend on it. We show that when the budget of the adversary scales sublinearly with the sample complexity, PAC learnability and certification are achievable. In contrast, when the adversary's budget grows linearly with the sample complexity, the adversary can potentially drive up the expected 0-1 loss to one. We further extend our results to distribution-specific PAC learning in the same attack model and show that proper learning with certification is possible for learning halfspaces under Gaussian distribution. Finally, we empirically study the robustness of K nearest neighbour, logistic regression, multi-layer perceptron, and convolutional neural network on real data sets, and test them against targeted-poisoning attacks. Our experimental results show that many models, especially state-of-the-art neural networks, are indeed vulnerable to these strong attacks. Interestingly, we observe that methods with high standard accuracy might be more vulnerable to instance-targeted poisoning attacks.