 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hyperspherical Time-Frequency Representations for Time-Series Out-of-Distribution Detection
May 29, 2026Out-of-distribution (OOD) detection for time-series data remains comparatively underexplored compared to vision and language, with a limited principled understanding of how supervised time-series representations can be leveraged for reliable detection under distributional shifts. This work formulates time-series OOD detection as representation learning with hyperspherical embeddings, where class-conditional structure is induced by a von Mises-Fisher (vMF) likelihood-based objective on the unit sphere. The learned representation combines time- and frequency-domain views of the input signal via domain-specific encoders, integrating them into a joint embedding space for OOD detection. Detection uses distance-based scores over the learned embeddings, including k-nearest neighbors (k-NN) and Mahalanobis scores. We evaluate the approach at scale on the complete UCR and UEA time-series archives under a cross-dataset protocol. Empirical results show consistent improvements under both k-NN and Mahalanobis scoring over strong contrastive learning and post-hoc baselines in the same setting. Code is available at https://github.com/tiiuae/hypertf-time-series-ood.
Secure Safety Filter: Towards Safe Flight Control under Sensor Attacks
May 11, 2025Modern autopilot systems are prone to sensor attacks that can jeopardize flight safety. To mitigate this risk, we proposed a modular solution: the secure safety filter, which extends the well-established control barrier function (CBF)-based safety filter to account for, and mitigate, sensor attacks. This module consists of a secure state reconstructor (which generates plausible states) and a safety filter (which computes the safe control input that is closest to the nominal one). Differing from existing work focusing on linear, noise-free systems, the proposed secure safety filter handles bounded measurement noise and, by leveraging reduced-order model techniques, is applicable to the nonlinear dynamics of drones. Software-in-the-loop simulations and drone hardware experiments demonstrate the effectiveness of the secure safety filter in rendering the system safe in the presence of sensor attacks.
Learning In-Distribution Representations for Anomaly Detection
Jan 10, 2025



Anomaly detection involves identifying data patterns that deviate from the anticipated norm. Traditional methods struggle in high-dimensional spaces due to the curse of dimensionality. In recent years, self-supervised learning, particularly through contrastive objectives, has driven advances in anomaly detection. However, vanilla contrastive learning struggles to align with the unique demands of anomaly detection, as it lacks a pretext task tailored to the homogeneous nature of In-Distribution (ID) data and the diversity of Out-of-Distribution (OOD) anomalies. Methods that attempt to address these challenges, such as introducing hard negatives through synthetic outliers, Outlier Exposure (OE), and supervised objectives, often rely on pretext tasks that fail to balance compact clustering of ID samples with sufficient separation from OOD data. In this work, we propose Focused In-distribution Representation Modeling (FIRM), a contrastive learning objective specifically designed for anomaly detection. Unlike existing approaches, FIRM incorporates synthetic outliers into its pretext task in a way that actively shapes the representation space, promoting compact clustering of ID samples while enforcing strong separation from outliers. This formulation addresses the challenges of class collision, enhancing both the compactness of ID representations and the discriminative power of the learned feature space. We show that FIRM surpasses other contrastive methods in standard benchmarks, significantly enhancing anomaly detection compared to both traditional and supervised contrastive learning objectives. Our ablation studies confirm that FIRM consistently improves the quality of representations and shows robustness across a range of scoring methods. The code is available at: https://github.com/willtl/firm.
Non-Robust Features are Not Always Useful in One-Class Classification
Jul 08, 2024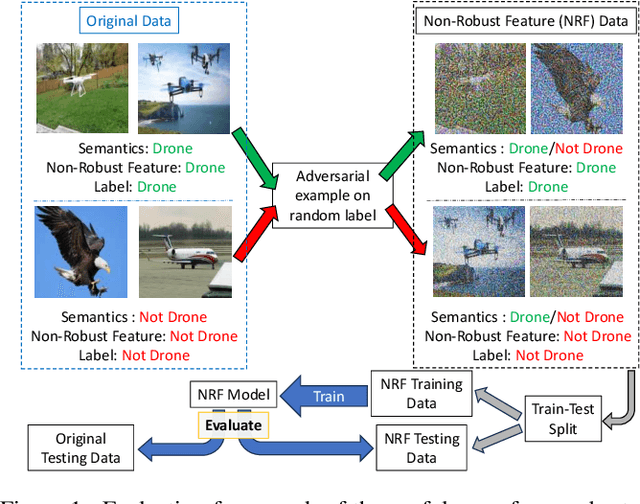

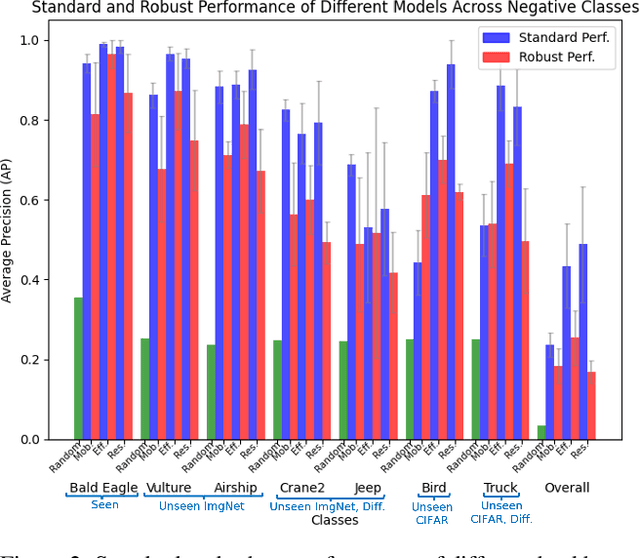
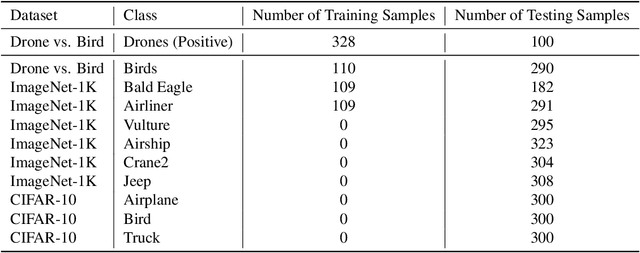
The robustness of machine learning models has been questioned by the existence of adversarial examples. We examine the threat of adversarial examples in practical applications that require lightweight models for one-class classification. Building on Ilyas et al. (2019), we investigate the vulnerability of lightweight one-class classifiers to adversarial attacks and possible reasons for it. Our results show that lightweight one-class classifiers learn features that are not robust (e.g. texture) under stronger attacks. However, unlike in multi-class classification (Ilyas et al., 2019), these non-robust features are not always useful for the one-class task, suggesting that learning these unpredictive and non-robust features is an unwanted consequence of training.
ARCADE: Adversarially Regularized Convolutional Autoencoder for Network Anomaly Detection
May 13, 2022
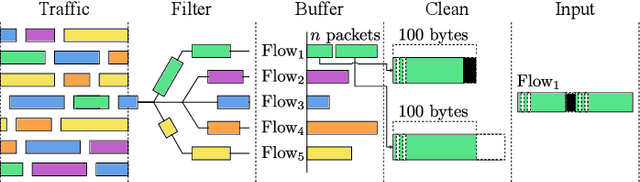


As the number of heterogenous IP-connected devices and traffic volume increase, so does the potential for security breaches. The undetected exploitation of these breaches can bring severe cybersecurity and privacy risks. In this paper, we present a practical unsupervised anomaly-based deep learning detection system called ARCADE (Adversarially Regularized Convolutional Autoencoder for unsupervised network anomaly DEtection). ARCADE exploits the property of 1D Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GAN) to automatically build a profile of the normal traffic based on a subset of raw bytes of a few initial packets of network flows so that potential network anomalies and intrusions can be effectively detected before they could cause any more damage to the network. A convolutional Autoencoder (AE) is proposed that suits online detection in resource-constrained environments, and can be easily improved for environments with higher computational capabilities. An adversarial training strategy is proposed to regularize and decrease the AE's capabilities to reconstruct network flows that are out of the normal distribution, and thereby improve its anomaly detection capabilities. The proposed approach is more effective than existing state-of-the-art deep learning approaches for network anomaly detection and significantly reduces detection time. The evaluation results show that the proposed approach is suitable for anomaly detection on resource-constrained hardware platforms such as Raspberry Pi.
Metaheuristics for the Online Printing Shop Scheduling Problem
Jun 22, 2020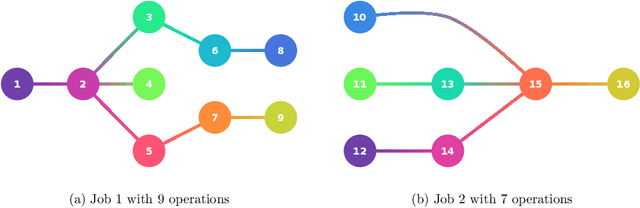
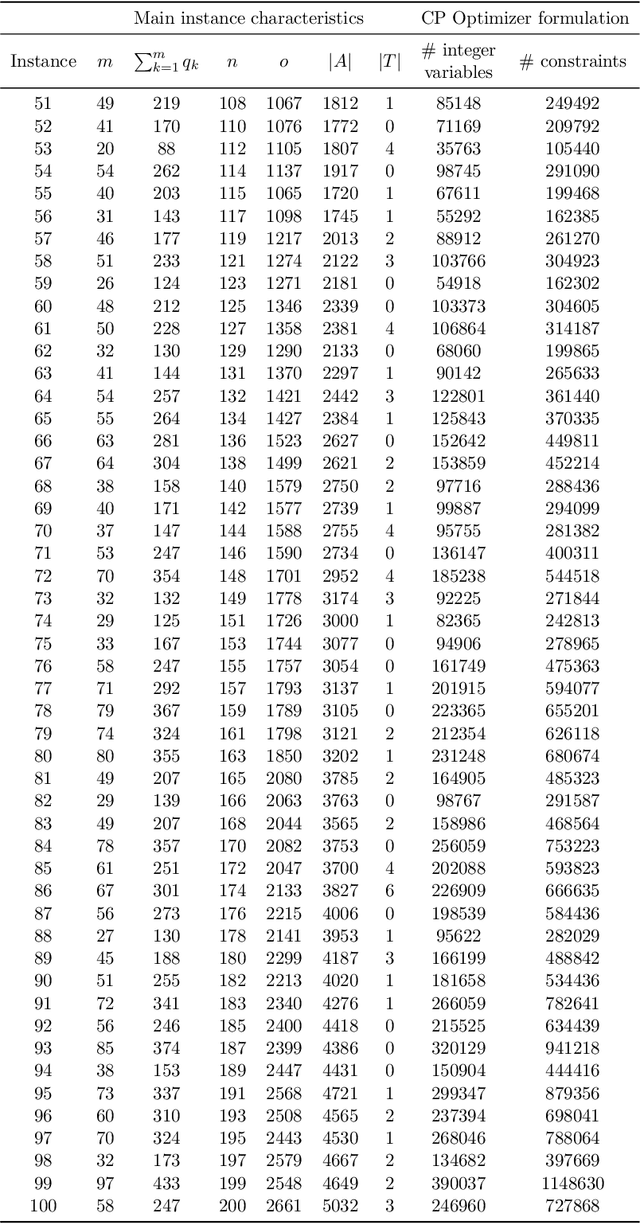
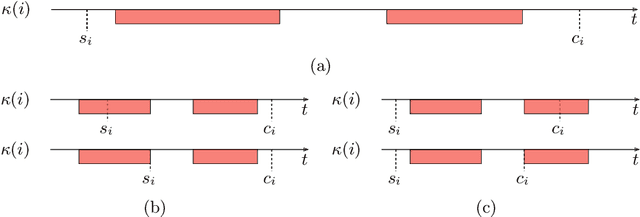
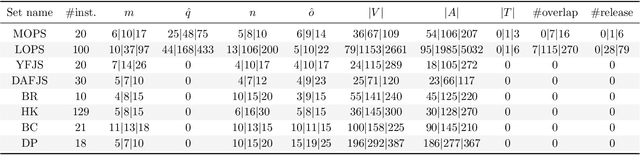
In this work, the online printing shop scheduling problem introduced in (Lunardi et al., Mixed Integer Linear Programming and Constraint Programming Models for the Online Printing Shop Scheduling Problem, Computers & Operations Research, to appear) is considered. This challenging real scheduling problem, that emerged in the nowadays printing industry, corresponds to a flexible job shop scheduling problem with sequencing flexibility; and it presents several complicating specificities such as resumable operations, periods of unavailability of the machines, sequence-dependent setup times, partial overlapping between operations with precedence constraints, and fixed operations, among others. A local search strategy and metaheuristic approaches for the problem are proposed and evaluated. Based on a common representation scheme, trajectory and populational metaheuristics are considered. Extensive numerical experiments with large-sized instances show that the proposed methods are suitable for solving practical instances of the problem; and that they outperform a half-heuristic-half-exact off-the-shelf solver by a large extent. Numerical experiments with classical instances of the flexible job shop scheduling problem show that the introduced methods are also competitive when applied to this particular case.