 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Centric Unsupervised Image Captioning
Paper and Code
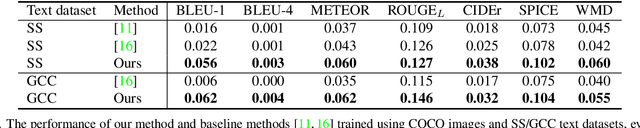



Training an image captioning model in an unsupervised manner without utilizing annotated image-caption pairs is an important step towards tapping into a wider corpus of text and images. In the supervised setting, image-caption pairs are "well-matched", where all objects mentioned in the sentence appear in the corresponding image. These pairings are, however, not available in the unsupervised setting. To overcome this, a main school of research that has been shown to be effective in overcoming this is to construct pairs from the images and texts in the training set according to their overlap of objects. Unlike in the supervised setting, these constructed pairings are however not guaranteed to have fully overlapping set of objects. Our work in this paper overcomes this by harvesting objects corresponding to a given sentence from the training set, even if they don't belong to the same image. When used as input to a transformer, such mixture of objects enable larger if not full object coverage, and when supervised by the corresponding sentence, produced results that outperform current state of the art unsupervised methods by a significant margin. Building upon this finding, we further show that (1) additional information on relationship between objects and attributes of objects also helps in boosting performance; and (2) our method also extends well to non-English image captioning, which usually suffers from a scarcer level of annotations. Our findings are supported by strong empirical results.