 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's in a Name? Evaluating Assembly-Part Semantic Knowledge in Language Models through User-Provided Names in CAD Files
Apr 25, 2023Semantic knowledge of part-part and part-whole relationships in assemblies is useful for a variety of tasks from searching design repositories to the construction of engineering knowledge bases. In this work we propose that the natural language names designers use in Computer Aided Design (CAD) software are a valuable source of such knowledge, and that Large Language Models (LLMs) contain useful domain-specific information for working with this data as well as other CAD and engineering-related tasks. In particular we extract and clean a large corpus of natural language part, feature and document names and use this to quantitatively demonstrate that a pre-trained language model can outperform numerous benchmarks on three self-supervised tasks, without ever having seen this data before. Moreover, we show that fine-tuning on the text data corpus further boosts the performance on all tasks, thus demonstrating the value of the text data which until now has been largely ignored. We also identify key limitations to using LLMs with text data alone, and our findings provide a strong motivation for further work into multi-modal text-geometry models. To aid and encourage further work in this area we make all our data and code publicly available.
UVStyle-Net: Unsupervised Few-shot Learning of 3D Style Similarity Measure for B-Reps
Apr 28, 2021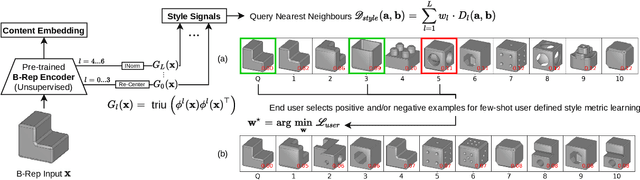

Boundary Representations (B-Reps) are the industry standard in 3D Computer Aided Design/Manufacturing (CAD/CAM) and industrial design due to their fidelity in representing stylistic details. However, they have been ignored in the 3D style research. Existing 3D style metrics typically operate on meshes or pointclouds, and fail to account for end-user subjectivity by adopting fixed definitions of style, either through crowd-sourcing for style labels or hand-crafted features. We propose UVStyle-Net, a style similarity measure for B-Reps that leverages the style signals in the second order statistics of the activations in a pre-trained (unsupervised) 3D encoder, and learns their relative importance to a subjective end-user through few-shot learning. Our approach differs from all existing data-driven 3D style methods since it may be used in completely unsupervised settings, which is desirable given the lack of publicly available labelled B-Rep datasets. More importantly, the few-shot learning accounts for the inherent subjectivity associated with style. We show quantitatively that our proposed method with B-Reps is able to capture stronger style signals than alternative methods on meshes and pointclouds despite its significantly greater computational efficiency. We also show it is able to generate meaningful style gradients with respect to the input shape, and that few-shot learning with as few as two positive examples selected by an end-user is sufficient to significantly improve the style measure. Finally, we demonstrate its efficacy on a large unlabeled public dataset of CAD models. Source code and data will be released in the future.
BRepNet: A topological message passing system for solid models
Apr 08, 2021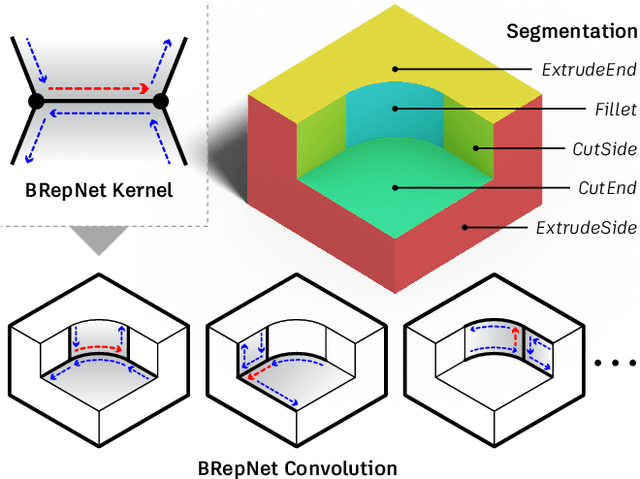


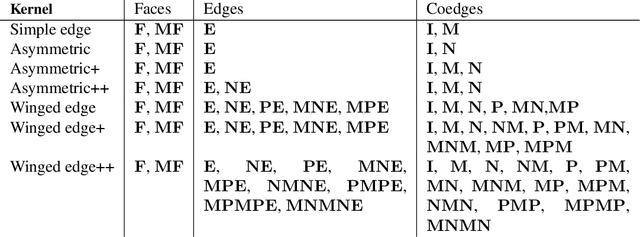
Boundary representation (B-rep) models are the standard way 3D shapes are described in Computer-Aided Design (CAD) applications. They combine lightweight parametric curves and surfaces with topological information which connects the geometric entities to describe manifolds. In this paper we introduce BRepNet, a neural network architecture designed to operate directly on B-rep data structures, avoiding the need to approximate the model as meshes or point clouds. BRepNet defines convolutional kernels with respect to oriented coedges in the data structure. In the neighborhood of each coedge, a small collection of faces, edges and coedges can be identified and patterns in the feature vectors from these entities detected by specific learnable parameters. In addition, to encourage further deep learning research with B-reps, we publish the Fusion 360 Gallery segmentation dataset. A collection of over 35,000 B-rep models annotated with information about the modeling operations which created each face. We demonstrate that BRepNet can segment these models with higher accuracy than methods working on meshes, and point clouds.
PiNet: Attention Pooling for Graph Classification
Aug 11, 2020

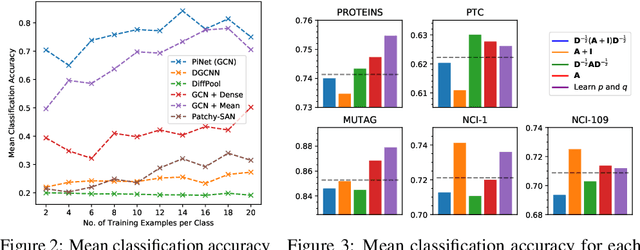
We propose PiNet, a generalised differentiable attention-based pooling mechanism for utilising graph convolution operations for graph level classification. We demonstrate high sample efficiency and superior performance over other graph neural networks in distinguishing isomorphic graph classes, as well as competitive results with state of the art methods on standard chemo-informatics datasets.
* 4 pages, 3 figures 1 table
PiNet: A Permutation Invariant Graph Neural Network for Graph Classification
May 08, 2019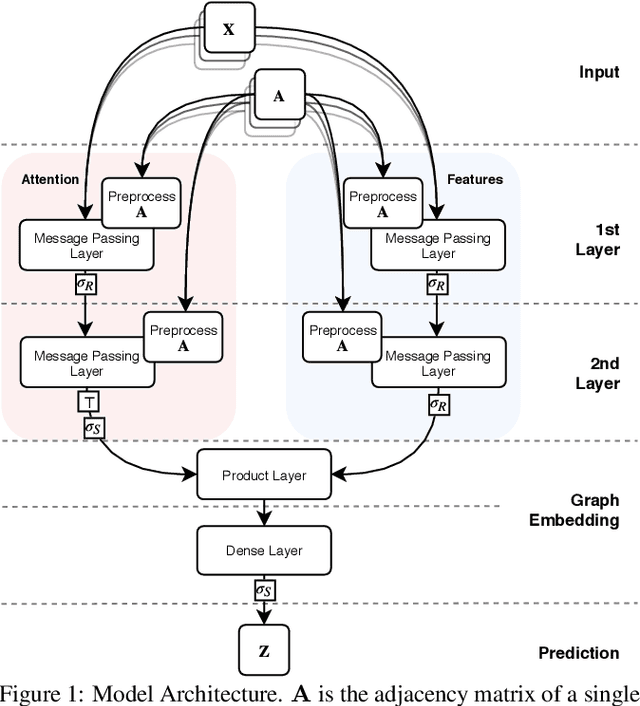
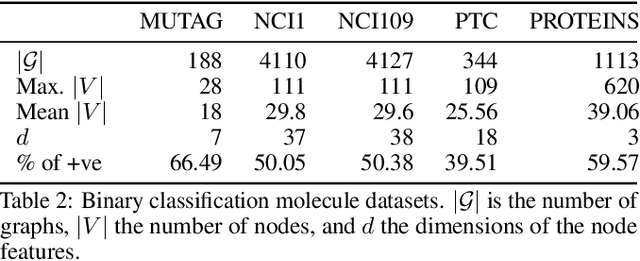
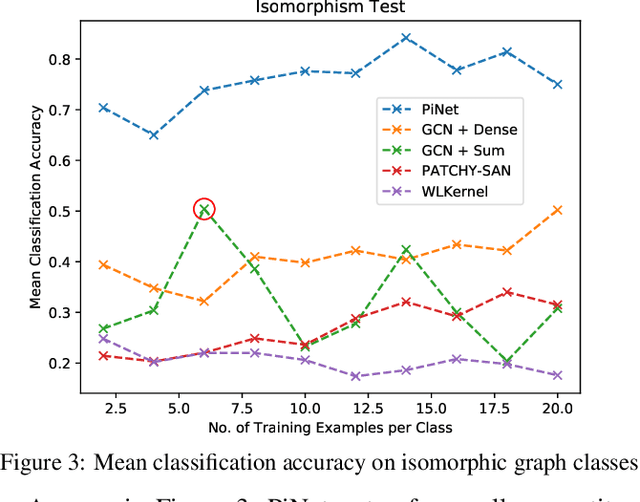
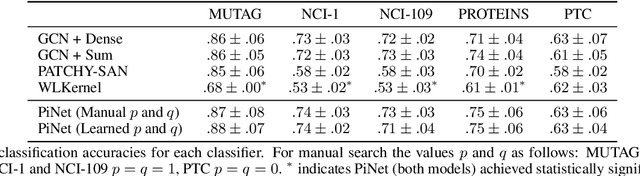
We propose an end-to-end deep learning learning model for graph classification and representation learning that is invariant to permutation of the nodes of the input graphs. We address the challenge of learning a fixed size graph representation for graphs of varying dimensions through a differentiable node attention pooling mechanism. In addition to a theoretical proof of its invariance to permutation, we provide empirical evidence demonstrating the statistically significant gain in accuracy when faced with an isomorphic graph classification task given only a small number of training examples. We analyse the effect of four different matrices to facilitate the local message passing mechanism by which graph convolutions are performed vs. a matrix parametrised by a learned parameter pair able to transition smoothly between the former. Finally, we show that our model achieves competitive classification performance with existing techniques on a set of molecule datasets.
Capsule Neural Networks for Graph Classification using Explicit Tensorial Graph Representations
Feb 22, 2019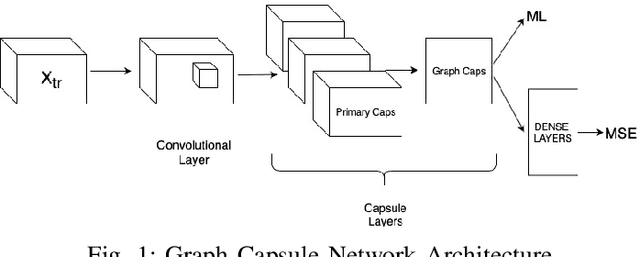
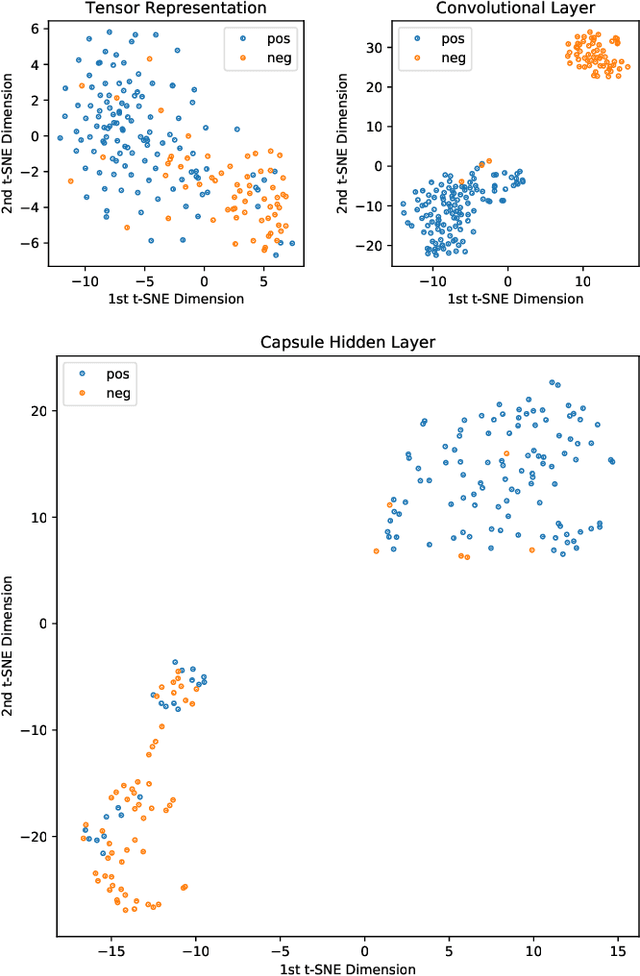
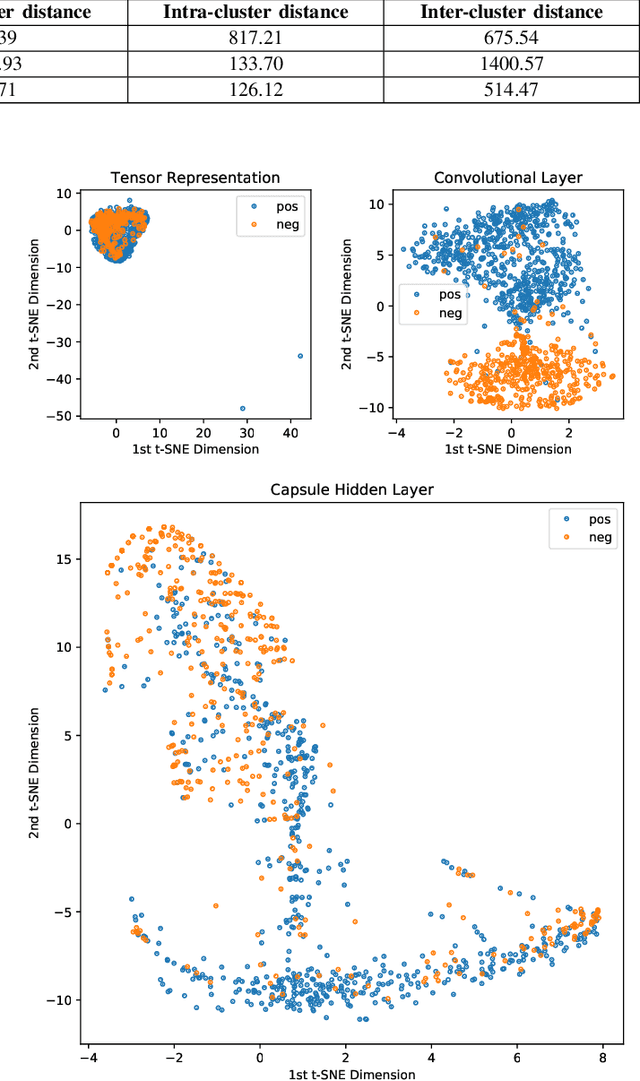
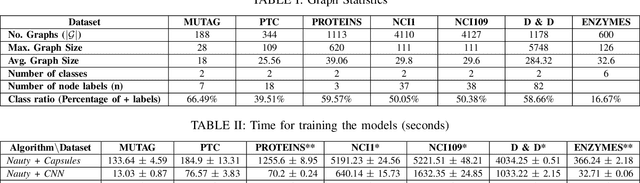
Graph classification is a significant problem in many scientific domains. It addresses tasks such as the classification of proteins and chemical compounds into categories according to their functions, or chemical and structural properties. In a supervised setting, this problem can be framed as learning the structure, features and relationships between features within a set of labelled graphs and being able to correctly predict the labels or categories of unseen graphs. A significant difficulty in this task arises when attempting to apply established classification algorithms due to the requirement for fixed size matrix or tensor representations of the graphs which may vary greatly in their numbers of nodes and edges. Building on prior work combining explicit tensor representations with a standard image-based classifier, we propose a model to perform graph classification by extracting fixed size tensorial information from each graph in a given set, and using a Capsule Network to perform classification. The graphs we consider here are undirected and with categorical features on the nodes. Using standard benchmarking chemical and protein datasets, we demonstrate that our graph Capsule Network classification model using an explicit tensorial representation of the graphs is competitive with current state of the art graph kernels and graph neural network models despite only limited hyper-parameter searching.