 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCactus: Accelerating Auto-Regressive Decoding with Constrained Acceptance Speculative Sampling
Apr 05, 2026Speculative sampling (SpS) has been successful in accelerating the decoding throughput of auto-regressive large language models by leveraging smaller draft models. SpS strictly enforces the generated distribution to match that of the verifier LLM. This is unnecessarily restrictive as slight variations of the verifier's distribution, such as sampling with top-$k$ or temperature, would also be acceptable. Typical acceptance sampling (TAS) alleviates this issue by accepting more tokens using entropy-based heuristics. However, this approach distorts the verifier distribution, potentially degrading output quality when the verifier encodes critical information. In this work, we formalize the speculative sampling algorithm through the lens of constrained optimization. Based on this formulation, we propose Cactus (constrained acceptance speculative sampling), a method that guarantees controlled divergence from the verifier distribution and increasing acceptance rates. Empirical results across a wide range of benchmarks confirm the effectiveness of our approach.
Radar: Fast Long-Context Decoding for Any Transformer
Mar 13, 2025Transformer models have demonstrated exceptional performance across a wide range of applications. Though forming the foundation of Transformer models, the dot-product attention does not scale well to long-context data since its time requirement grows quadratically with context length. In this work, we propose Radar, a training-free approach that accelerates inference by dynamically searching for the most important context tokens. For any pre-trained Transformer, Radar can reduce the decoding time complexity without training or heuristically evicting tokens. Moreover, we provide theoretical justification for our approach, demonstrating that Radar can reliably identify the most important tokens with high probability. We conduct extensive comparisons with the previous methods on a wide range of tasks. The results demonstrate that Radar achieves the state-of-the-art performance across different architectures with reduced time complexity, offering a practical solution for efficient long-context processing of Transformers.
ULPT: Prompt Tuning with Ultra-Low-Dimensional Optimization
Feb 06, 2025



Large language models achieve state-of-the-art performance but are costly to fine-tune due to their size. Parameter-efficient fine-tuning methods, such as prompt tuning, address this by reducing trainable parameters while maintaining strong performance. However, prior methods tie prompt embeddings to the model's dimensionality, which may not scale well with larger LLMs and more customized LLMs. In this paper, we propose Ultra-Low-dimensional Prompt Tuning (ULPT), which optimizes prompts in a low-dimensional space (e.g., 2D) and use a random but frozen matrix for the up-projection. To enhance alignment, we introduce learnable shift and scale embeddings. ULPT drastically reduces the trainable parameters, e.g., 2D only using 2% parameters compared with vanilla prompt tuning while retaining most of the performance across 21 NLP tasks. Our theoretical analysis shows that random projections can capture high-rank structures effectively, and experimental results demonstrate ULPT's competitive performance over existing parameter-efficient methods.
Exploiting the Index Gradients for Optimization-Based Jailbreaking on Large Language Models
Dec 11, 2024



Despite the advancements in training Large Language Models (LLMs) with alignment techniques to enhance the safety of generated content, these models remain susceptible to jailbreak, an adversarial attack method that exposes security vulnerabilities in LLMs. Notably, the Greedy Coordinate Gradient (GCG) method has demonstrated the ability to automatically generate adversarial suffixes that jailbreak state-of-the-art LLMs. However, the optimization process involved in GCG is highly time-consuming, rendering the jailbreaking pipeline inefficient. In this paper, we investigate the process of GCG and identify an issue of Indirect Effect, the key bottleneck of the GCG optimization. To this end, we propose the Model Attack Gradient Index GCG (MAGIC), that addresses the Indirect Effect by exploiting the gradient information of the suffix tokens, thereby accelerating the procedure by having less computation and fewer iterations. Our experiments on AdvBench show that MAGIC achieves up to a 1.5x speedup, while maintaining Attack Success Rates (ASR) on par or even higher than other baselines. Our MAGIC achieved an ASR of 74% on the Llama-2 and an ASR of 54% when conducting transfer attacks on GPT-3.5. Code is available at https://github.com/jiah-li/magic.
NeuZip: Memory-Efficient Training and Inference with Dynamic Compression of Neural Networks
Oct 28, 2024



The performance of neural networks improves when more parameters are used. However, the model sizes are constrained by the available on-device memory during training and inference. Although applying techniques like quantization can alleviate the constraint, they suffer from performance degradation. In this work, we introduce NeuZip, a new weight compression scheme based on the entropy of floating-point numbers in neural networks. With NeuZip, we are able to achieve memory-efficient training and inference without sacrificing performance. Notably, we significantly reduce the memory footprint of training a Llama-3 8B model from 31GB to less than 16GB, while keeping the training dynamics fully unchanged. In inference, our method can reduce memory usage by more than half while maintaining near-lossless performance. Our code is publicly available.
Flora: Low-Rank Adapters Are Secretly Gradient Compressors
Feb 05, 2024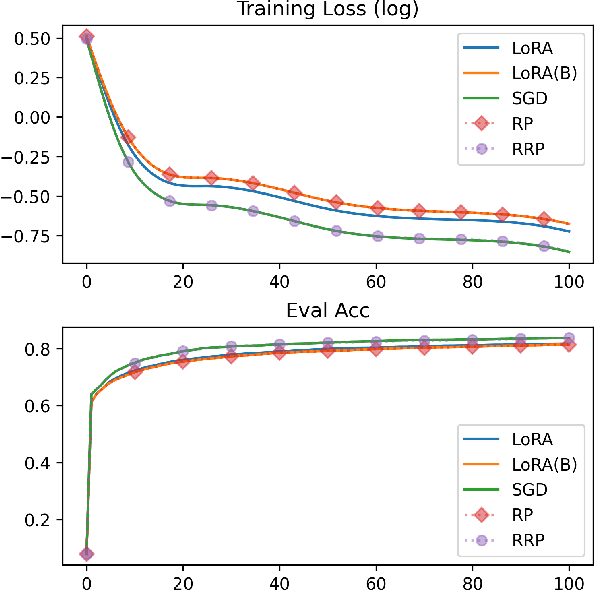



Despite large neural networks demonstrating remarkable abilities to complete different tasks, they require excessive memory usage to store the optimization states for training. To alleviate this, the low-rank adaptation (LoRA) is proposed to reduce the optimization states by training fewer parameters. However, LoRA restricts overall weight update matrices to be low-rank, limiting the model performance. In this work, we investigate the dynamics of LoRA and identify that it can be approximated by a random projection. Based on this observation, we propose Flora, which is able to achieve high-rank updates by resampling the projection matrices while enjoying the sublinear space complexity of optimization states. We conduct experiments across different tasks and model architectures to verify the effectiveness of our approach.
Ginger: An Efficient Curvature Approximation with Linear Complexity for General Neural Networks
Feb 05, 2024


Second-order optimization approaches like the generalized Gauss-Newton method are considered more powerful as they utilize the curvature information of the objective function with preconditioning matrices. Albeit offering tempting theoretical benefits, they are not easily applicable to modern deep learning. The major reason is due to the quadratic memory and cubic time complexity to compute the inverse of the matrix. These requirements are infeasible even with state-of-the-art hardware. In this work, we propose Ginger, an eigendecomposition for the inverse of the generalized Gauss-Newton matrix. Our method enjoys efficient linear memory and time complexity for each iteration. Instead of approximating the conditioning matrix, we directly maintain its inverse to make the approximation more accurate. We provide the convergence result of Ginger for non-convex objectives. Our experiments on different tasks with different model architectures verify the effectiveness of our method. Our code is publicly available.
Teacher Forcing Recovers Reward Functions for Text Generation
Oct 17, 2022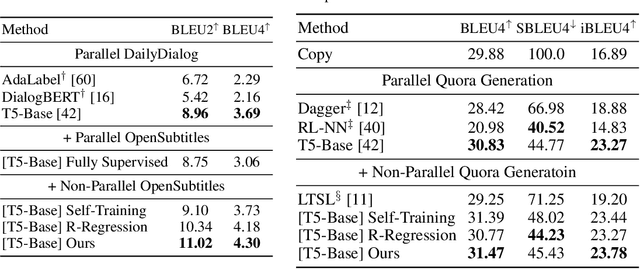
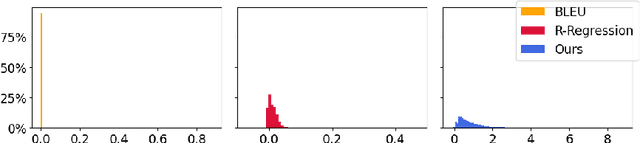

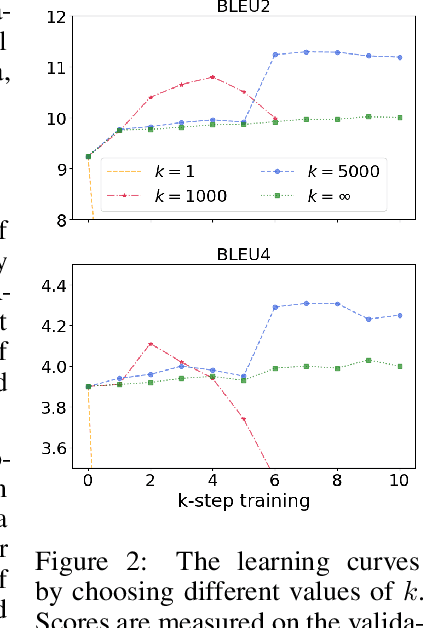
Reinforcement learning (RL) has been widely used in text generation to alleviate the exposure bias issue or to utilize non-parallel datasets. The reward function plays an important role in making RL training successful. However, previous reward functions are typically task-specific and sparse, restricting the use of RL. In our work, we propose a task-agnostic approach that derives a step-wise reward function directly from a model trained with teacher forcing. We additionally propose a simple modification to stabilize the RL training on non-parallel datasets with our induced reward function. Empirical results show that our method outperforms self-training and reward regression methods on several text generation tasks, confirming the effectiveness of our reward function.
An Equal-Size Hard EM Algorithm for Diverse Dialogue Generation
Sep 29, 2022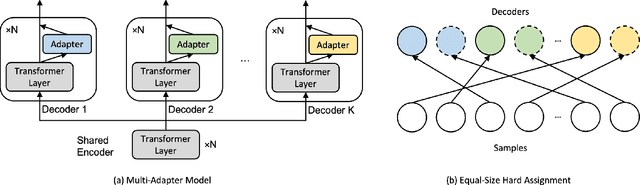
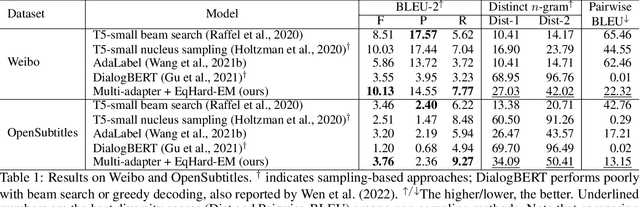
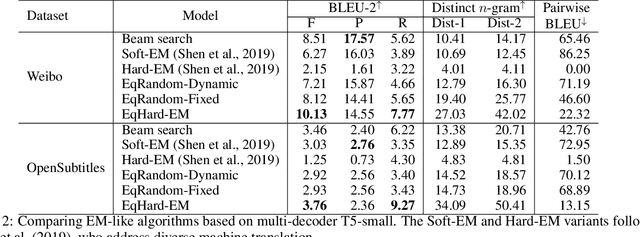
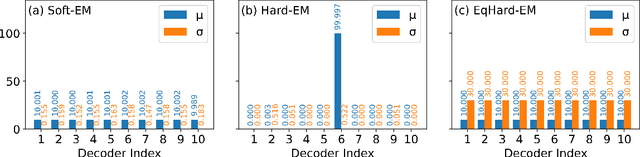
Open-domain dialogue systems aim to interact with humans through natural language texts in an open-ended fashion. However, the widely successful neural networks may not work well for dialogue systems, as they tend to generate generic responses. In this work, we propose an Equal-size Hard Expectation--Maximization (EqHard-EM) algorithm to train a multi-decoder model for diverse dialogue generation. Our algorithm assigns a sample to a decoder in a hard manner and additionally imposes an equal-assignment constraint to ensure that all decoders are well-trained. We provide detailed theoretical analysis to justify our approach. Further, experiments on two large-scale, open-domain dialogue datasets verify that our EqHard-EM algorithm generates high-quality diverse responses.
Understanding and Improving Sequence-to-Sequence Pretraining for Neural Machine Translation
Mar 16, 2022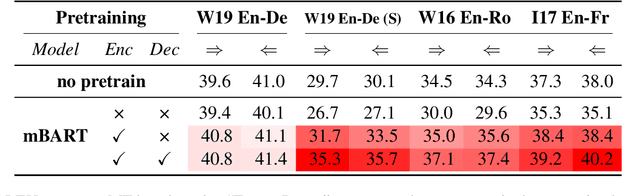
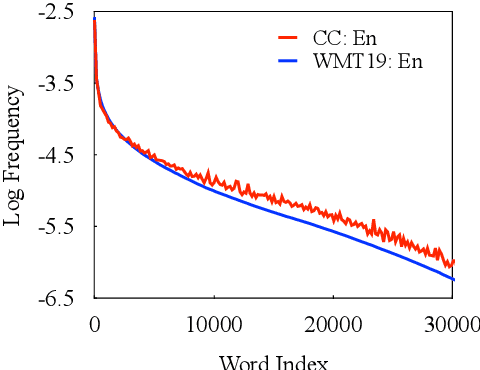

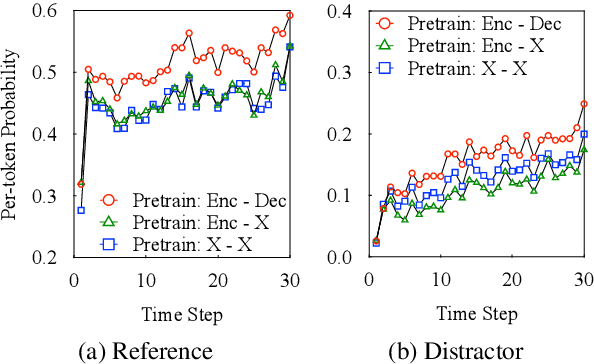
In this paper, we present a substantial step in better understanding the SOTA sequence-to-sequence (Seq2Seq) pretraining for neural machine translation~(NMT). We focus on studying the impact of the jointly pretrained decoder, which is the main difference between Seq2Seq pretraining and previous encoder-based pretraining approaches for NMT. By carefully designing experiments on three language pairs, we find that Seq2Seq pretraining is a double-edged sword: On one hand, it helps NMT models to produce more diverse translations and reduce adequacy-related translation errors. On the other hand, the discrepancies between Seq2Seq pretraining and NMT finetuning limit the translation quality (i.e., domain discrepancy) and induce the over-estimation issue (i.e., objective discrepancy). Based on these observations, we further propose simple and effective strategies, named in-domain pretraining and input adaptation to remedy the domain and objective discrepancies, respectively. Experimental results on several language pairs show that our approach can consistently improve both translation performance and model robustness upon Seq2Seq pretraining.