 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
DriveAnchor: Progressive Anchor-based Flow Learning for Autonomous Driving Planning
May 30, 2026We present DriveAnchor, a three-stage framework for autonomous driving planning that achieves behavioral diversity, controllability, and safety in a composable pipeline. Demonstration Flow Pretraining replaces the unstructured Gaussian prior with a vocabulary of 2,398 trajectory shapes constructed by farthest-point sampling, structurally grounding behavioral diversity in vocabulary coverage. Guided Flow Post-training jointly post-trains an Energy Field module with flow matching (FM), conditioning the Energy Field on static road geometry alone, to relocate anchors toward user-specified corridor polygons before flow generation, adding controllability without differentiable guidance; after Stage 2, new corridor presets require only Energy Field updates, not FM retraining. Reward-Refined Flow Fine-tuning applies zeroth-order reinforcement learning to align each anchor's output with collision-avoidance objectives: because the flow-matching model is a deterministic feedforward network in single-step mode, each anchor uniquely determines the output trajectory, reducing reward optimization to a direction search in anchor space without log-likelihood computation or ODE-to-SDE conversion. Evaluated on approximately 2 million held-out driving scenarios, DriveAnchor reduces near-range collision rates by 89% and improves mean reward by 32% without degradation in imitation accuracy, with 2.06 ms inference on NVIDIA Drive Orin. DriveAnchor has been validated through real-world vehicle testing, confirming its practicality for production deployment.
Exploiting the Index Gradients for Optimization-Based Jailbreaking on Large Language Models
Dec 11, 2024



Despite the advancements in training Large Language Models (LLMs) with alignment techniques to enhance the safety of generated content, these models remain susceptible to jailbreak, an adversarial attack method that exposes security vulnerabilities in LLMs. Notably, the Greedy Coordinate Gradient (GCG) method has demonstrated the ability to automatically generate adversarial suffixes that jailbreak state-of-the-art LLMs. However, the optimization process involved in GCG is highly time-consuming, rendering the jailbreaking pipeline inefficient. In this paper, we investigate the process of GCG and identify an issue of Indirect Effect, the key bottleneck of the GCG optimization. To this end, we propose the Model Attack Gradient Index GCG (MAGIC), that addresses the Indirect Effect by exploiting the gradient information of the suffix tokens, thereby accelerating the procedure by having less computation and fewer iterations. Our experiments on AdvBench show that MAGIC achieves up to a 1.5x speedup, while maintaining Attack Success Rates (ASR) on par or even higher than other baselines. Our MAGIC achieved an ASR of 74% on the Llama-2 and an ASR of 54% when conducting transfer attacks on GPT-3.5. Code is available at https://github.com/jiah-li/magic.
Evaluating Knowledge-based Cross-lingual Inconsistency in Large Language Models
Jul 01, 2024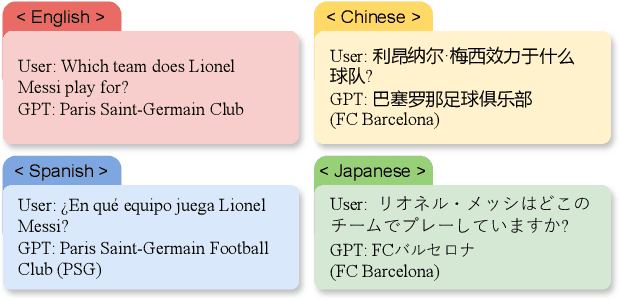
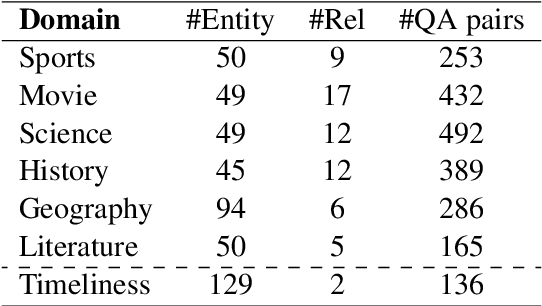

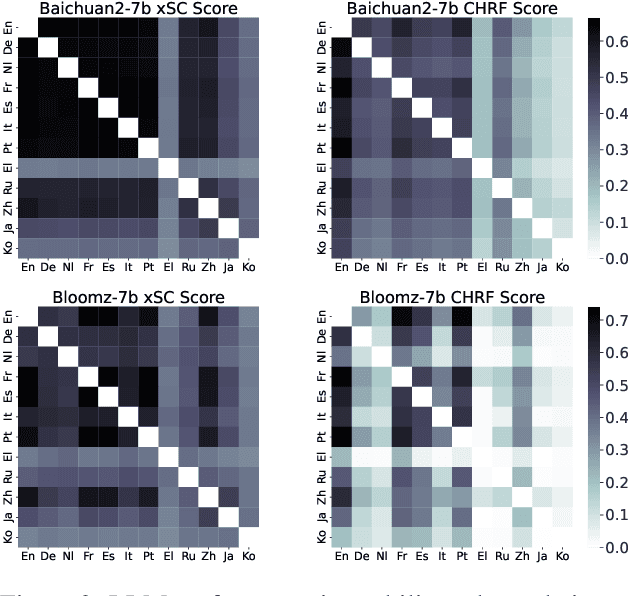
This paper investigates the cross-lingual inconsistencies observed in Large Language Models (LLMs), such as ChatGPT, Llama, and Baichuan, which have shown exceptional performance in various Natural Language Processing (NLP) tasks. Despite their successes, these models often exhibit significant inconsistencies when processing the same concepts across different languages. This study focuses on three primary questions: the existence of cross-lingual inconsistencies in LLMs, the specific aspects in which these inconsistencies manifest, and the correlation between cross-lingual consistency and multilingual capabilities of LLMs.To address these questions, we propose an innovative evaluation method for Cross-lingual Semantic Consistency (xSC) using the LaBSE model. We further introduce metrics for Cross-lingual Accuracy Consistency (xAC) and Cross-lingual Timeliness Consistency (xTC) to comprehensively assess the models' performance regarding semantic, accuracy, and timeliness inconsistencies. By harmonizing these metrics, we provide a holistic measurement of LLMs' cross-lingual consistency. Our findings aim to enhance the understanding and improvement of multilingual capabilities and interpretability in LLMs, contributing to the development of more robust and reliable multilingual language models.