 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectroVizQA: How well do Multi-modal LLMs perform in Electronics Visual Question Answering?
Nov 27, 2024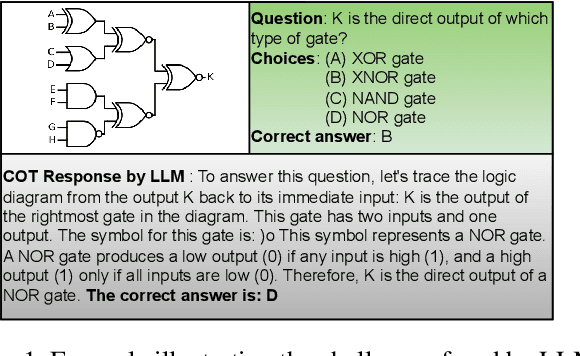
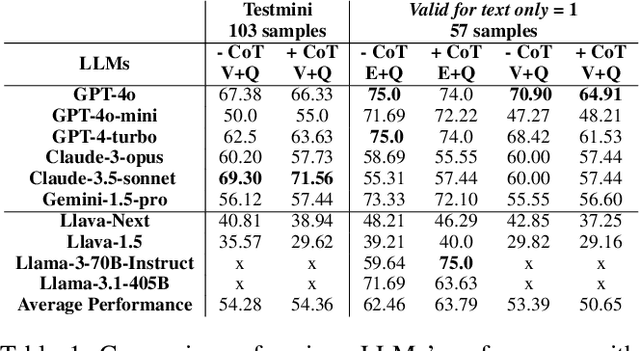
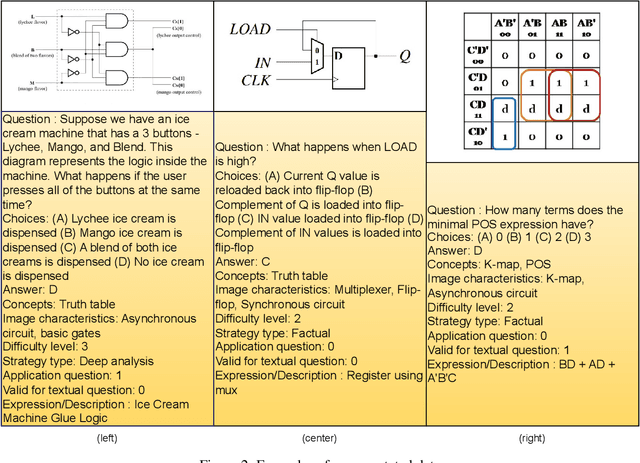

Multi-modal Large Language Models (MLLMs) are gaining significant attention for their ability to process multi-modal data, providing enhanced contextual understanding of complex problems. MLLMs have demonstrated exceptional capabilities in tasks such as Visual Question Answering (VQA); however, they often struggle with fundamental engineering problems, and there is a scarcity of specialized datasets for training on topics like digital electronics. To address this gap, we propose a benchmark dataset called ElectroVizQA specifically designed to evaluate MLLMs' performance on digital electronic circuit problems commonly found in undergraduate curricula. This dataset, the first of its kind tailored for the VQA task in digital electronics, comprises approximately 626 visual questions, offering a comprehensive overview of digital electronics topics. This paper rigorously assesses the extent to which MLLMs can understand and solve digital electronic circuit questions, providing insights into their capabilities and limitations within this specialized domain. By introducing this benchmark dataset, we aim to motivate further research and development in the application of MLLMs to engineering education, ultimately bridging the performance gap and enhancing the efficacy of these models in technical fields.
IEKG: A Commonsense Knowledge Graph for Idiomatic Expressions
Dec 11, 2023



Idiomatic expression (IE) processing and comprehension have challenged pre-trained language models (PTLMs) because their meanings are non-compositional. Unlike prior works that enable IE comprehension through fine-tuning PTLMs with sentences containing IEs, in this work, we construct IEKG, a commonsense knowledge graph for figurative interpretations of IEs. This extends the established ATOMIC2020 graph, converting PTLMs into knowledge models (KMs) that encode and infer commonsense knowledge related to IE use. Experiments show that various PTLMs can be converted into KMs with IEKG. We verify the quality of IEKG and the ability of the trained KMs with automatic and human evaluation. Through applications in natural language understanding, we show that a PTLM injected with knowledge from IEKG exhibits improved IE comprehension ability and can generalize to IEs unseen during training.
Unified Representation for Non-compositional and Compositional Expressions
Oct 29, 2023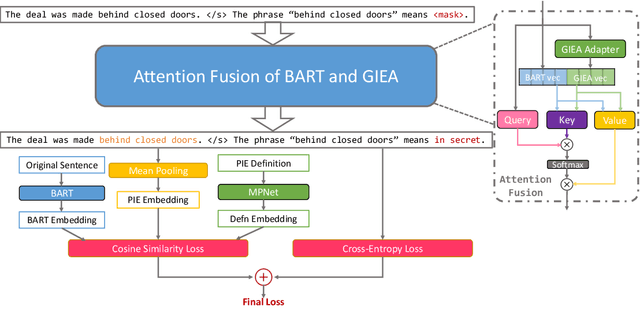



Accurate processing of non-compositional language relies on generating good representations for such expressions. In this work, we study the representation of language non-compositionality by proposing a language model, PIER, that builds on BART and can create semantically meaningful and contextually appropriate representations for English potentially idiomatic expressions (PIEs). PIEs are characterized by their non-compositionality and contextual ambiguity in their literal and idiomatic interpretations. Via intrinsic evaluation on embedding quality and extrinsic evaluation on PIE processing and NLU tasks, we show that representations generated by PIER result in 33% higher homogeneity score for embedding clustering than BART, whereas 3.12% and 3.29% gains in accuracy and sequence accuracy for PIE sense classification and span detection compared to the state-of-the-art IE representation model, GIEA. These gains are achieved without sacrificing PIER's performance on NLU tasks (+/- 1% accuracy) compared to BART.
CRISP: Curriculum based Sequential Neural Decoders for Polar Code Family
Oct 01, 2022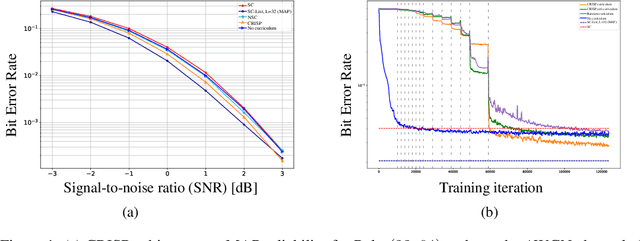
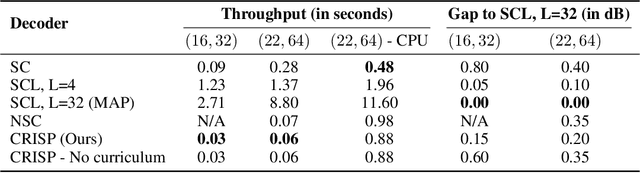
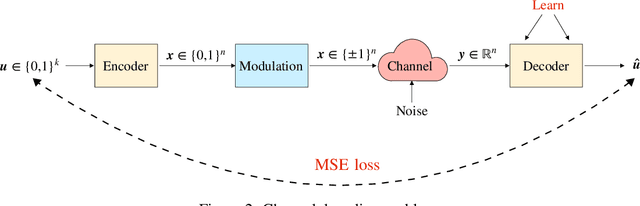
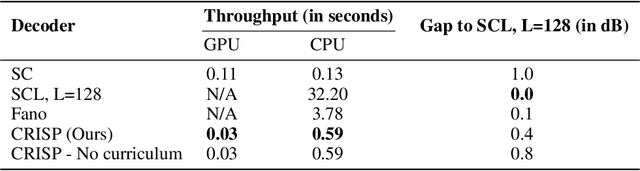
Polar codes are widely used state-of-the-art codes for reliable communication that have recently been included in the 5th generation wireless standards (5G). However, there remains room for the design of polar decoders that are both efficient and reliable in the short blocklength regime. Motivated by recent successes of data-driven channel decoders, we introduce a novel $\textbf{C}$ur$\textbf{RI}$culum based $\textbf{S}$equential neural decoder for $\textbf{P}$olar codes (CRISP). We design a principled curriculum, guided by information-theoretic insights, to train CRISP and show that it outperforms the successive-cancellation (SC) decoder and attains near-optimal reliability performance on the Polar(16,32) and Polar(22, 64) codes. The choice of the proposed curriculum is critical in achieving the accuracy gains of CRISP, as we show by comparing against other curricula. More notably, CRISP can be readily extended to Polarization-Adjusted-Convolutional (PAC) codes, where existing SC decoders are significantly less reliable. To the best of our knowledge, CRISP constructs the first data-driven decoder for PAC codes and attains near-optimal performance on the PAC(16, 32) code.
Getting BART to Ride the Idiomatic Train: Learning to Represent Idiomatic Expressions
Jul 08, 2022
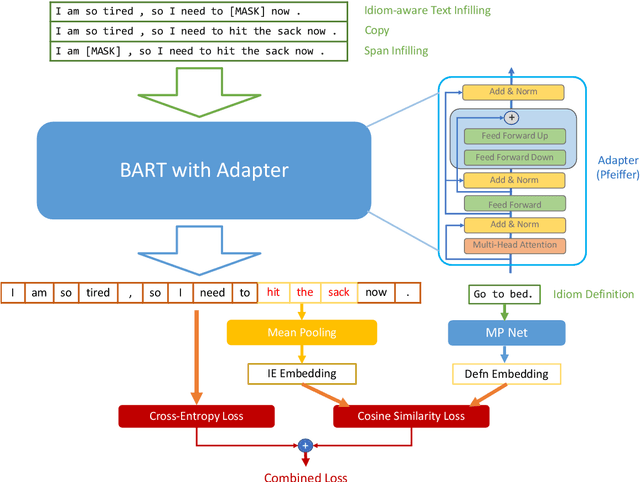
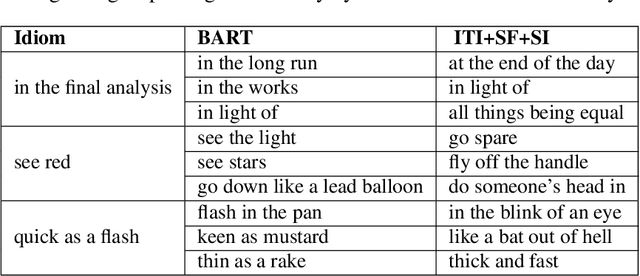
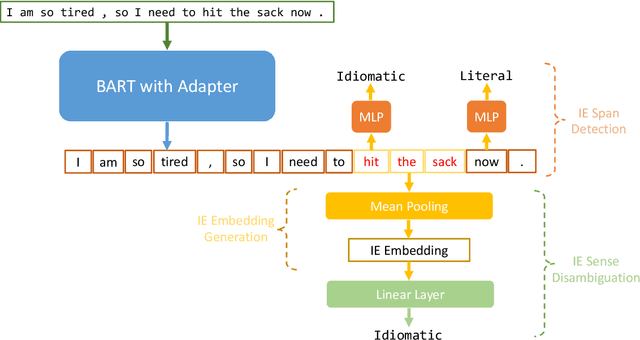
Idiomatic expressions (IEs), characterized by their non-compositionality, are an important part of natural language. They have been a classical challenge to NLP, including pre-trained language models that drive today's state-of-the-art. Prior work has identified deficiencies in their contextualized representation stemming from the underlying compositional paradigm of representation. In this work, we take a first-principles approach to build idiomaticity into BART using an adapter as a lightweight non-compositional language expert trained on idiomatic sentences. The improved capability over baselines (e.g., BART) is seen via intrinsic and extrinsic methods, where idiom embeddings score 0.19 points higher in homogeneity score for embedding clustering, and up to 25% higher sequence accuracy on the idiom processing tasks of IE sense disambiguation and span detection.
Idiomatic Expression Paraphrasing without Strong Supervision
Dec 16, 2021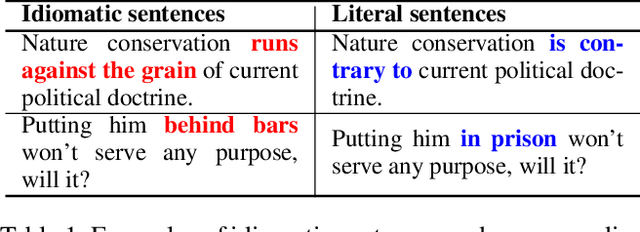
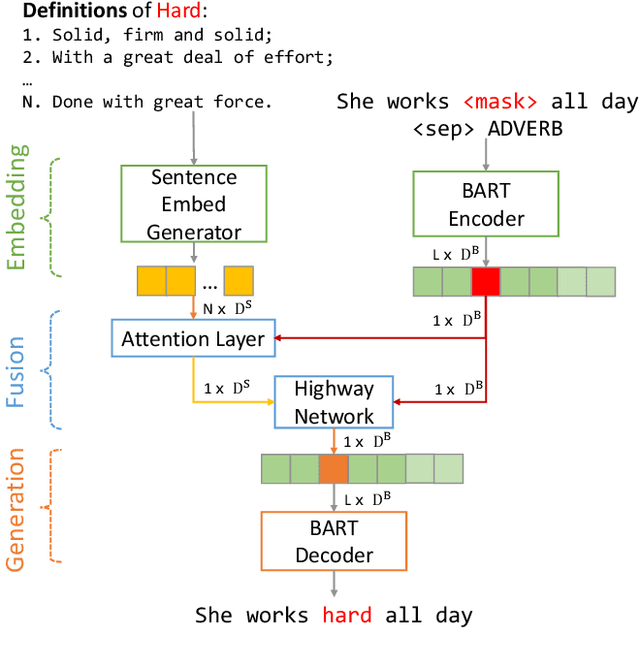
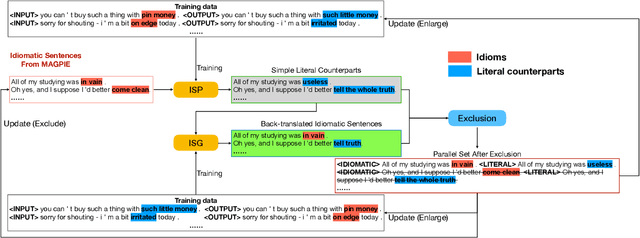
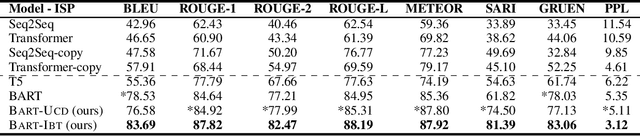
Idiomatic expressions (IEs) play an essential role in natural language. In this paper, we study the task of idiomatic sentence paraphrasing (ISP), which aims to paraphrase a sentence with an IE by replacing the IE with its literal paraphrase. The lack of large-scale corpora with idiomatic-literal parallel sentences is a primary challenge for this task, for which we consider two separate solutions. First, we propose an unsupervised approach to ISP, which leverages an IE's contextual information and definition and does not require a parallel sentence training set. Second, we propose a weakly supervised approach using back-translation to jointly perform paraphrasing and generation of sentences with IEs to enlarge the small-scale parallel sentence training dataset. Other significant derivatives of the study include a model that replaces a literal phrase in a sentence with an IE to generate an idiomatic expression and a large scale parallel dataset with idiomatic/literal sentence pairs. The effectiveness of the proposed solutions compared to competitive baselines is seen in the relative gains of over 5.16 points in BLEU, over 8.75 points in METEOR, and over 19.57 points in SARI when the generated sentences are empirically validated on a parallel dataset using automatic and manual evaluations. We demonstrate the practical utility of ISP as a preprocessing step in En-De machine translation.
Idiomatic Expression Identification using Semantic Compatibility
Oct 19, 2021
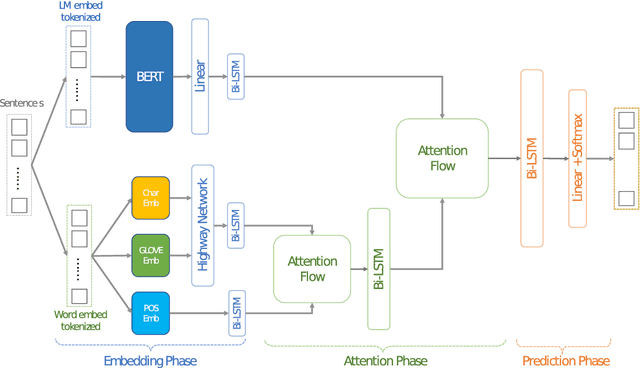
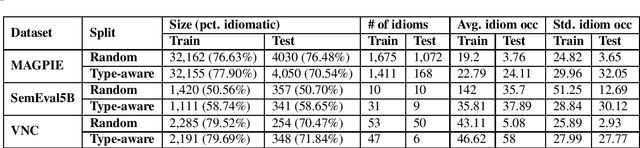
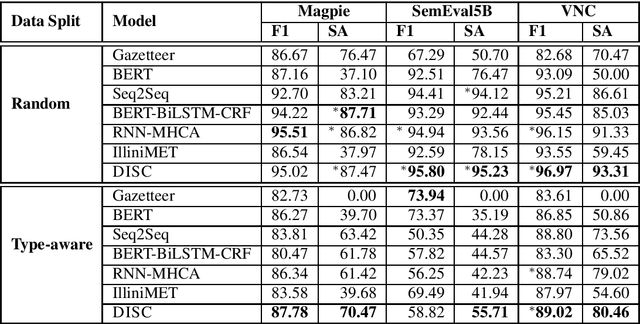
Idiomatic expressions are an integral part of natural language and constantly being added to a language. Owing to their non-compositionality and their ability to take on a figurative or literal meaning depending on the sentential context, they have been a classical challenge for NLP systems. To address this challenge, we study the task of detecting whether a sentence has an idiomatic expression and localizing it. Prior art for this task had studied specific classes of idiomatic expressions offering limited views of their generalizability to new idioms. We propose a multi-stage neural architecture with the attention flow mechanism for identifying these expressions. The network effectively fuses contextual and lexical information at different levels using word and sub-word representations. Empirical evaluations on three of the largest benchmark datasets with idiomatic expressions of varied syntactic patterns and degrees of non-compositionality show that our proposed model achieves new state-of-the-art results. A salient feature of the model is its ability to identify idioms unseen during training with gains from 1.4% to 30.8% over competitive baselines on the largest dataset.
Euphemistic Phrase Detection by Masked Language Model
Sep 10, 2021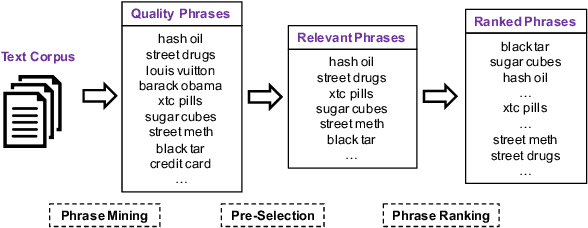
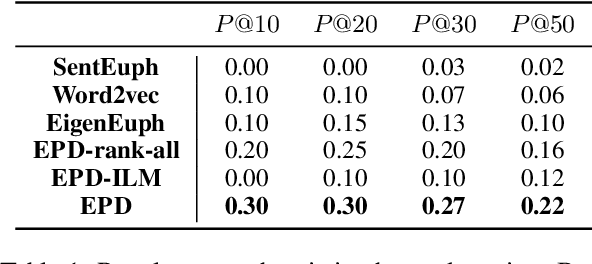


It is a well-known approach for fringe groups and organizations to use euphemisms -- ordinary-sounding and innocent-looking words with a secret meaning -- to conceal what they are discussing. For instance, drug dealers often use "pot" for marijuana and "avocado" for heroin. From a social media content moderation perspective, though recent advances in NLP have enabled the automatic detection of such single-word euphemisms, no existing work is capable of automatically detecting multi-word euphemisms, such as "blue dream" (marijuana) and "black tar" (heroin). Our paper tackles the problem of euphemistic phrase detection without human effort for the first time, as far as we are aware. We first perform phrase mining on a raw text corpus (e.g., social media posts) to extract quality phrases. Then, we utilize word embedding similarities to select a set of euphemistic phrase candidates. Finally, we rank those candidates by a masked language model -- SpanBERT. Compared to strong baselines, we report 20-50% higher detection accuracies using our algorithm for detecting euphemistic phrases.
Generate, Prune, Select: A Pipeline for Counterspeech Generation against Online Hate Speech
Jun 03, 2021
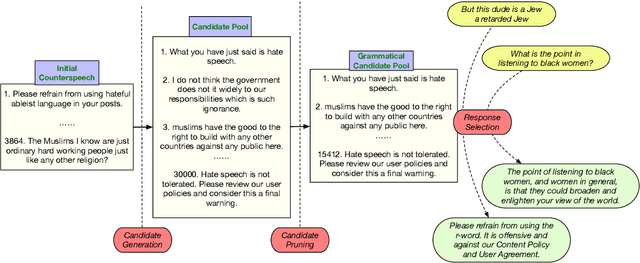
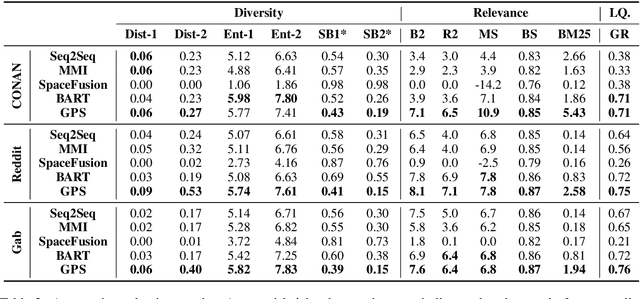
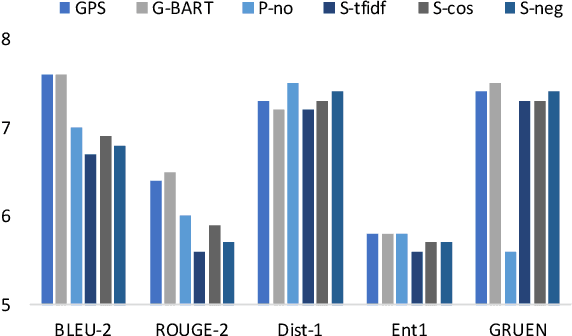
Countermeasures to effectively fight the ever increasing hate speech online without blocking freedom of speech is of great social interest. Natural Language Generation (NLG), is uniquely capable of developing scalable solutions. However, off-the-shelf NLG methods are primarily sequence-to-sequence neural models and they are limited in that they generate commonplace, repetitive and safe responses regardless of the hate speech (e.g., "Please refrain from using such language.") or irrelevant responses, making them ineffective for de-escalating hateful conversations. In this paper, we design a three-module pipeline approach to effectively improve the diversity and relevance. Our proposed pipeline first generates various counterspeech candidates by a generative model to promote diversity, then filters the ungrammatical ones using a BERT model, and finally selects the most relevant counterspeech response using a novel retrieval-based method. Extensive Experiments on three representative datasets demonstrate the efficacy of our approach in generating diverse and relevant counterspeech.
Abusive Language Detection in Heterogeneous Contexts: Dataset Collection and the Role of Supervised Attention
May 24, 2021
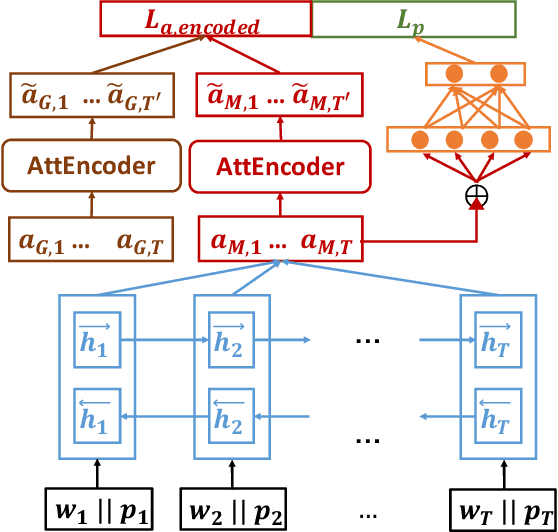
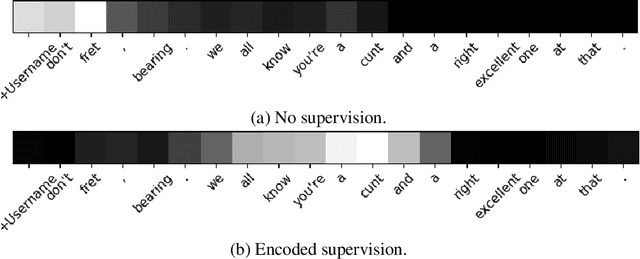

Abusive language is a massive problem in online social platforms. Existing abusive language detection techniques are particularly ill-suited to comments containing heterogeneous abusive language patterns, i.e., both abusive and non-abusive parts. This is due in part to the lack of datasets that explicitly annotate heterogeneity in abusive language. We tackle this challenge by providing an annotated dataset of abusive language in over 11,000 comments from YouTube. We account for heterogeneity in this dataset by separately annotating both the comment as a whole and the individual sentences that comprise each comment. We then propose an algorithm that uses a supervised attention mechanism to detect and categorize abusive content using multi-task learning. We empirically demonstrate the challenges of using traditional techniques on heterogeneous content and the comparative gains in performance of the proposed approach over state-of-the-art methods.