 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbusive Language Detection in Heterogeneous Contexts: Dataset Collection and the Role of Supervised Attention
May 24, 2021
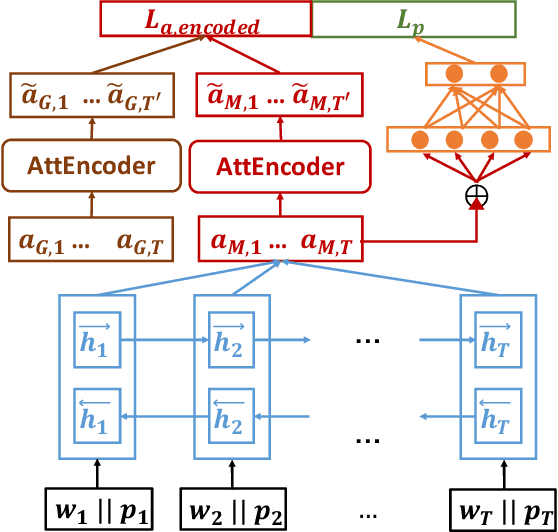
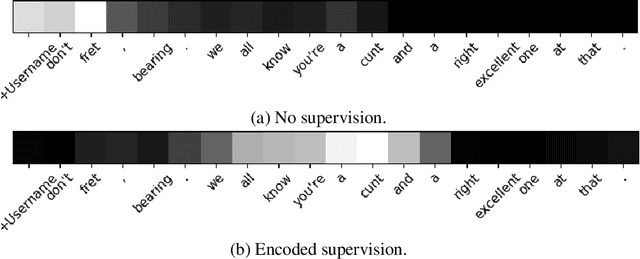

Abusive language is a massive problem in online social platforms. Existing abusive language detection techniques are particularly ill-suited to comments containing heterogeneous abusive language patterns, i.e., both abusive and non-abusive parts. This is due in part to the lack of datasets that explicitly annotate heterogeneity in abusive language. We tackle this challenge by providing an annotated dataset of abusive language in over 11,000 comments from YouTube. We account for heterogeneity in this dataset by separately annotating both the comment as a whole and the individual sentences that comprise each comment. We then propose an algorithm that uses a supervised attention mechanism to detect and categorize abusive content using multi-task learning. We empirically demonstrate the challenges of using traditional techniques on heterogeneous content and the comparative gains in performance of the proposed approach over state-of-the-art methods.