 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyping to Listen at the Cocktail Party: Text-Guided Target Speaker Extraction
Paper and Code
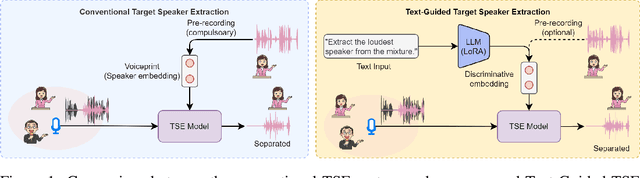
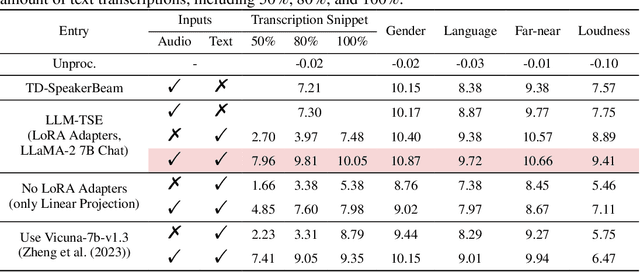
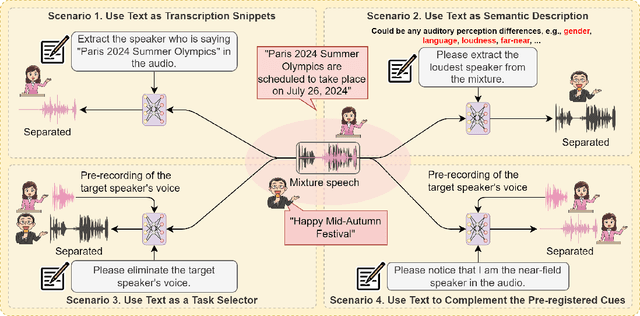
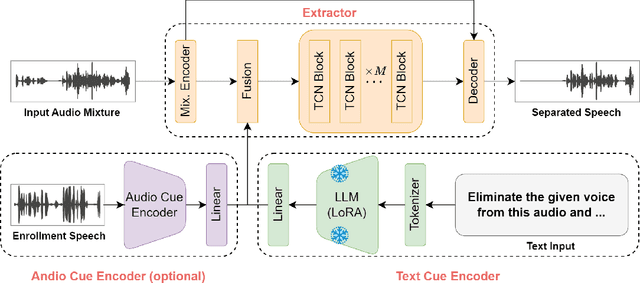
Humans possess an extraordinary ability to selectively focus on the sound source of interest amidst complex acoustic environments, commonly referred to as cocktail party scenarios. In an attempt to replicate this remarkable auditory attention capability in machines, target speaker extraction (TSE) models have been developed. These models leverage the pre-registered cues of the target speaker to extract the sound source of interest. However, the effectiveness of these models is hindered in real-world scenarios due to the unreliable or even absence of pre-registered cues. To address this limitation, this study investigates the integration of natural language description to enhance the feasibility, controllability, and performance of existing TSE models. Specifically, we propose a model named LLM-TSE, wherein a large language model (LLM) extracts useful semantic cues from the user's typed text input. These cues can serve as independent extraction cues, task selectors to control the TSE process or complement the pre-registered cues. Our experimental results demonstrate competitive performance when only text-based cues are presented, the effectiveness of using input text as a task selector, and a new state-of-the-art when combining text-based cues with pre-registered cues. To our knowledge, this is the first study to successfully incorporate LLMs to guide target speaker extraction, which can be a cornerstone for cocktail party problem research.