 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRR-Judge: Step-Level Rating and Refinement for Enhancing Search-Integrated Reasoning in Search Agents
Feb 08, 2026Recent deep search agents built on large reasoning models (LRMs) excel at complex question answering by iteratively planning, acting, and gathering evidence, a capability known as search-integrated reasoning. However, mainstream approaches often train this ability using only outcome-based supervision, neglecting the quality of intermediate thoughts and actions. We introduce SRR-Judge, a framework for reliable step-level assessment of reasoning and search actions. Integrated into a modified ReAct-style rate-and-refine workflow, SRR-Judge provides fine-grained guidance for search-integrated reasoning and enables efficient post-training annotation. Using SRR-annotated data, we apply an iterative rejection sampling fine-tuning procedure to enhance the deep search capability of the base agent. Empirically, SRR-Judge delivers more reliable step-level evaluations than much larger models such as DeepSeek-V3.1, with its ratings showing strong correlation with final answer correctness. Moreover, aligning the policy with SRR-Judge annotated trajectories leads to substantial performance gains, yielding over a 10 percent average absolute pass@1 improvement across challenging deep search benchmarks.
The Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation
Jan 27, 2026Recent advances in video generation have produced models capable of synthesizing stunning visual content from simple text prompts. However, these models struggle to generate long-form, coherent narratives from high-level concepts like dialogue, revealing a ``semantic gap'' between a creative idea and its cinematic execution. To bridge this gap, we introduce a novel, end-to-end agentic framework for dialogue-to-cinematic-video generation. Central to our framework is ScripterAgent, a model trained to translate coarse dialogue into a fine-grained, executable cinematic script. To enable this, we construct ScriptBench, a new large-scale benchmark with rich multimodal context, annotated via an expert-guided pipeline. The generated script then guides DirectorAgent, which orchestrates state-of-the-art video models using a cross-scene continuous generation strategy to ensure long-horizon coherence. Our comprehensive evaluation, featuring an AI-powered CriticAgent and a new Visual-Script Alignment (VSA) metric, shows our framework significantly improves script faithfulness and temporal fidelity across all tested video models. Furthermore, our analysis uncovers a crucial trade-off in current SOTA models between visual spectacle and strict script adherence, providing valuable insights for the future of automated filmmaking.
Too Good to be Bad: On the Failure of LLMs to Role-Play Villains
Nov 12, 2025Large Language Models (LLMs) are increasingly tasked with creative generation, including the simulation of fictional characters. However, their ability to portray non-prosocial, antagonistic personas remains largely unexamined. We hypothesize that the safety alignment of modern LLMs creates a fundamental conflict with the task of authentically role-playing morally ambiguous or villainous characters. To investigate this, we introduce the Moral RolePlay benchmark, a new dataset featuring a four-level moral alignment scale and a balanced test set for rigorous evaluation. We task state-of-the-art LLMs with role-playing characters from moral paragons to pure villains. Our large-scale evaluation reveals a consistent, monotonic decline in role-playing fidelity as character morality decreases. We find that models struggle most with traits directly antithetical to safety principles, such as ``Deceitful'' and ``Manipulative'', often substituting nuanced malevolence with superficial aggression. Furthermore, we demonstrate that general chatbot proficiency is a poor predictor of villain role-playing ability, with highly safety-aligned models performing particularly poorly. Our work provides the first systematic evidence of this critical limitation, highlighting a key tension between model safety and creative fidelity. Our benchmark and findings pave the way for developing more nuanced, context-aware alignment methods.
Doc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research
Oct 24, 2025Deep Research systems have revolutionized how LLMs solve complex questions through iterative reasoning and evidence gathering. However, current systems remain fundamentally constrained to textual web data, overlooking the vast knowledge embedded in multimodal documents Processing such documents demands sophisticated parsing to preserve visual semantics (figures, tables, charts, and equations), intelligent chunking to maintain structural coherence, and adaptive retrieval across modalities, which are capabilities absent in existing systems. In response, we present Doc-Researcher, a unified system that bridges this gap through three integrated components: (i) deep multimodal parsing that preserves layout structure and visual semantics while creating multi-granular representations from chunk to document level, (ii) systematic retrieval architecture supporting text-only, vision-only, and hybrid paradigms with dynamic granularity selection, and (iii) iterative multi-agent workflows that decompose complex queries, progressively accumulate evidence, and synthesize comprehensive answers across documents and modalities. To enable rigorous evaluation, we introduce M4DocBench, the first benchmark for Multi-modal, Multi-hop, Multi-document, and Multi-turn deep research. Featuring 158 expert-annotated questions with complete evidence chains across 304 documents, M4DocBench tests capabilities that existing benchmarks cannot assess. Experiments demonstrate that Doc-Researcher achieves 50.6% accuracy, 3.4xbetter than state-of-the-art baselines, validating that effective document research requires not just better retrieval, but fundamentally deep parsing that preserve multimodal integrity and support iterative research. Our work establishes a new paradigm for conducting deep research on multimodal document collections.
BatonVoice: An Operationalist Framework for Enhancing Controllable Speech Synthesis with Linguistic Intelligence from LLMs
Sep 30, 2025The rise of Large Language Models (LLMs) is reshaping multimodel models, with speech synthesis being a prominent application. However, existing approaches often underutilize the linguistic intelligence of these models, typically failing to leverage their powerful instruction-following capabilities. This limitation hinders the model's ability to follow text instructions for controllable Text-to-Speech~(TTS). To address this, we propose a new paradigm inspired by ``operationalism'' that decouples instruction understanding from speech generation. We introduce BatonVoice, a framework where an LLM acts as a ``conductor'', understanding user instructions and generating a textual ``plan'' -- explicit vocal features (e.g., pitch, energy). A separate TTS model, the ``orchestra'', then generates the speech from these features. To realize this component, we develop BatonTTS, a TTS model trained specifically for this task. Our experiments demonstrate that BatonVoice achieves strong performance in controllable and emotional speech synthesis, outperforming strong open- and closed-source baselines. Notably, our approach enables remarkable zero-shot cross-lingual generalization, accurately applying feature control abilities to languages unseen during post-training. This demonstrates that objectifying speech into textual vocal features can more effectively unlock the linguistic intelligence of LLMs.
LoRASculpt: Sculpting LoRA for Harmonizing General and Specialized Knowledge in Multimodal Large Language Models
Mar 21, 2025While Multimodal Large Language Models (MLLMs) excel at generalizing across modalities and tasks, effectively adapting them to specific downstream tasks while simultaneously retaining both general and specialized knowledge remains challenging. Although Low-Rank Adaptation (LoRA) is widely used to efficiently acquire specialized knowledge in MLLMs, it introduces substantial harmful redundancy during visual instruction tuning, which exacerbates the forgetting of general knowledge and degrades downstream task performance. To address this issue, we propose LoRASculpt to eliminate harmful redundant parameters, thereby harmonizing general and specialized knowledge. Specifically, under theoretical guarantees, we introduce sparse updates into LoRA to discard redundant parameters effectively. Furthermore, we propose a Conflict Mitigation Regularizer to refine the update trajectory of LoRA, mitigating knowledge conflicts with the pretrained weights. Extensive experimental results demonstrate that even at very high degree of sparsity ($\le$ 5%), our method simultaneously enhances generalization and downstream task performance. This confirms that our approach effectively mitigates the catastrophic forgetting issue and further promotes knowledge harmonization in MLLMs.
Spiking Neural Networks for Temporal Processing: Status Quo and Future Prospects
Feb 13, 2025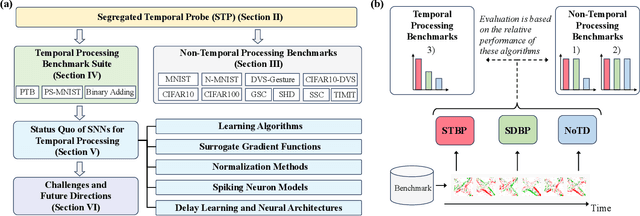
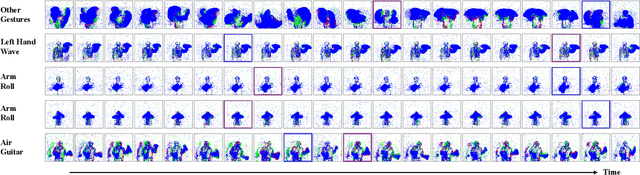

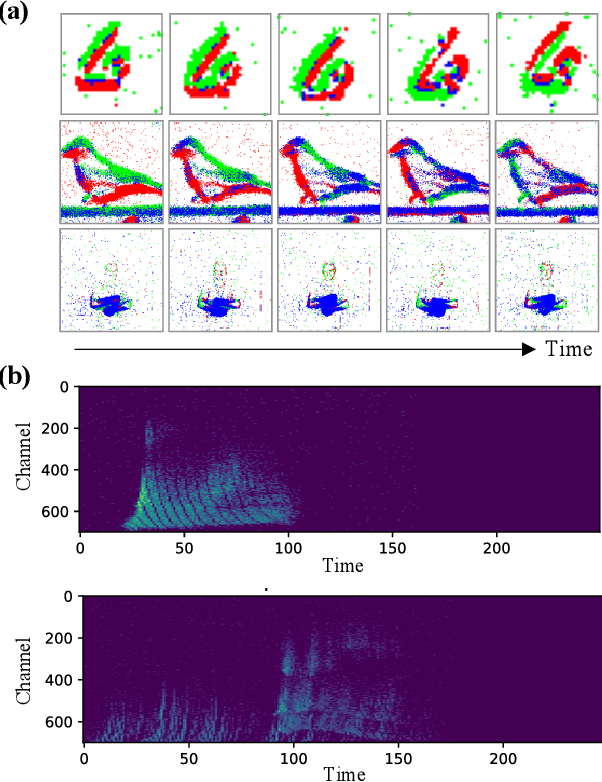
Temporal processing is fundamental for both biological and artificial intelligence systems, as it enables the comprehension of dynamic environments and facilitates timely responses. Spiking Neural Networks (SNNs) excel in handling such data with high efficiency, owing to their rich neuronal dynamics and sparse activity patterns. Given the recent surge in the development of SNNs, there is an urgent need for a comprehensive evaluation of their temporal processing capabilities. In this paper, we first conduct an in-depth assessment of commonly used neuromorphic benchmarks, revealing critical limitations in their ability to evaluate the temporal processing capabilities of SNNs. To bridge this gap, we further introduce a benchmark suite consisting of three temporal processing tasks characterized by rich temporal dynamics across multiple timescales. Utilizing this benchmark suite, we perform a thorough evaluation of recently introduced SNN approaches to elucidate the current status of SNNs in temporal processing. Our findings indicate significant advancements in recently developed spiking neuron models and neural architectures regarding their temporal processing capabilities, while also highlighting a performance gap in handling long-range dependencies when compared to state-of-the-art non-spiking models. Finally, we discuss the key challenges and outline potential avenues for future research.
A Survey on Multi-Turn Interaction Capabilities of Large Language Models
Jan 17, 2025Multi-turn interaction in the dialogue system research refers to a system's ability to maintain context across multiple dialogue turns, enabling it to generate coherent and contextually relevant responses. Recent advancements in large language models (LLMs) have significantly expanded the scope of multi-turn interaction, moving beyond chatbots to enable more dynamic agentic interactions with users or environments. In this paper, we provide a focused review of the multi-turn capabilities of LLMs, which are critical for a wide range of downstream applications, including conversational search and recommendation, consultation services, and interactive tutoring. This survey explores four key aspects: (1) the core model capabilities that contribute to effective multi-turn interaction, (2) how multi-turn interaction is evaluated in current practice, (3) the general algorithms used to enhance multi-turn interaction, and (4) potential future directions for research in this field.
Towards Ultra-Low-Power Neuromorphic Speech Enhancement with Spiking-FullSubNet
Oct 07, 2024



Speech enhancement is critical for improving speech intelligibility and quality in various audio devices. In recent years, deep learning-based methods have significantly improved speech enhancement performance, but they often come with a high computational cost, which is prohibitive for a large number of edge devices, such as headsets and hearing aids. This work proposes an ultra-low-power speech enhancement system based on the brain-inspired spiking neural network (SNN) called Spiking-FullSubNet. Spiking-FullSubNet follows a full-band and sub-band fusioned approach to effectively capture both global and local spectral information. To enhance the efficiency of computationally expensive sub-band modeling, we introduce a frequency partitioning method inspired by the sensitivity profile of the human peripheral auditory system. Furthermore, we introduce a novel spiking neuron model that can dynamically control the input information integration and forgetting, enhancing the multi-scale temporal processing capability of SNN, which is critical for speech denoising. Experiments conducted on the recent Intel Neuromorphic Deep Noise Suppression (N-DNS) Challenge dataset show that the Spiking-FullSubNet surpasses state-of-the-art methods by large margins in terms of both speech quality and energy efficiency metrics. Notably, our system won the championship of the Intel N-DNS Challenge (Algorithmic Track), opening up a myriad of opportunities for ultra-low-power speech enhancement at the edge. Our source code and model checkpoints are publicly available at https://github.com/haoxiangsnr/spiking-fullsubnet.
EmoLLM: Multimodal Emotional Understanding Meets Large Language Models
Jun 24, 2024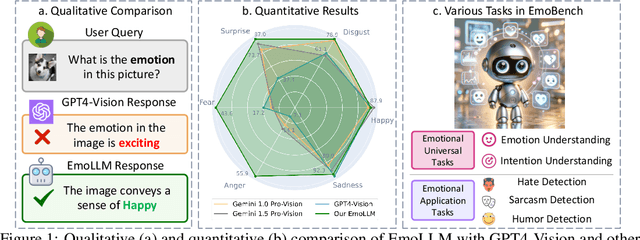
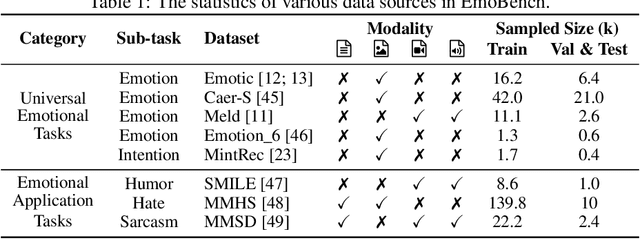
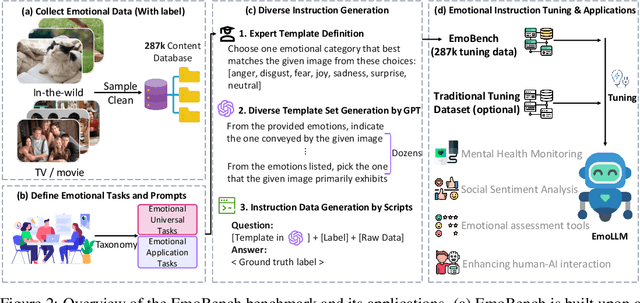
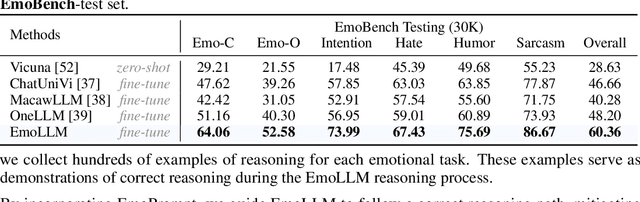
Multi-modal large language models (MLLMs) have achieved remarkable performance on objective multimodal perception tasks, but their ability to interpret subjective, emotionally nuanced multimodal content remains largely unexplored. Thus, it impedes their ability to effectively understand and react to the intricate emotions expressed by humans through multimodal media. To bridge this gap, we introduce EmoBench, the first comprehensive benchmark designed specifically to evaluate the emotional capabilities of MLLMs across five popular emotional tasks, using a diverse dataset of 287k images and videos paired with corresponding textual instructions. Meanwhile, we propose EmoLLM, a novel model for multimodal emotional understanding, incorporating with two core techniques. 1) Multi-perspective Visual Projection, it captures diverse emotional cues from visual data from multiple perspectives. 2) EmoPrompt, it guides MLLMs to reason about emotions in the correct direction. Experimental results demonstrate that EmoLLM significantly elevates multimodal emotional understanding performance, with an average improvement of 12.1% across multiple foundation models on EmoBench. Our work contributes to the advancement of MLLMs by facilitating a deeper and more nuanced comprehension of intricate human emotions, paving the way for the development of artificial emotional intelligence capabilities with wide-ranging applications in areas such as human-computer interaction, mental health support, and empathetic AI systems. Code, data, and model will be released.