 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIML-Spikeformer: Input-aware Multi-Level Spiking Transformer for Speech Processing
Jul 10, 2025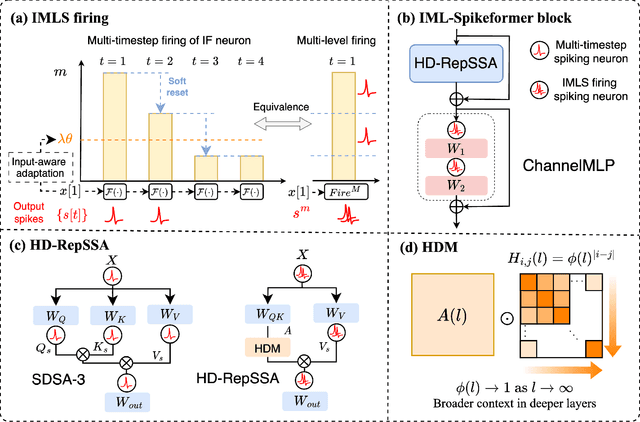
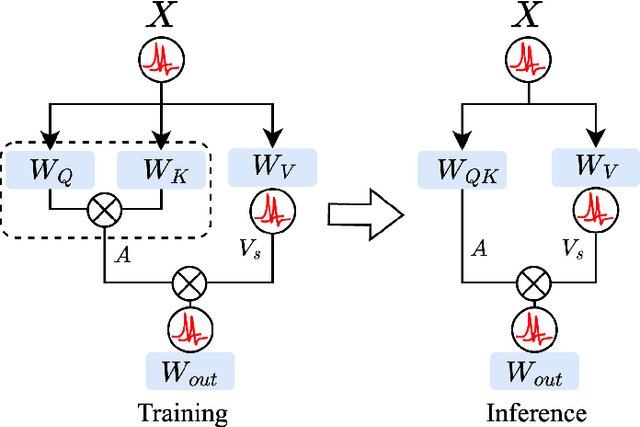
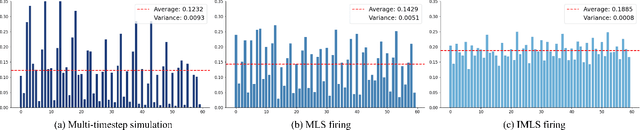
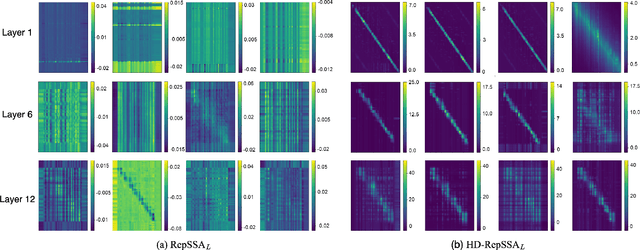
Spiking Neural Networks (SNNs), inspired by biological neural mechanisms, represent a promising neuromorphic computing paradigm that offers energy-efficient alternatives to traditional Artificial Neural Networks (ANNs). Despite proven effectiveness, SNN architectures have struggled to achieve competitive performance on large-scale speech processing task. Two key challenges hinder progress: (1) the high computational overhead during training caused by multi-timestep spike firing, and (2) the absence of large-scale SNN architectures tailored to speech processing tasks. To overcome the issues, we introduce Input-aware Multi-Level Spikeformer, i.e. IML-Spikeformer, a spiking Transformer architecture specifically designed for large-scale speech processing. Central to our design is the Input-aware Multi-Level Spike (IMLS) mechanism, which simulate multi-timestep spike firing within a single timestep using an adaptive, input-aware thresholding scheme. IML-Spikeformer further integrates a Reparameterized Spiking Self-Attention (RepSSA) module with a Hierarchical Decay Mask (HDM), forming the HD-RepSSA module. This module enhances the precision of attention maps and enables modeling of multi-scale temporal dependencies in speech signals. Experiments demonstrate that IML-Spikeformer achieves word error rates of 6.0\% on AiShell-1 and 3.4\% on Librispeech-960, comparable to conventional ANN transformers while reducing theoretical inference energy consumption by 4.64$\times$ and 4.32$\times$ respectively. IML-Spikeformer marks an advance of scalable SNN architectures for large-scale speech processing in both task performance and energy efficiency.
ED-sKWS: Early-Decision Spiking Neural Networks for Rapid,and Energy-Efficient Keyword Spotting
Jun 14, 2024Keyword Spotting (KWS) is essential in edge computing requiring rapid and energy-efficient responses. Spiking Neural Networks (SNNs) are well-suited for KWS for their efficiency and temporal capacity for speech. To further reduce the latency and energy consumption, this study introduces ED-sKWS, an SNN-based KWS model with an early-decision mechanism that can stop speech processing and output the result before the end of speech utterance. Furthermore, we introduce a Cumulative Temporal (CT) loss that can enhance prediction accuracy at both the intermediate and final timesteps. To evaluate early-decision performance, we present the SC-100 dataset including 100 speech commands with beginning and end timestamp annotation. Experiments on the Google Speech Commands v2 and our SC-100 datasets show that ED-sKWS maintains competitive accuracy with 61% timesteps and 52% energy consumption compared to SNN models without early-decision mechanism, ensuring rapid response and energy efficiency.
sVAD: A Robust, Low-Power, and Light-Weight Voice Activity Detection with Spiking Neural Networks
Mar 09, 2024Speech applications are expected to be low-power and robust under noisy conditions. An effective Voice Activity Detection (VAD) front-end lowers the computational need. Spiking Neural Networks (SNNs) are known to be biologically plausible and power-efficient. However, SNN-based VADs have yet to achieve noise robustness and often require large models for high performance. This paper introduces a novel SNN-based VAD model, referred to as sVAD, which features an auditory encoder with an SNN-based attention mechanism. Particularly, it provides effective auditory feature representation through SincNet and 1D convolution, and improves noise robustness with attention mechanisms. The classifier utilizes Spiking Recurrent Neural Networks (sRNN) to exploit temporal speech information. Experimental results demonstrate that our sVAD achieves remarkable noise robustness and meanwhile maintains low power consumption and a small footprint, making it a promising solution for real-world VAD applications.
Spiking-LEAF: A Learnable Auditory front-end for Spiking Neural Networks
Sep 18, 2023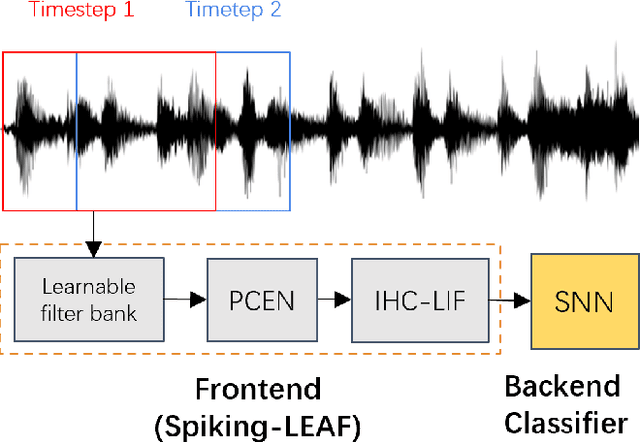
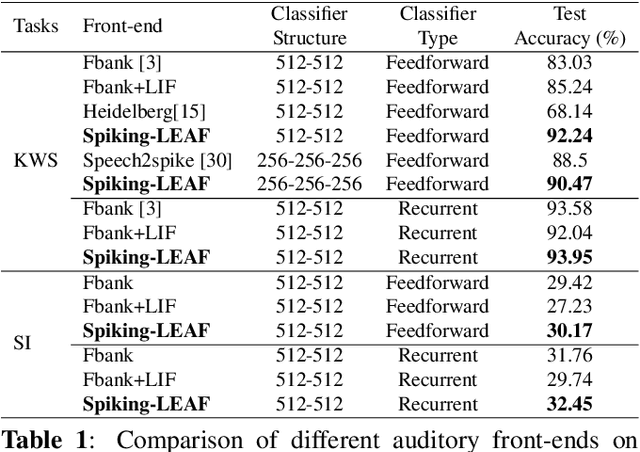
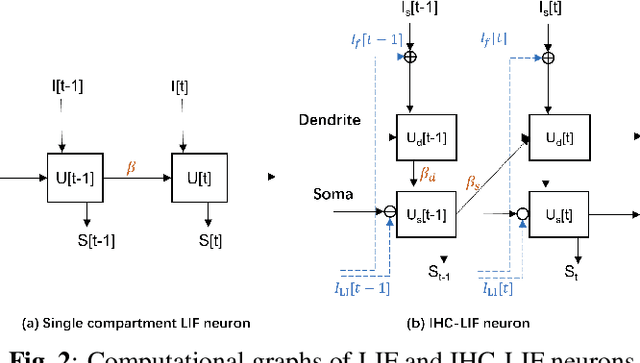

Brain-inspired spiking neural networks (SNNs) have demonstrated great potential for temporal signal processing. However, their performance in speech processing remains limited due to the lack of an effective auditory front-end. To address this limitation, we introduce Spiking-LEAF, a learnable auditory front-end meticulously designed for SNN-based speech processing. Spiking-LEAF combines a learnable filter bank with a novel two-compartment spiking neuron model called IHC-LIF. The IHC-LIF neurons draw inspiration from the structure of inner hair cells (IHC) and they leverage segregated dendritic and somatic compartments to effectively capture multi-scale temporal dynamics of speech signals. Additionally, the IHC-LIF neurons incorporate the lateral feedback mechanism along with spike regularization loss to enhance spike encoding efficiency. On keyword spotting and speaker identification tasks, the proposed Spiking-LEAF outperforms both SOTA spiking auditory front-ends and conventional real-valued acoustic features in terms of classification accuracy, noise robustness, and encoding efficiency.
AVA-AVD: Audio-visual Speaker Diarization in the Wild
Dec 06, 2021

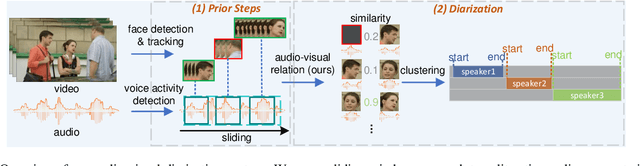
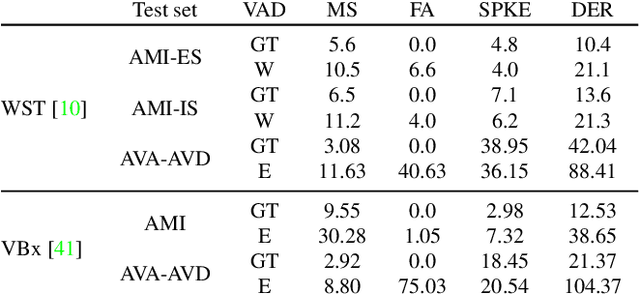
Audio-visual speaker diarization aims at detecting ``who spoken when`` using both auditory and visual signals. Existing audio-visual diarization datasets are mainly focused on indoor environments like meeting rooms or news studios, which are quite different from in-the-wild videos in many scenarios such as movies, documentaries, and audience sitcoms. To create a testbed that can effectively compare diarization methods on videos in the wild, we annotate the speaker diarization labels on the AVA movie dataset and create a new benchmark called AVA-AVD. This benchmark is challenging due to the diverse scenes, complicated acoustic conditions, and completely off-screen speakers. Yet, how to deal with off-screen and on-screen speakers together still remains a critical challenge. To overcome it, we propose a novel Audio-Visual Relation Network (AVR-Net) which introduces an effective modality mask to capture discriminative information based on visibility. Experiments have shown that our method not only can outperform state-of-the-art methods but also is more robust as varying the ratio of off-screen speakers. Ablation studies demonstrate the advantages of the proposed AVR-Net and especially the modality mask on diarization. Our data and code will be made publicly available at https://github.com/zcxu-eric/AVA-AVD.
Unsupervised data augmentation for object detection
Apr 30, 2021
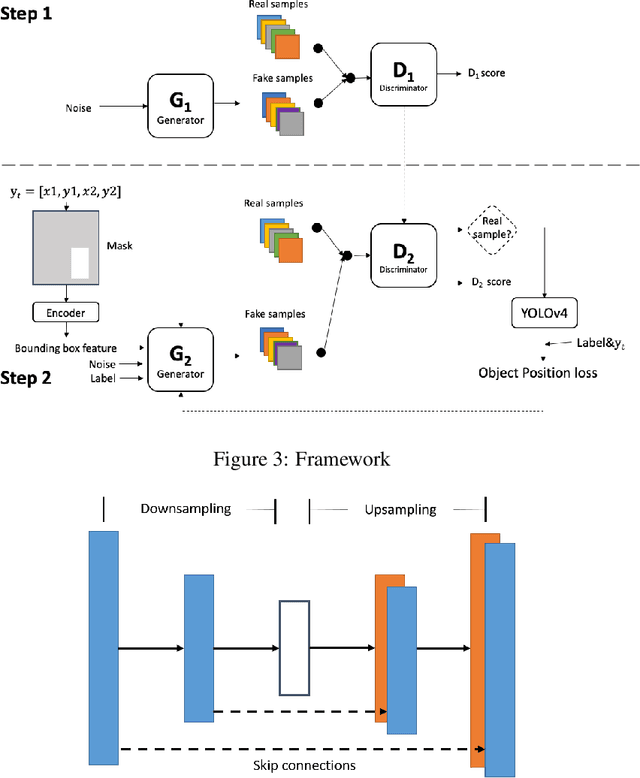


Data augmentation has always been an effective way to overcome overfitting issue when the dataset is small. There are already lots of augmentation operations such as horizontal flip, random crop or even Mixup. However, unlike image classification task, we cannot simply perform these operations for object detection task because of the lack of labeled bounding boxes information for corresponding generated images. To address this challenge, we propose a framework making use of Generative Adversarial Networks(GAN) to perform unsupervised data augmentation. To be specific, based on the recently supreme performance of YOLOv4, we propose a two-step pipeline that enables us to generate an image where the object lies in a certain position. In this way, we can accomplish the goal that generating an image with bounding box label.