 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVA-AVD: Audio-visual Speaker Diarization in the Wild
Paper and Code


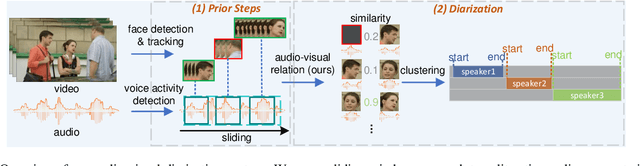
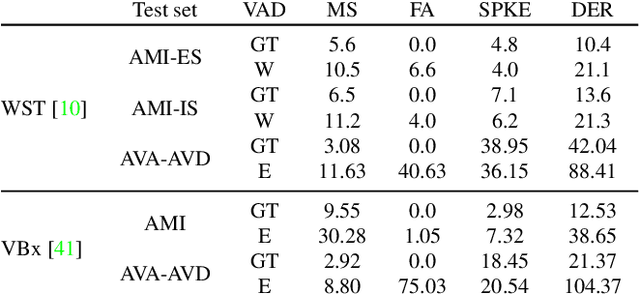
Audio-visual speaker diarization aims at detecting ``who spoken when`` using both auditory and visual signals. Existing audio-visual diarization datasets are mainly focused on indoor environments like meeting rooms or news studios, which are quite different from in-the-wild videos in many scenarios such as movies, documentaries, and audience sitcoms. To create a testbed that can effectively compare diarization methods on videos in the wild, we annotate the speaker diarization labels on the AVA movie dataset and create a new benchmark called AVA-AVD. This benchmark is challenging due to the diverse scenes, complicated acoustic conditions, and completely off-screen speakers. Yet, how to deal with off-screen and on-screen speakers together still remains a critical challenge. To overcome it, we propose a novel Audio-Visual Relation Network (AVR-Net) which introduces an effective modality mask to capture discriminative information based on visibility. Experiments have shown that our method not only can outperform state-of-the-art methods but also is more robust as varying the ratio of off-screen speakers. Ablation studies demonstrate the advantages of the proposed AVR-Net and especially the modality mask on diarization. Our data and code will be made publicly available at https://github.com/zcxu-eric/AVA-AVD.