 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Neural Networks for Temporal Processing: Status Quo and Future Prospects
Feb 13, 2025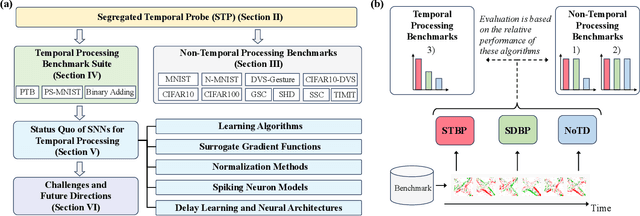

Temporal processing is fundamental for both biological and artificial intelligence systems, as it enables the comprehension of dynamic environments and facilitates timely responses. Spiking Neural Networks (SNNs) excel in handling such data with high efficiency, owing to their rich neuronal dynamics and sparse activity patterns. Given the recent surge in the development of SNNs, there is an urgent need for a comprehensive evaluation of their temporal processing capabilities. In this paper, we first conduct an in-depth assessment of commonly used neuromorphic benchmarks, revealing critical limitations in their ability to evaluate the temporal processing capabilities of SNNs. To bridge this gap, we further introduce a benchmark suite consisting of three temporal processing tasks characterized by rich temporal dynamics across multiple timescales. Utilizing this benchmark suite, we perform a thorough evaluation of recently introduced SNN approaches to elucidate the current status of SNNs in temporal processing. Our findings indicate significant advancements in recently developed spiking neuron models and neural architectures regarding their temporal processing capabilities, while also highlighting a performance gap in handling long-range dependencies when compared to state-of-the-art non-spiking models. Finally, we discuss the key challenges and outline potential avenues for future research.
Towards Scalable GPU-Accelerated SNN Training via Temporal Fusion
Aug 01, 2024



Drawing on the intricate structures of the brain, Spiking Neural Networks (SNNs) emerge as a transformative development in artificial intelligence, closely emulating the complex dynamics of biological neural networks. While SNNs show promising efficiency on specialized sparse-computational hardware, their practical training often relies on conventional GPUs. This reliance frequently leads to extended computation times when contrasted with traditional Artificial Neural Networks (ANNs), presenting significant hurdles for advancing SNN research. To navigate this challenge, we present a novel temporal fusion method, specifically designed to expedite the propagation dynamics of SNNs on GPU platforms, which serves as an enhancement to the current significant approaches for handling deep learning tasks with SNNs. This method underwent thorough validation through extensive experiments in both authentic training scenarios and idealized conditions, confirming its efficacy and adaptability for single and multi-GPU systems. Benchmarked against various existing SNN libraries/implementations, our method achieved accelerations ranging from $5\times$ to $40\times$ on NVIDIA A100 GPUs. Publicly available experimental codes can be found at https://github.com/EMI-Group/snn-temporal-fusion.
A One-Shot Reparameterization Method for Reducing the Loss of Tile Pruning on DNNs
Jul 29, 2022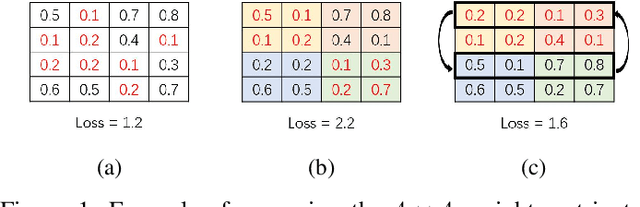
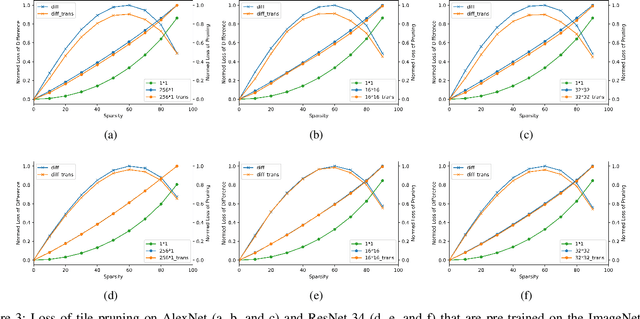
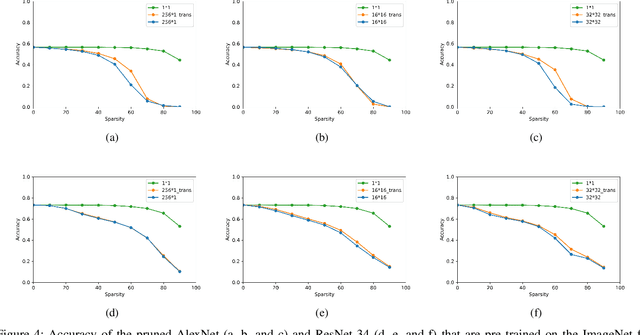
Recently, tile pruning has been widely studied to accelerate the inference of deep neural networks (DNNs). However, we found that the loss due to tile pruning, which can eliminate important elements together with unimportant elements, is large on trained DNNs. In this study, we propose a one-shot reparameterization method, called TileTrans, to reduce the loss of tile pruning. Specifically, we repermute the rows or columns of the weight matrix such that the model architecture can be kept unchanged after reparameterization. This repermutation realizes the reparameterization of the DNN model without any retraining. The proposed reparameterization method combines important elements into the same tile; thus, preserving the important elements after the tile pruning. Furthermore, TileTrans can be seamlessly integrated into existing tile pruning methods because it is a pre-processing method executed before pruning, which is orthogonal to most existing methods. The experimental results demonstrate that our method is essential in reducing the loss of tile pruning on DNNs. Specifically, the accuracy is improved by up to 17% for AlexNet while 5% for ResNet-34, where both models are pre-trained on ImageNet.