 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Oversampling for Imbalanced Data via Majority-Guided VAE
Feb 14, 2023



Learning with imbalanced data is a challenging problem in deep learning. Over-sampling is a widely used technique to re-balance the sampling distribution of training data. However, most existing over-sampling methods only use intra-class information of minority classes to augment the data but ignore the inter-class relationships with the majority ones, which is prone to overfitting, especially when the imbalance ratio is large. To address this issue, we propose a novel over-sampling model, called Majority-Guided VAE~(MGVAE), which generates new minority samples under the guidance of a majority-based prior. In this way, the newly generated minority samples can inherit the diversity and richness of the majority ones, thus mitigating overfitting in downstream tasks. Furthermore, to prevent model collapse under limited data, we first pre-train MGVAE on sufficient majority samples and then fine-tune based on minority samples with Elastic Weight Consolidation(EWC) regularization. Experimental results on benchmark image datasets and real-world tabular data show that MGVAE achieves competitive improvements over other over-sampling methods in downstream classification tasks, demonstrating the effectiveness of our method.
A One-Shot Reparameterization Method for Reducing the Loss of Tile Pruning on DNNs
Jul 29, 2022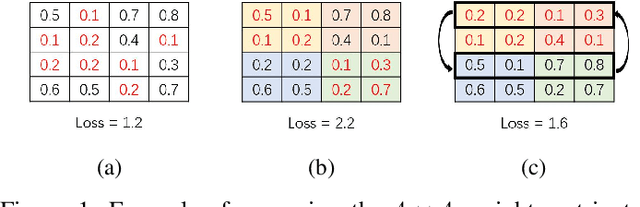
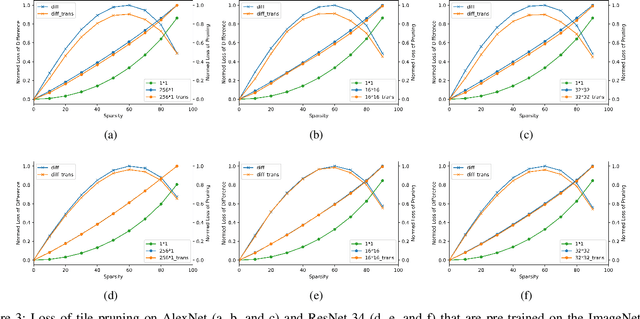
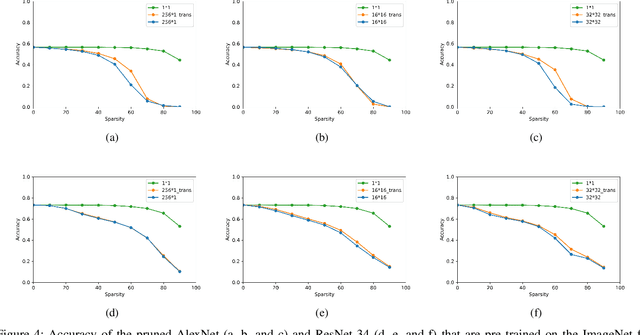
Recently, tile pruning has been widely studied to accelerate the inference of deep neural networks (DNNs). However, we found that the loss due to tile pruning, which can eliminate important elements together with unimportant elements, is large on trained DNNs. In this study, we propose a one-shot reparameterization method, called TileTrans, to reduce the loss of tile pruning. Specifically, we repermute the rows or columns of the weight matrix such that the model architecture can be kept unchanged after reparameterization. This repermutation realizes the reparameterization of the DNN model without any retraining. The proposed reparameterization method combines important elements into the same tile; thus, preserving the important elements after the tile pruning. Furthermore, TileTrans can be seamlessly integrated into existing tile pruning methods because it is a pre-processing method executed before pruning, which is orthogonal to most existing methods. The experimental results demonstrate that our method is essential in reducing the loss of tile pruning on DNNs. Specifically, the accuracy is improved by up to 17% for AlexNet while 5% for ResNet-34, where both models are pre-trained on ImageNet.
ByPE-VAE: Bayesian Pseudocoresets Exemplar VAE
Jul 30, 2021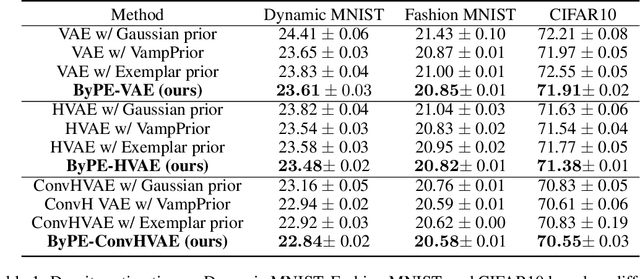
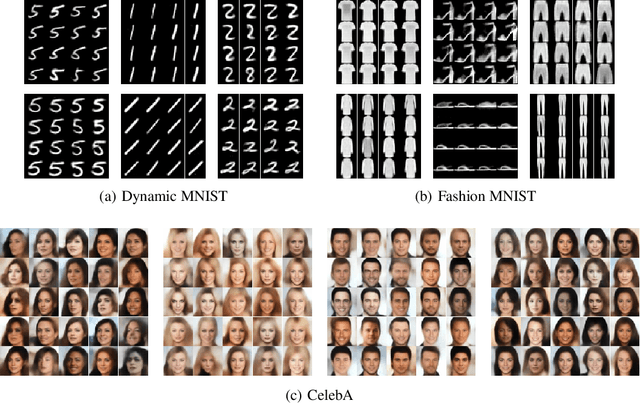


Recent studies show that advanced priors play a major role in deep generative models. Exemplar VAE, as a variant of VAE with an exemplar-based prior, has achieved impressive results. However, due to the nature of model design, an exemplar-based model usually requires vast amounts of data to participate in training, which leads to huge computational complexity. To address this issue, we propose Bayesian Pseudocoresets Exemplar VAE (ByPE-VAE), a new variant of VAE with a prior based on Bayesian pseudocoreset. The proposed prior is conditioned on a small-scale pseudocoreset rather than the whole dataset for reducing the computational cost and avoiding overfitting. Simultaneously, we obtain the optimal pseudocoreset via a stochastic optimization algorithm during VAE training aiming to minimize the Kullback-Leibler divergence between the prior based on the pseudocoreset and that based on the whole dataset. Experimental results show that ByPE-VAE can achieve competitive improvements over the state-of-the-art VAEs in the tasks of density estimation, representation learning, and generative data augmentation. Particularly, on a basic VAE architecture, ByPE-VAE is up to 3 times faster than Exemplar VAE while almost holding the performance. Code is available at our supplementary materials.
Kernel Selection for Stein Variational Gradient Descent
Jul 20, 2021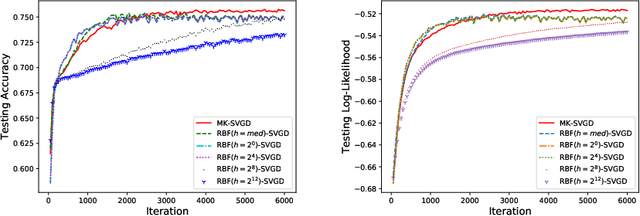
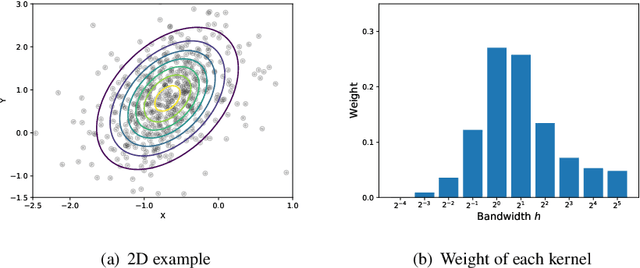

Stein variational gradient descent (SVGD) and its variants have shown promising successes in approximate inference for complex distributions. However, their empirical performance depends crucially on the choice of optimal kernel. Unfortunately, RBF kernel with median heuristics is a common choice in previous approaches which has been proved sub-optimal. Inspired by the paradigm of multiple kernel learning, our solution to this issue is using a combination of multiple kernels to approximate the optimal kernel instead of a single one which may limit the performance and flexibility. To do so, we extend Kernelized Stein Discrepancy (KSD) to its multiple kernel view called Multiple Kernelized Stein Discrepancy (MKSD). Further, we leverage MKSD to construct a general algorithm based on SVGD, which be called Multiple Kernel SVGD (MK-SVGD). Besides, we automatically assign a weight to each kernel without any other parameters. The proposed method not only gets rid of optimal kernel dependence but also maintains computational effectiveness. Experiments on various tasks and models show the effectiveness of our method.