 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Audio Captioning with Encoder-Level Knowledge Distillation
Paper and Code
Jul 19, 2024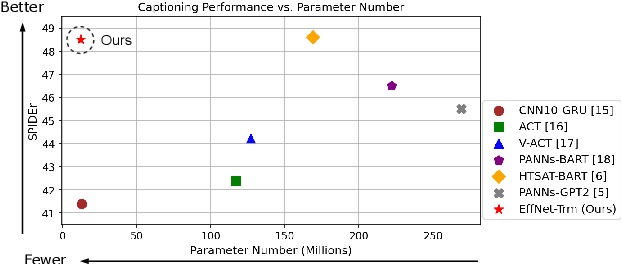

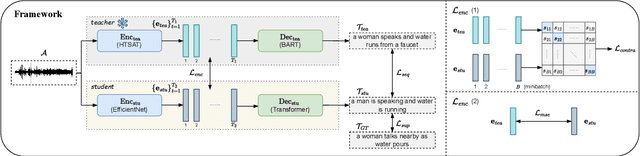
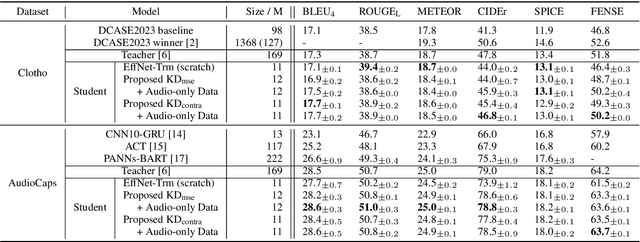
Significant improvement has been achieved in automated audio captioning (AAC) with recent models. However, these models have become increasingly large as their performance is enhanced. In this work, we propose a knowledge distillation (KD) framework for AAC. Our analysis shows that in the encoder-decoder based AAC models, it is more effective to distill knowledge into the encoder as compared with the decoder. To this end, we incorporate encoder-level KD loss into training, in addition to the standard supervised loss and sequence-level KD loss. We investigate two encoder-level KD methods, based on mean squared error (MSE) loss and contrastive loss, respectively. Experimental results demonstrate that contrastive KD is more robust than MSE KD, exhibiting superior performance in data-scarce situations. By leveraging audio-only data into training in the KD framework, our student model achieves competitive performance, with an inference speed that is 19 times faster\footnote{An online demo is available at \url{https://huggingface.co/spaces/wsntxxn/efficient_audio_captioning}}.