 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Data-aware Distance Comparison Operations for High-Dimensional Approximate Nearest Neighbor Search
Paper and Code
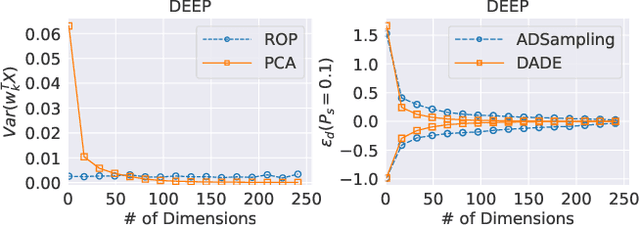
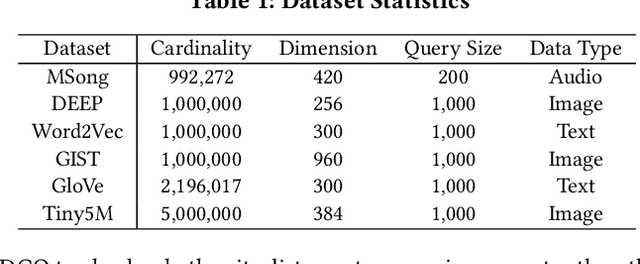
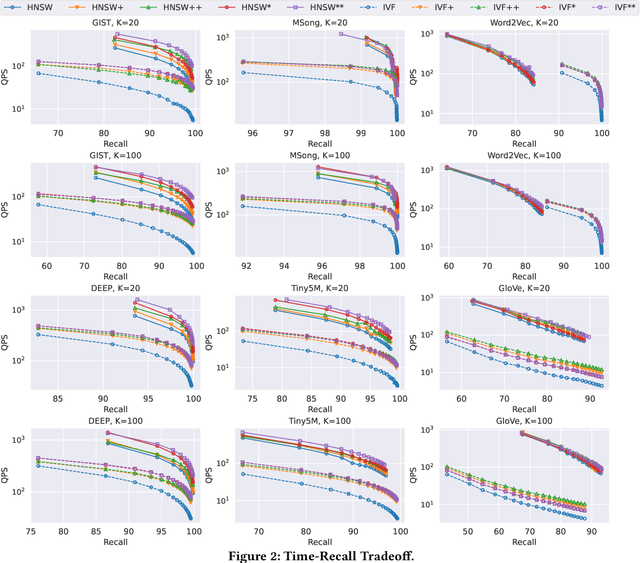
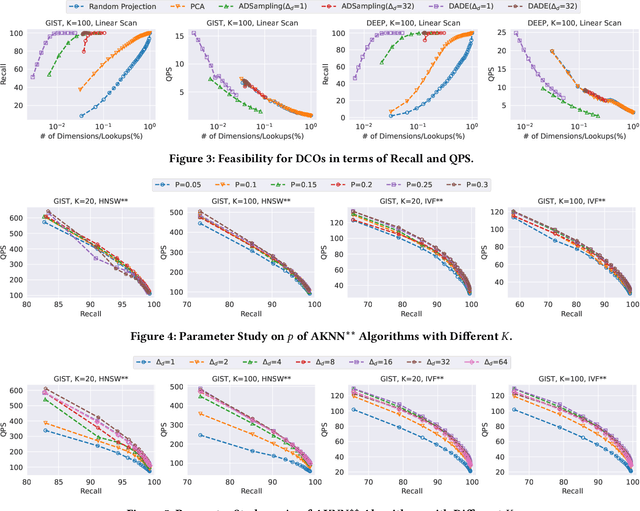
High-dimensional approximate $K$ nearest neighbor search (AKNN) is a fundamental task for various applications, including information retrieval. Most existing algorithms for AKNN can be decomposed into two main components, i.e., candidate generation and distance comparison operations (DCOs). While different methods have unique ways of generating candidates, they all share the same DCO process. In this study, we focus on accelerating the process of DCOs that dominates the time cost in most existing AKNN algorithms. To achieve this, we propose an \underline{D}ata-\underline{A}ware \underline{D}istance \underline{E}stimation approach, called \emph{DADE}, which approximates the \emph{exact} distance in a lower-dimensional space. We theoretically prove that the distance estimation in \emph{DADE} is \emph{unbiased} in terms of data distribution. Furthermore, we propose an optimized estimation based on the unbiased distance estimation formulation. In addition, we propose a hypothesis testing approach to adaptively determine the number of dimensions needed to estimate the \emph{exact} distance with sufficient confidence. We integrate \emph{DADE} into widely-used AKNN search algorithms, e.g., \emph{IVF} and \emph{HNSW}, and conduct extensive experiments to demonstrate the superiority.