 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Replay-based Continuous Learning Framework for Spatio-Temporal Prediction on Streaming Data
Apr 23, 2024


The widespread deployment of wireless and mobile devices results in a proliferation of spatio-temporal data that is used in applications, e.g., traffic prediction, human mobility mining, and air quality prediction, where spatio-temporal prediction is often essential to enable safety, predictability, or reliability. Many recent proposals that target deep learning for spatio-temporal prediction suffer from so-called catastrophic forgetting, where previously learned knowledge is entirely forgotten when new data arrives. Such proposals may experience deteriorating prediction performance when applied in settings where data streams into the system. To enable spatio-temporal prediction on streaming data, we propose a unified replay-based continuous learning framework. The framework includes a replay buffer of previously learned samples that are fused with training data using a spatio-temporal mixup mechanism in order to preserve historical knowledge effectively, thus avoiding catastrophic forgetting. To enable holistic representation preservation, the framework also integrates a general spatio-temporal autoencoder with a carefully designed spatio-temporal simple siamese (STSimSiam) network that aims to ensure prediction accuracy and avoid holistic feature loss by means of mutual information maximization. The framework further encompasses five spatio-temporal data augmentation methods to enhance the performance of STSimSiam. Extensive experiments on real data offer insight into the effectiveness of the proposed framework.
A Pattern Discovery Approach to Multivariate Time Series Forecasting
Dec 20, 2022



Multivariate time series forecasting constitutes important functionality in cyber-physical systems, whose prediction accuracy can be improved significantly by capturing temporal and multivariate correlations among multiple time series. State-of-the-art deep learning methods fail to construct models for full time series because model complexity grows exponentially with time series length. Rather, these methods construct local temporal and multivariate correlations within subsequences, but fail to capture correlations among subsequences, which significantly affect their forecasting accuracy. To capture the temporal and multivariate correlations among subsequences, we design a pattern discovery model, that constructs correlations via diverse pattern functions. While the traditional pattern discovery method uses shared and fixed pattern functions that ignore the diversity across time series. We propose a novel pattern discovery method that can automatically capture diverse and complex time series patterns. We also propose a learnable correlation matrix, that enables the model to capture distinct correlations among multiple time series. Extensive experiments show that our model achieves state-of-the-art prediction accuracy.
A Comparative Study on Unsupervised Anomaly Detection for Time Series: Experiments and Analysis
Sep 10, 2022
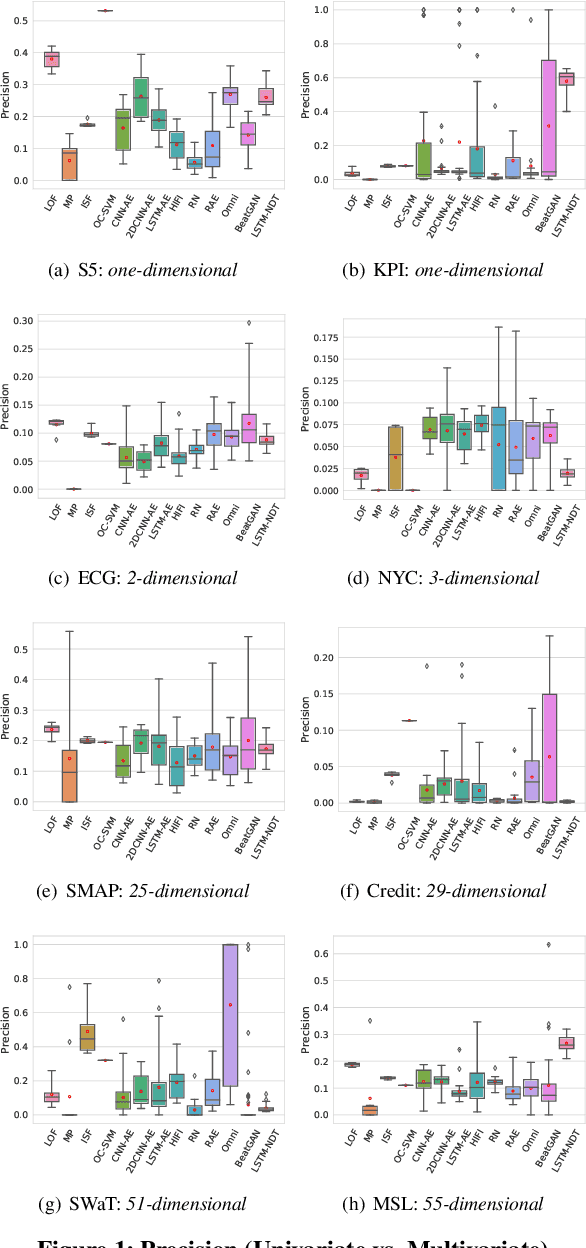
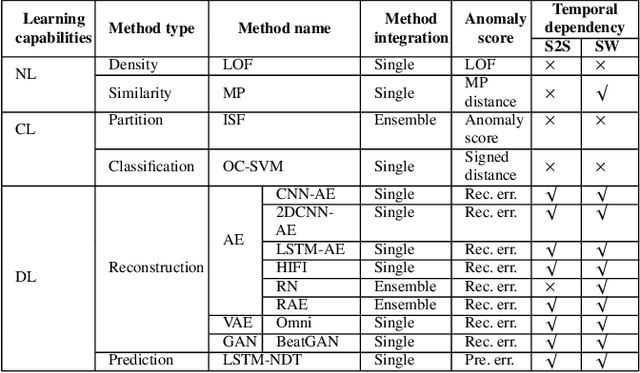

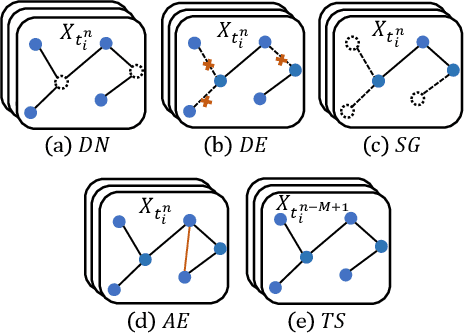
The continued digitization of societal processes translates into a proliferation of time series data that cover applications such as fraud detection, intrusion detection, and energy management, where anomaly detection is often essential to enable reliability and safety. Many recent studies target anomaly detection for time series data. Indeed, area of time series anomaly detection is characterized by diverse data, methods, and evaluation strategies, and comparisons in existing studies consider only part of this diversity, which makes it difficult to select the best method for a particular problem setting. To address this shortcoming, we introduce taxonomies for data, methods, and evaluation strategies, provide a comprehensive overview of unsupervised time series anomaly detection using the taxonomies, and systematically evaluate and compare state-of-the-art traditional as well as deep learning techniques. In the empirical study using nine publicly available datasets, we apply the most commonly-used performance evaluation metrics to typical methods under a fair implementation standard. Based on the structuring offered by the taxonomies, we report on empirical studies and provide guidelines, in the form of comparative tables, for choosing the methods most suitable for particular application settings. Finally, we propose research directions for this dynamic field.
Robust and Explainable Autoencoders for Unsupervised Time Series Outlier Detection---Extended Version
Apr 07, 2022



Time series data occurs widely, and outlier detection is a fundamental problem in data mining, which has numerous applications. Existing autoencoder-based approaches deliver state-of-the-art performance on challenging real-world data but are vulnerable to outliers and exhibit low explainability. To address these two limitations, we propose robust and explainable unsupervised autoencoder frameworks that decompose an input time series into a clean time series and an outlier time series using autoencoders. Improved explainability is achieved because clean time series are better explained with easy-to-understand patterns such as trends and periodicities. We provide insight into this by means of a post-hoc explainability analysis and empirical studies. In addition, since outliers are separated from clean time series iteratively, our approach offers improved robustness to outliers, which in turn improves accuracy. We evaluate our approach on five real-world datasets and report improvements over the state-of-the-art approaches in terms of robustness and explainability. This is an extended version of "Robust and Explainable Autoencoders for Unsupervised Time Series Outlier Detection", to appear in IEEE ICDE 2022.
Unsupervised Time Series Outlier Detection with Diversity-Driven Convolutional Ensembles -- Extended Version
Nov 22, 2021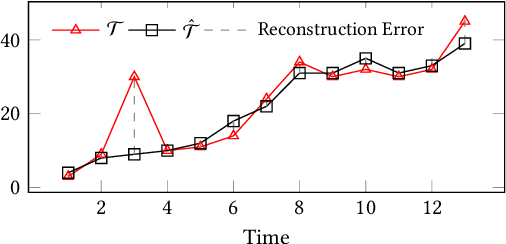
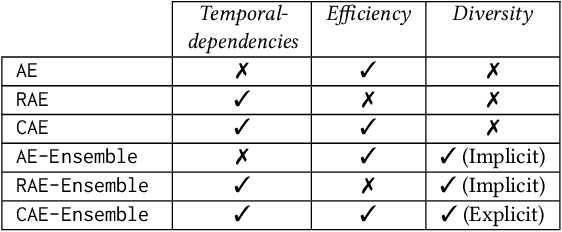


With the sweeping digitalization of societal, medical, industrial, and scientific processes, sensing technologies are being deployed that produce increasing volumes of time series data, thus fueling a plethora of new or improved applications. In this setting, outlier detection is frequently important, and while solutions based on neural networks exist, they leave room for improvement in terms of both accuracy and efficiency. With the objective of achieving such improvements, we propose a diversity-driven, convolutional ensemble. To improve accuracy, the ensemble employs multiple basic outlier detection models built on convolutional sequence-to-sequence autoencoders that can capture temporal dependencies in time series. Further, a novel diversity-driven training method maintains diversity among the basic models, with the aim of improving the ensemble's accuracy. To improve efficiency, the approach enables a high degree of parallelism during training. In addition, it is able to transfer some model parameters from one basic model to another, which reduces training time. We report on extensive experiments using real-world multivariate time series that offer insight into the design choices underlying the new approach and offer evidence that it is capable of improved accuracy and efficiency. This is an extended version of "Unsupervised Time Series Outlier Detection with Diversity-Driven Convolutional Ensembles", to appear in PVLDB 2022.