 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeRe: Towards Efficient Anti-Forgetting in Continual Learning of LLM via General Samples Replay
Aug 06, 2025The continual learning capability of large language models (LLMs) is crucial for advancing artificial general intelligence. However, continual fine-tuning LLMs across various domains often suffers from catastrophic forgetting, characterized by: 1) significant forgetting of their general capabilities, and 2) sharp performance declines in previously learned tasks. To simultaneously address both issues in a simple yet stable manner, we propose General Sample Replay (GeRe), a framework that use usual pretraining texts for efficient anti-forgetting. Beyond revisiting the most prevalent replay-based practices under GeRe, we further leverage neural states to introduce a enhanced activation states constrained optimization method using threshold-based margin (TM) loss, which maintains activation state consistency during replay learning. We are the first to validate that a small, fixed set of pre-collected general replay samples is sufficient to resolve both concerns--retaining general capabilities while promoting overall performance across sequential tasks. Indeed, the former can inherently facilitate the latter. Through controlled experiments, we systematically compare TM with different replay strategies under the GeRe framework, including vanilla label fitting, logit imitation via KL divergence and feature imitation via L1/L2 losses. Results demonstrate that TM consistently improves performance and exhibits better robustness. Our work paves the way for efficient replay of LLMs for the future. Our code and data are available at https://github.com/Qznan/GeRe.
Document Image Rectification Bases on Self-Adaptive Multitask Fusion
May 09, 2025Deformed document image rectification is essential for real-world document understanding tasks, such as layout analysis and text recognition. However, current multi-task methods -- such as background removal, 3D coordinate prediction, and text line segmentation -- often overlook the complementary features between tasks and their interactions. To address this gap, we propose a self-adaptive learnable multi-task fusion rectification network named SalmRec. This network incorporates an inter-task feature aggregation module that adaptively improves the perception of geometric distortions, enhances feature complementarity, and reduces negative interference. We also introduce a gating mechanism to balance features both within global tasks and between local tasks effectively. Experimental results on two English benchmarks (DIR300 and DocUNet) and one Chinese benchmark (DocReal) demonstrate that our method significantly improves rectification performance. Ablation studies further highlight the positive impact of different tasks on dewarping and the effectiveness of our proposed module.
CrossFormer: Cross-Segment Semantic Fusion for Document Segmentation
Apr 02, 2025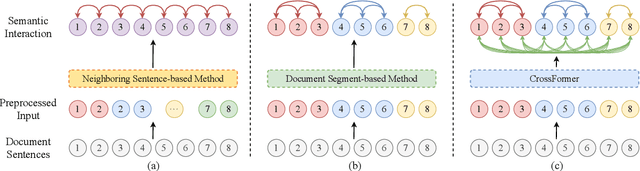
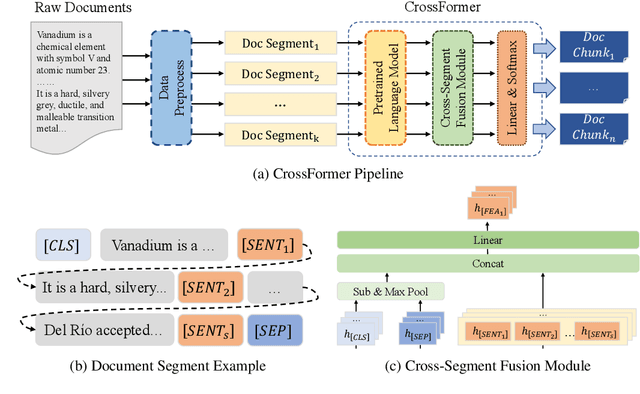
Text semantic segmentation involves partitioning a document into multiple paragraphs with continuous semantics based on the subject matter, contextual information, and document structure. Traditional approaches have typically relied on preprocessing documents into segments to address input length constraints, resulting in the loss of critical semantic information across segments. To address this, we present CrossFormer, a transformer-based model featuring a novel cross-segment fusion module that dynamically models latent semantic dependencies across document segments, substantially elevating segmentation accuracy. Additionally, CrossFormer can replace rule-based chunk methods within the Retrieval-Augmented Generation (RAG) system, producing more semantically coherent chunks that enhance its efficacy. Comprehensive evaluations confirm CrossFormer's state-of-the-art performance on public text semantic segmentation datasets, alongside considerable gains on RAG benchmarks.
ZO-AdaMU Optimizer: Adapting Perturbation by the Momentum and Uncertainty in Zeroth-order Optimization
Dec 23, 2023Lowering the memory requirement in full-parameter training on large models has become a hot research area. MeZO fine-tunes the large language models (LLMs) by just forward passes in a zeroth-order SGD optimizer (ZO-SGD), demonstrating excellent performance with the same GPU memory usage as inference. However, the simulated perturbation stochastic approximation for gradient estimate in MeZO leads to severe oscillations and incurs a substantial time overhead. Moreover, without momentum regularization, MeZO shows severe over-fitting problems. Lastly, the perturbation-irrelevant momentum on ZO-SGD does not improve the convergence rate. This study proposes ZO-AdaMU to resolve the above problems by adapting the simulated perturbation with momentum in its stochastic approximation. Unlike existing adaptive momentum methods, we relocate momentum on simulated perturbation in stochastic gradient approximation. Our convergence analysis and experiments prove this is a better way to improve convergence stability and rate in ZO-SGD. Extensive experiments demonstrate that ZO-AdaMU yields better generalization for LLMs fine-tuning across various NLP tasks than MeZO and its momentum variants.
TDeLTA: A Light-weight and Robust Table Detection Method based on Learning Text Arrangement
Dec 18, 2023
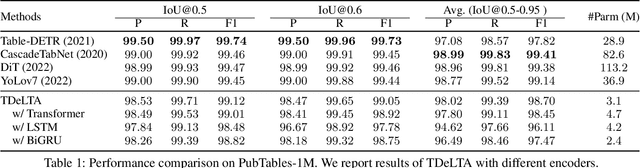

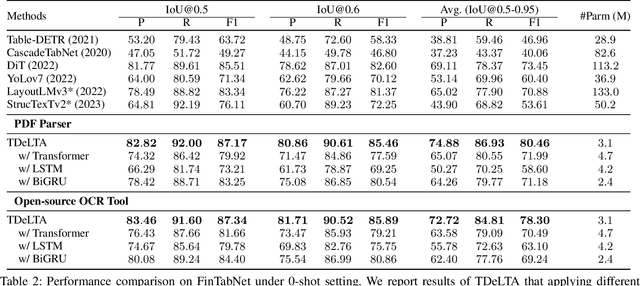
The diversity of tables makes table detection a great challenge, leading to existing models becoming more tedious and complex. Despite achieving high performance, they often overfit to the table style in training set, and suffer from significant performance degradation when encountering out-of-distribution tables in other domains. To tackle this problem, we start from the essence of the table, which is a set of text arranged in rows and columns. Based on this, we propose a novel, light-weighted and robust Table Detection method based on Learning Text Arrangement, namely TDeLTA. TDeLTA takes the text blocks as input, and then models the arrangement of them with a sequential encoder and an attention module. To locate the tables precisely, we design a text-classification task, classifying the text blocks into 4 categories according to their semantic roles in the tables. Experiments are conducted on both the text blocks parsed from PDF and extracted by open-source OCR tools, respectively. Compared to several state-of-the-art methods, TDeLTA achieves competitive results with only 3.1M model parameters on the large-scale public datasets. Moreover, when faced with the cross-domain data under the 0-shot setting, TDeLTA outperforms baselines by a large margin of nearly 7%, which shows the strong robustness and transferability of the proposed model.
Confounder Balancing in Adversarial Domain Adaptation for Pre-Trained Large Models Fine-Tuning
Oct 24, 2023
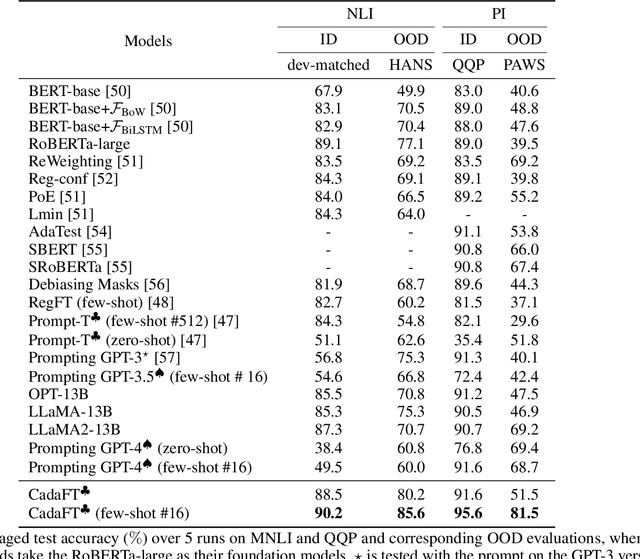

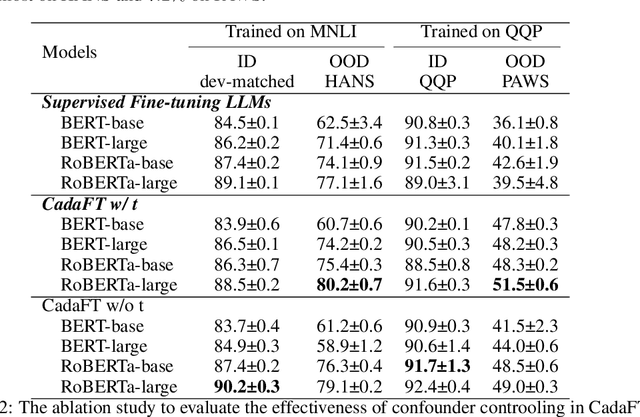
The excellent generalization, contextual learning, and emergence abilities in the pre-trained large models (PLMs) handle specific tasks without direct training data, making them the better foundation models in the adversarial domain adaptation (ADA) methods to transfer knowledge learned from the source domain to target domains. However, existing ADA methods fail to account for the confounder properly, which is the root cause of the source data distribution that differs from the target domains. This study proposes an adversarial domain adaptation with confounder balancing for PLMs fine-tuning (ADA-CBF). The ADA-CBF includes a PLM as the foundation model for a feature extractor, a domain classifier and a confounder classifier, and they are jointly trained with an adversarial loss. This loss is designed to improve the domain-invariant representation learning by diluting the discrimination in the domain classifier. At the same time, the adversarial loss also balances the confounder distribution among source and unmeasured domains in training. Compared to existing ADA methods, ADA-CBF can correctly identify confounders in domain-invariant features, thereby eliminating the confounder biases in the extracted features from PLMs. The confounder classifier in ADA-CBF is designed as a plug-and-play and can be applied in the confounder measurable, unmeasurable, or partially measurable environments. Empirical results on natural language processing and computer vision downstream tasks show that ADA-CBF outperforms the newest GPT-4, LLaMA2, ViT and ADA methods.
Decomposing Word Embedding with the Capsule Network
Apr 07, 2020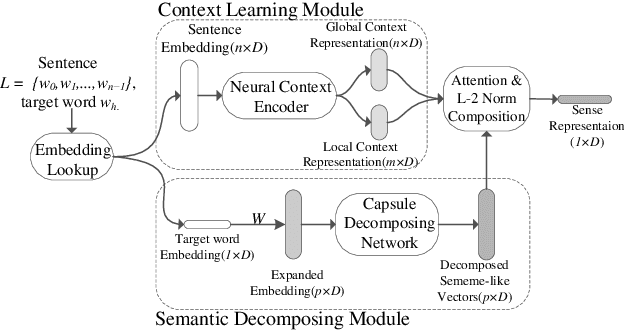
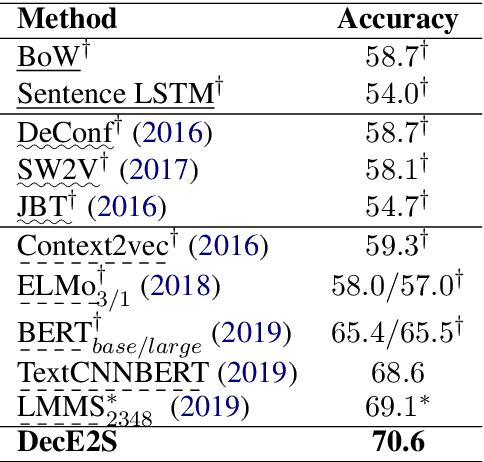
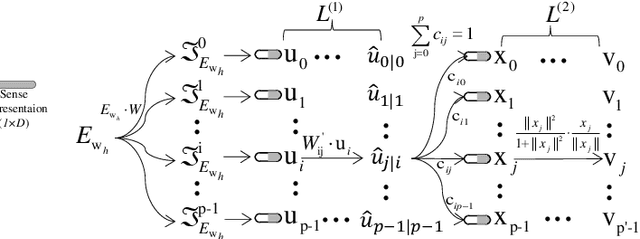
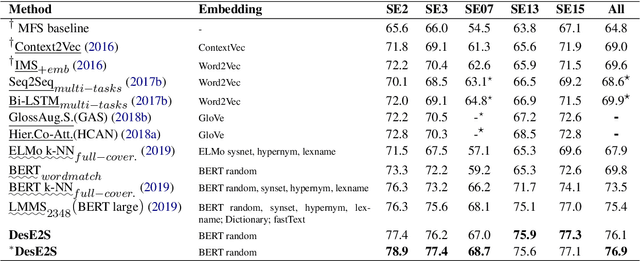
Multi-sense word embeddings have been promising solutions for word sense learning. Nevertheless, building large-scale training corpus and learning appropriate word sense are still open issues. In this paper, we propose a method for Decomposing the word Embedding into context-specific Sense representation, called DecE2S. First, the unsupervised polysemy embedding is fed into capsule network to produce its multiple sememe-like vectors. Second, with attention operations, DecE2S integrates the word context to represent the context-specific sense vector. To train DecE2S, we design a word matching training method for learning the context-specific sense representation. DecE2S was experimentally evaluated on two sense learning tasks, i.e., word in context and word sense disambiguation. Results on two public corpora Word-in-Context and English all-words Word Sense Disambiguation show that, the DesE2S model achieves the new state-of-the-art for the word in context and word sense disambiguation tasks.
CNN based music emotion classification
Apr 19, 2017



Music emotion recognition (MER) is usually regarded as a multi-label tagging task, and each segment of music can inspire specific emotion tags. Most researchers extract acoustic features from music and explore the relations between these features and their corresponding emotion tags. Considering the inconsistency of emotions inspired by the same music segment for human beings, seeking for the key acoustic features that really affect on emotions is really a challenging task. In this paper, we propose a novel MER method by using deep convolutional neural network (CNN) on the music spectrograms that contains both the original time and frequency domain information. By the proposed method, no additional effort on extracting specific features required, which is left to the training procedure of the CNN model. Experiments are conducted on the standard CAL500 and CAL500exp dataset. Results show that, for both datasets, the proposed method outperforms state-of-the-art methods.
Stroke Sequence-Dependent Deep Convolutional Neural Network for Online Handwritten Chinese Character Recognition
Oct 13, 2016
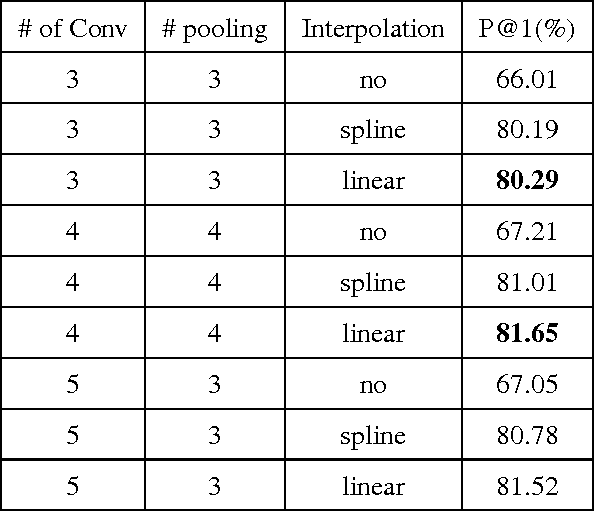

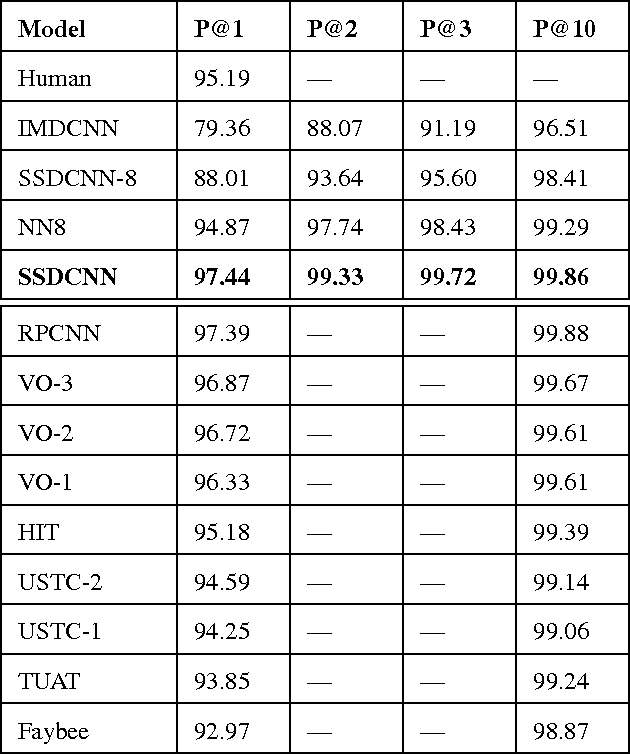
In this paper, we propose a novel model, named Stroke Sequence-dependent Deep Convolutional Neural Network (SSDCNN), using the stroke sequence information and eight-directional features for Online Handwritten Chinese Character Recognition (OLHCCR). On one hand, SSDCNN can learn the representation of Online Handwritten Chinese Character (OLHCC) by incorporating the natural sequence information of the strokes. On the other hand, SSDCNN can incorporate eight-directional features in a natural way. In order to train SSDCNN, we divide the process of training into two stages: 1) The training data is used to pre-train the whole architecture until the performance tends to converge. 2) Fully-connected neural network which is used to combine the stroke sequence-dependent representation with eight-directional features and softmax layer are further trained. Experiments were conducted on the OLHCCR competition tasks of ICDAR 2013. Results show that, SSDCNN can reduce the recognition error by 50\% (5.13\% vs 2.56\%) compared to the model which only use eight-directional features. The proposed SSDCNN achieves 97.44\% accuracy which reduces the recognition error by about 1.9\% compared with the best submitted system on ICDAR2013 competition. These results indicate that SSDCNN can exploit the stroke sequence information to learn high-quality representation of OLHCC. It also shows that the learnt representation and the classical eight-directional features complement each other within the SSDCNN architecture.