 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDeLTA: A Light-weight and Robust Table Detection Method based on Learning Text Arrangement
Paper and Code

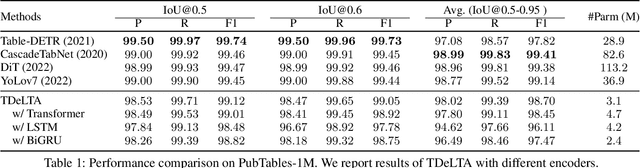

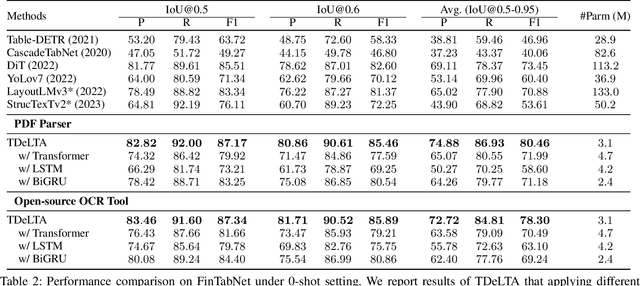
The diversity of tables makes table detection a great challenge, leading to existing models becoming more tedious and complex. Despite achieving high performance, they often overfit to the table style in training set, and suffer from significant performance degradation when encountering out-of-distribution tables in other domains. To tackle this problem, we start from the essence of the table, which is a set of text arranged in rows and columns. Based on this, we propose a novel, light-weighted and robust Table Detection method based on Learning Text Arrangement, namely TDeLTA. TDeLTA takes the text blocks as input, and then models the arrangement of them with a sequential encoder and an attention module. To locate the tables precisely, we design a text-classification task, classifying the text blocks into 4 categories according to their semantic roles in the tables. Experiments are conducted on both the text blocks parsed from PDF and extracted by open-source OCR tools, respectively. Compared to several state-of-the-art methods, TDeLTA achieves competitive results with only 3.1M model parameters on the large-scale public datasets. Moreover, when faced with the cross-domain data under the 0-shot setting, TDeLTA outperforms baselines by a large margin of nearly 7%, which shows the strong robustness and transferability of the proposed model.