 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning on Augmented Gene Expression Profiles for Enhanced Lung Cancer Detection
Aug 19, 2024Gene expression profiles obtained through DNA microarray have proven successful in providing critical information for cancer detection classifiers. However, the limited number of samples in these datasets poses a challenge to employ complex methodologies such as deep neural networks for sophisticated analysis. To address this "small data" dilemma, Meta-Learning has been introduced as a solution to enhance the optimization of machine learning models by utilizing similar datasets, thereby facilitating a quicker adaptation to target datasets without the requirement of sufficient samples. In this study, we present a meta-learning-based approach for predicting lung cancer from gene expression profiles. We apply this framework to well-established deep learning methodologies and employ four distinct datasets for the meta-learning tasks, where one as the target dataset and the rest as source datasets. Our approach is evaluated against both traditional and deep learning methodologies, and the results show the superior performance of meta-learning on augmented source data compared to the baselines trained on single datasets. Moreover, we conduct the comparative analysis between meta-learning and transfer learning methodologies to highlight the efficiency of the proposed approach in addressing the challenges associated with limited sample sizes. Finally, we incorporate the explainability study to illustrate the distinctiveness of decisions made by meta-learning.
Aphid Cluster Recognition and Detection in the Wild Using Deep Learning Models
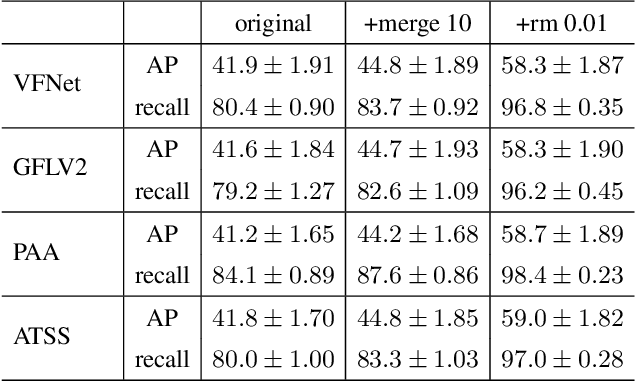
Aug 10, 2023Aphid infestation poses a significant threat to crop production, rural communities, and global food security. While chemical pest control is crucial for maximizing yields, applying chemicals across entire fields is both environmentally unsustainable and costly. Hence, precise localization and management of aphids are essential for targeted pesticide application. The paper primarily focuses on using deep learning models for detecting aphid clusters. We propose a novel approach for estimating infection levels by detecting aphid clusters. To facilitate this research, we have captured a large-scale dataset from sorghum fields, manually selected 5,447 images containing aphids, and annotated each individual aphid cluster within these images. To facilitate the use of machine learning models, we further process the images by cropping them into patches, resulting in a labeled dataset comprising 151,380 image patches. Then, we implemented and compared the performance of four state-of-the-art object detection models (VFNet, GFLV2, PAA, and ATSS) on the aphid dataset. Extensive experimental results show that all models yield stable similar performance in terms of average precision and recall. We then propose to merge close neighboring clusters and remove tiny clusters caused by cropping, and the performance is further boosted by around 17%. The study demonstrates the feasibility of automatically detecting and managing insects using machine learning models. The labeled dataset will be made openly available to the research community.
A New Dataset and Comparative Study for Aphid Cluster Detection
Jul 12, 2023

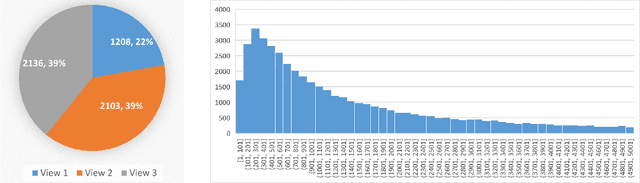
Aphids are one of the main threats to crops, rural families, and global food security. Chemical pest control is a necessary component of crop production for maximizing yields, however, it is unnecessary to apply the chemical approaches to the entire fields in consideration of the environmental pollution and the cost. Thus, accurately localizing the aphid and estimating the infestation level is crucial to the precise local application of pesticides. Aphid detection is very challenging as each individual aphid is really small and all aphids are crowded together as clusters. In this paper, we propose to estimate the infection level by detecting aphid clusters. We have taken millions of images in the sorghum fields, manually selected 5,447 images that contain aphids, and annotated each aphid cluster in the image. To use these images for machine learning models, we crop the images into patches and created a labeled dataset with over 151,000 image patches. Then, we implement and compare the performance of four state-of-the-art object detection models.
Explicitly Increasing Input Information Density for Vision Transformers on Small Datasets
Oct 25, 2022



Vision Transformers have attracted a lot of attention recently since the successful implementation of Vision Transformer (ViT) on vision tasks. With vision Transformers, specifically the multi-head self-attention modules, networks can capture long-term dependencies inherently. However, these attention modules normally need to be trained on large datasets, and vision Transformers show inferior performance on small datasets when training from scratch compared with widely dominant backbones like ResNets. Note that the Transformer model was first proposed for natural language processing, which carries denser information than natural images. To boost the performance of vision Transformers on small datasets, this paper proposes to explicitly increase the input information density in the frequency domain. Specifically, we introduce selecting channels by calculating the channel-wise heatmaps in the frequency domain using Discrete Cosine Transform (DCT), reducing the size of input while keeping most information and hence increasing the information density. As a result, 25% fewer channels are kept while better performance is achieved compared with previous work. Extensive experiments demonstrate the effectiveness of the proposed approach on five small-scale datasets, including CIFAR-10/100, SVHN, Flowers-102, and Tiny ImageNet. The accuracy has been boosted up to 17.05% with Swin and Focal Transformers. Codes are available at https://github.com/xiangyu8/DenseVT.
Robust Structured Declarative Classifiers for 3D Point Clouds: Defending Adversarial Attacks with Implicit Gradients
Mar 29, 2022



Deep neural networks for 3D point cloud classification, such as PointNet, have been demonstrated to be vulnerable to adversarial attacks. Current adversarial defenders often learn to denoise the (attacked) point clouds by reconstruction, and then feed them to the classifiers as input. In contrast to the literature, we propose a family of robust structured declarative classifiers for point cloud classification, where the internal constrained optimization mechanism can effectively defend adversarial attacks through implicit gradients. Such classifiers can be formulated using a bilevel optimization framework. We further propose an effective and efficient instantiation of our approach, namely, Lattice Point Classifier (LPC), based on structured sparse coding in the permutohedral lattice and 2D convolutional neural networks (CNNs) that is end-to-end trainable. We demonstrate state-of-the-art robust point cloud classification performance on ModelNet40 and ScanNet under seven different attackers. For instance, we achieve 89.51% and 83.16% test accuracy on each dataset under the recent JGBA attacker that outperforms DUP-Net and IF-Defense with PointNet by ~70%. Demo code is available at https://zhang-vislab.github.io.
Dilated Continuous Random Field for Semantic Segmentation
Feb 01, 2022

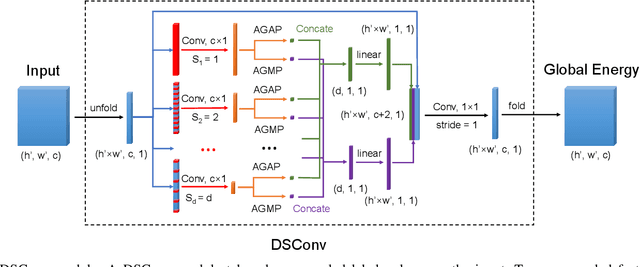
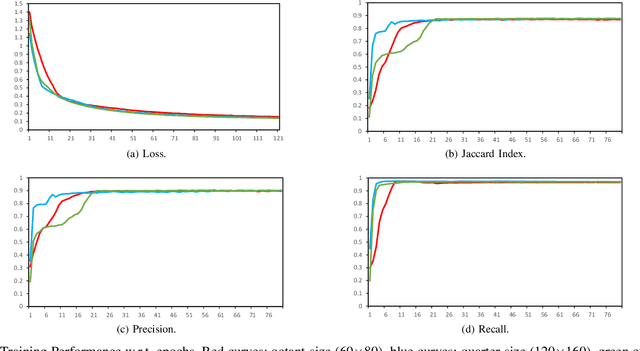
Mean field approximation methodology has laid the foundation of modern Continuous Random Field (CRF) based solutions for the refinement of semantic segmentation. In this paper, we propose to relax the hard constraint of mean field approximation - minimizing the energy term of each node from probabilistic graphical model, by a global optimization with the proposed dilated sparse convolution module (DSConv). In addition, adaptive global average-pooling and adaptive global max-pooling are implemented as replacements of fully connected layers. In order to integrate DSConv, we design an end-to-end, time-efficient DilatedCRF pipeline. The unary energy term is derived either from pre-softmax and post-softmax features, or the predicted affordance map using a conventional classifier, making it easier to implement DilatedCRF for varieties of classifiers. We also present superior experimental results of proposed approach on the suction dataset comparing to other CRF-based approaches.
A Fine-Grained Visual Attention Approach for Fingerspelling Recognition in the Wild
May 17, 2021



Fingerspelling in sign language has been the means of communicating technical terms and proper nouns when they do not have dedicated sign language gestures. Automatic recognition of fingerspelling can help resolve communication barriers when interacting with deaf people. The main challenges prevalent in fingerspelling recognition are the ambiguity in the gestures and strong articulation of the hands. The automatic recognition model should address high inter-class visual similarity and high intra-class variation in the gestures. Most of the existing research in fingerspelling recognition has focused on the dataset collected in a controlled environment. The recent collection of a large-scale annotated fingerspelling dataset in the wild, from social media and online platforms, captures the challenges in a real-world scenario. In this work, we propose a fine-grained visual attention mechanism using the Transformer model for the sequence-to-sequence prediction task in the wild dataset. The fine-grained attention is achieved by utilizing the change in motion of the video frames (optical flow) in sequential context-based attention along with a Transformer encoder model. The unsegmented continuous video dataset is jointly trained by balancing the Connectionist Temporal Classification (CTC) loss and the maximum-entropy loss. The proposed approach can capture better fine-grained attention in a single iteration. Experiment evaluations show that it outperforms the state-of-the-art approaches.
Colonoscopy Polyp Detection and Classification: Dataset Creation and Comparative Evaluations
Apr 22, 2021



Colorectal cancer (CRC) is one of the most common types of cancer with a high mortality rate. Colonoscopy is the preferred procedure for CRC screening and has proven to be effective in reducing CRC mortality. Thus, a reliable computer-aided polyp detection and classification system can significantly increase the effectiveness of colonoscopy. In this paper, we create an endoscopic dataset collected from various sources and annotate the ground truth of polyp location and classification results with the help of experienced gastroenterologists. The dataset can serve as a benchmark platform to train and evaluate the machine learning models for polyp classification. We have also compared the performance of eight state-of-the-art deep learning-based object detection models. The results demonstrate that deep CNN models are promising in CRC screening. This work can serve as a baseline for future research in polyp detection and classification.
Classification of Noncoding RNA Elements Using Deep Convolutional Neural Networks
Aug 24, 2020


The paper proposes to employ deep convolutional neural networks (CNNs) to classify noncoding RNA (ncRNA) sequences. To this end, we first propose an efficient approach to convert the RNA sequences into images characterizing their base-pairing probability. As a result, classifying RNA sequences is converted to an image classification problem that can be efficiently solved by available CNN-based classification models. The paper also considers the folding potential of the ncRNAs in addition to their primary sequence. Based on the proposed approach, a benchmark image classification dataset is generated from the RFAM database of ncRNA sequences. In addition, three classical CNN models have been implemented and compared to demonstrate the superior performance and efficiency of the proposed approach. Extensive experimental results show the great potential of using deep learning approaches for RNA classification.