 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDilated Continuous Random Field for Semantic Segmentation
Feb 01, 2022

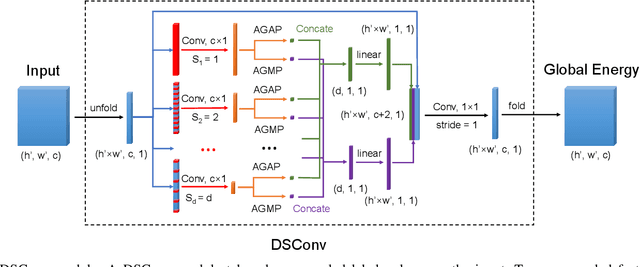
Mean field approximation methodology has laid the foundation of modern Continuous Random Field (CRF) based solutions for the refinement of semantic segmentation. In this paper, we propose to relax the hard constraint of mean field approximation - minimizing the energy term of each node from probabilistic graphical model, by a global optimization with the proposed dilated sparse convolution module (DSConv). In addition, adaptive global average-pooling and adaptive global max-pooling are implemented as replacements of fully connected layers. In order to integrate DSConv, we design an end-to-end, time-efficient DilatedCRF pipeline. The unary energy term is derived either from pre-softmax and post-softmax features, or the predicted affordance map using a conventional classifier, making it easier to implement DilatedCRF for varieties of classifiers. We also present superior experimental results of proposed approach on the suction dataset comparing to other CRF-based approaches.
Towards More Effective PRM-based Crowd Counting via A Multi-resolution Fusion and Attention Network
Dec 17, 2021


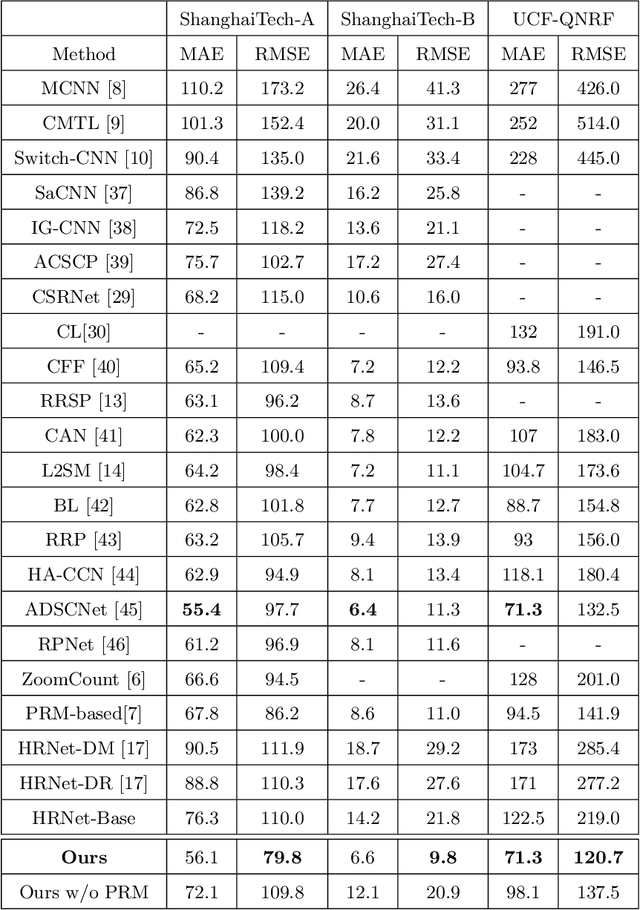
The paper focuses on improving the recent plug-and-play patch rescaling module (PRM) based approaches for crowd counting. In order to make full use of the PRM potential and obtain more reliable and accurate results for challenging images with crowd-variation, large perspective, extreme occlusions, and cluttered background regions, we propose a new PRM based multi-resolution and multi-task crowd counting network by exploiting the PRM module with more effectiveness and potency. The proposed model consists of three deep-layered branches with each branch generating feature maps of different resolutions. These branches perform a feature-level fusion across each other to build the vital collective knowledge to be used for the final crowd estimate. Additionally, early-stage feature maps undergo visual attention to strengthen the later-stage channels understanding of the foreground regions. The integration of these deep branches with the PRM module and the early-attended blocks proves to be more effective than the original PRM based schemes through extensive numerical and visual evaluations on four benchmark datasets. The proposed approach yields a significant improvement by a margin of 12.6% in terms of the RMSE evaluation criterion. It also outperforms state-of-the-art methods in cross-dataset evaluations.
Audio-Visual Transformer Based Crowd Counting
Sep 04, 2021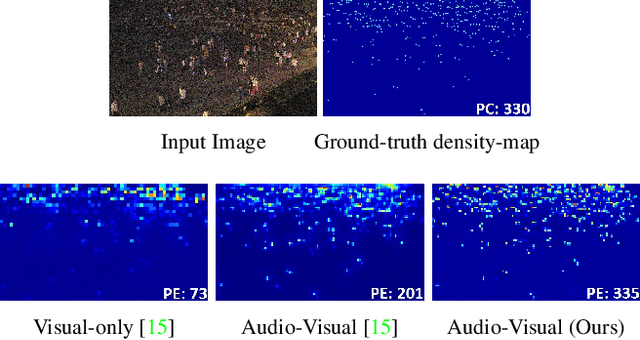
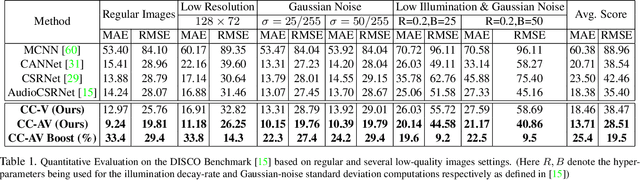
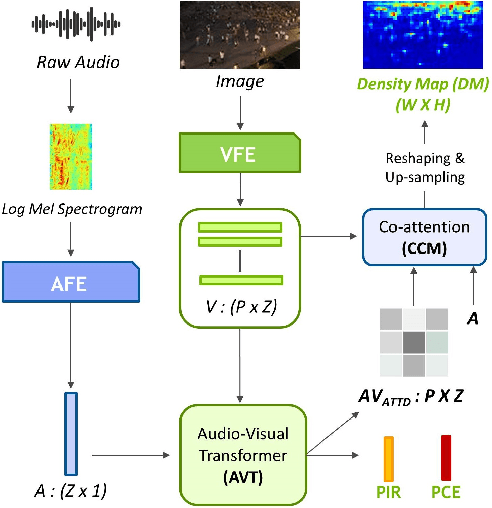

Crowd estimation is a very challenging problem. The most recent study tries to exploit auditory information to aid the visual models, however, the performance is limited due to the lack of an effective approach for feature extraction and integration. The paper proposes a new audiovisual multi-task network to address the critical challenges in crowd counting by effectively utilizing both visual and audio inputs for better modalities association and productive feature extraction. The proposed network introduces the notion of auxiliary and explicit image patch-importance ranking (PIR) and patch-wise crowd estimate (PCE) information to produce a third (run-time) modality. These modalities (audio, visual, run-time) undergo a transformer-inspired cross-modality co-attention mechanism to finally output the crowd estimate. To acquire rich visual features, we propose a multi-branch structure with transformer-style fusion in-between. Extensive experimental evaluations show that the proposed scheme outperforms the state-of-the-art networks under all evaluation settings with up to 33.8% improvement. We also analyze and compare the vision-only variant of our network and empirically demonstrate its superiority over previous approaches.
Parallel Scale-wise Attention Network for Effective Scene Text Recognition
Apr 25, 2021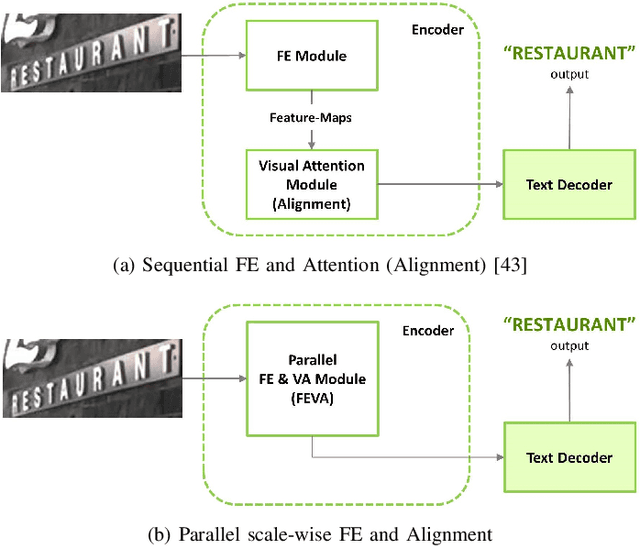
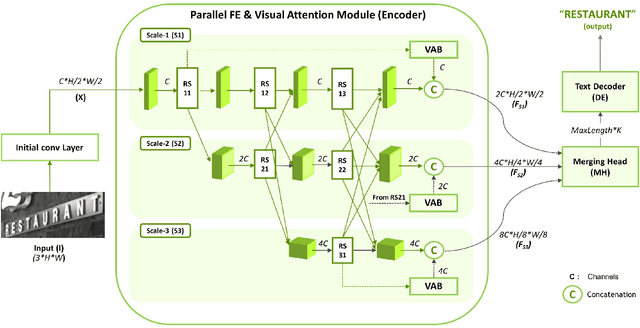
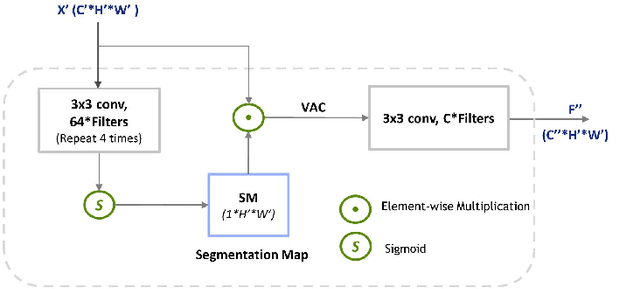

The paper proposes a new text recognition network for scene-text images. Many state-of-the-art methods employ the attention mechanism either in the text encoder or decoder for the text alignment. Although the encoder-based attention yields promising results, these schemes inherit noticeable limitations. They perform the feature extraction (FE) and visual attention (VA) sequentially, which bounds the attention mechanism to rely only on the FE final single-scale output. Moreover, the utilization of the attention process is limited by only applying it directly to the single scale feature-maps. To address these issues, we propose a new multi-scale and encoder-based attention network for text recognition that performs the multi-scale FE and VA in parallel. The multi-scale channels also undergo regular fusion with each other to develop the coordinated knowledge together. Quantitative evaluation and robustness analysis on the standard benchmarks demonstrate that the proposed network outperforms the state-of-the-art in most cases.
Stereo Frustums: A Siamese Pipeline for 3D Object Detection
Nov 08, 2020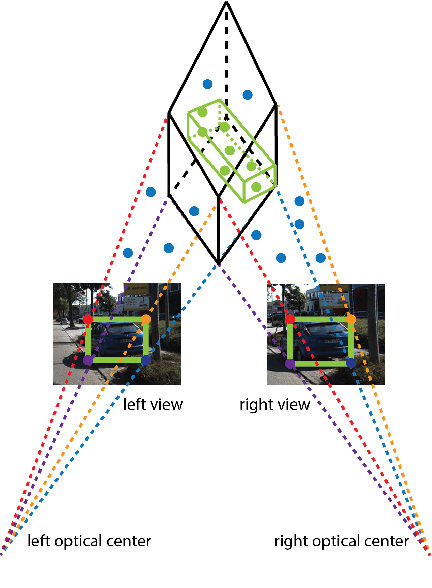
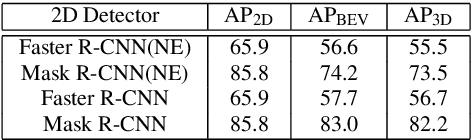
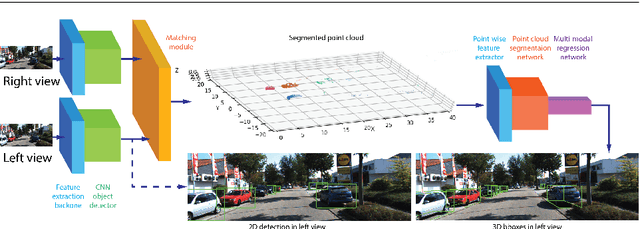
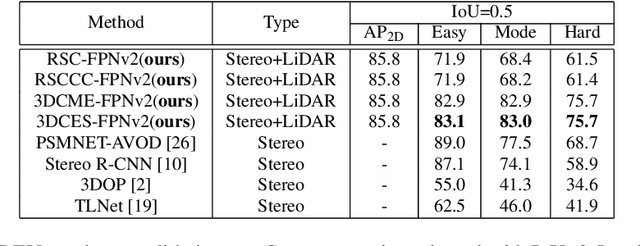
The paper proposes a light-weighted stereo frustums matching module for 3D objection detection. The proposed framework takes advantage of a high-performance 2D detector and a point cloud segmentation network to regress 3D bounding boxes for autonomous driving vehicles. Instead of performing traditional stereo matching to compute disparities, the module directly takes the 2D proposals from both the left and the right views as input. Based on the epipolar constraints recovered from the well-calibrated stereo cameras, we propose four matching algorithms to search for the best match for each proposal between the stereo image pairs. Each matching pair proposes a segmentation of the scene which is then fed into a 3D bounding box regression network. Results of extensive experiments on KITTI dataset demonstrate that the proposed Siamese pipeline outperforms the state-of-the-art stereo-based 3D bounding box regression methods.
Multi-Resolution Fusion and Multi-scale Input Priors Based Crowd Counting
Oct 04, 2020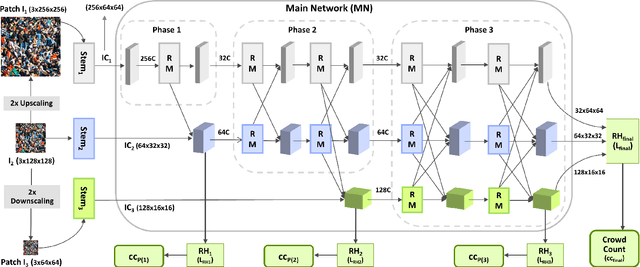



Crowd counting in still images is a challenging problem in practice due to huge crowd-density variations, large perspective changes, severe occlusion, and variable lighting conditions. The state-of-the-art patch rescaling module (PRM) based approaches prove to be very effective in improving the crowd counting performance. However, the PRM module requires an additional and compromising crowd-density classification process. To address these issues and challenges, the paper proposes a new multi-resolution fusion based end-to-end crowd counting network. It employs three deep-layers based columns/branches, each catering the respective crowd-density scale. These columns regularly fuse (share) the information with each other. The network is divided into three phases with each phase containing one or more columns. Three input priors are introduced to serve as an efficient and effective alternative to the PRM module, without requiring any additional classification operations. Along with the final crowd count regression head, the network also contains three auxiliary crowd estimation regression heads, which are strategically placed at each phase end to boost the overall performance. Comprehensive experiments on three benchmark datasets demonstrate that the proposed approach outperforms all the state-of-the-art models under the RMSE evaluation metric. The proposed approach also has better generalization capability with the best results during the cross-dataset experiments.
Classification of Noncoding RNA Elements Using Deep Convolutional Neural Networks
Aug 24, 2020

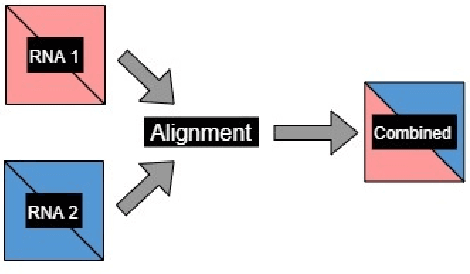

The paper proposes to employ deep convolutional neural networks (CNNs) to classify noncoding RNA (ncRNA) sequences. To this end, we first propose an efficient approach to convert the RNA sequences into images characterizing their base-pairing probability. As a result, classifying RNA sequences is converted to an image classification problem that can be efficiently solved by available CNN-based classification models. The paper also considers the folding potential of the ncRNAs in addition to their primary sequence. Based on the proposed approach, a benchmark image classification dataset is generated from the RFAM database of ncRNA sequences. In addition, three classical CNN models have been implemented and compared to demonstrate the superior performance and efficiency of the proposed approach. Extensive experimental results show the great potential of using deep learning approaches for RNA classification.
ZoomCount: A Zooming Mechanism for Crowd Counting in Static Images
Feb 27, 2020


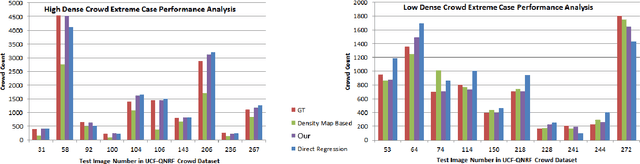
This paper proposes a novel approach for crowd counting in low to high density scenarios in static images. Current approaches cannot handle huge crowd diversity well and thus perform poorly in extreme cases, where the crowd density in different regions of an image is either too low or too high, leading to crowd underestimation or overestimation. The proposed solution is based on the observation that detecting and handling such extreme cases in a specialized way leads to better crowd estimation. Additionally, existing methods find it hard to differentiate between the actual crowd and the cluttered background regions, resulting in further count overestimation. To address these issues, we propose a simple yet effective modular approach, where an input image is first subdivided into fixed-size patches and then fed to a four-way classification module labeling each image patch as low, medium, high-dense or no-crowd. This module also provides a count for each label, which is then analyzed via a specifically devised novel decision module to decide whether the image belongs to any of the two extreme cases (very low or very high density) or a normal case. Images, specified as high- or low-density extreme or a normal case, pass through dedicated zooming or normal patch-making blocks respectively before routing to the regressor in the form of fixed-size patches for crowd estimate. Extensive experimental evaluations demonstrate that the proposed approach outperforms the state-of-the-art methods on four benchmarks under most of the evaluation criteria.
Plug-and-Play Rescaling Based Crowd Counting in Static Images
Jan 06, 2020
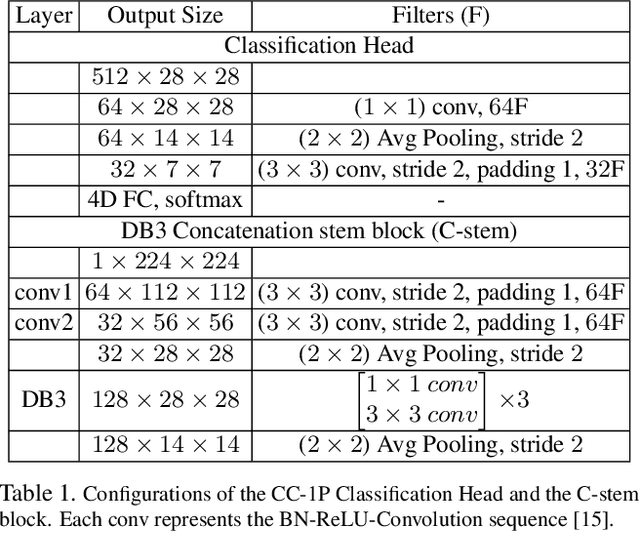

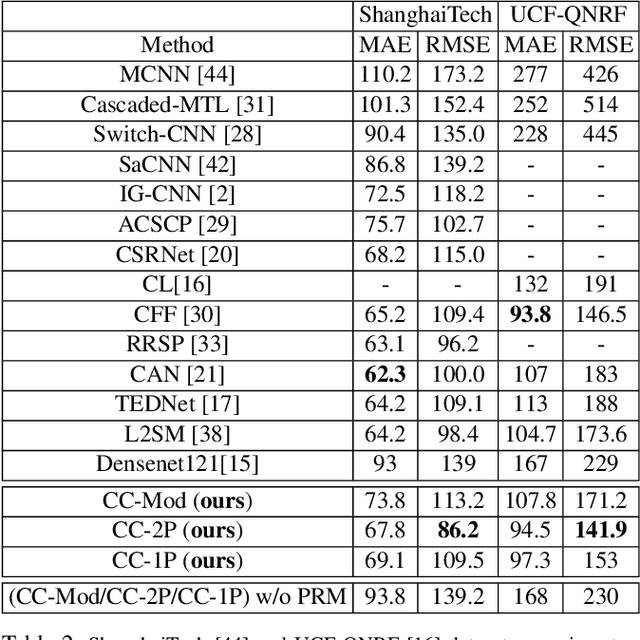
Crowd counting is a challenging problem especially in the presence of huge crowd diversity across images and complex cluttered crowd-like background regions, where most previous approaches do not generalize well and consequently produce either huge crowd underestimation or overestimation. To address these challenges, we propose a new image patch rescaling module (PRM) and three independent PRM employed crowd counting methods. The proposed frameworks use the PRM module to rescale the image regions (patches) that require special treatment, whereas the classification process helps in recognizing and discarding any cluttered crowd-like background regions which may result in overestimation. Experiments on three standard benchmarks and cross-dataset evaluation show that our approach outperforms the state-of-the-art models in the RMSE evaluation metric with an improvement up to 10.4%, and possesses superior generalization ability to new datasets.
Object Detection with Convolutional Neural Networks
Dec 04, 2019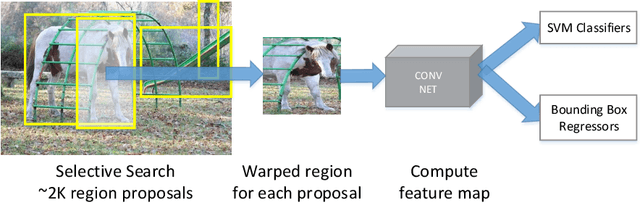

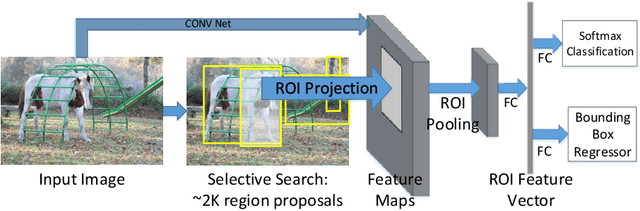
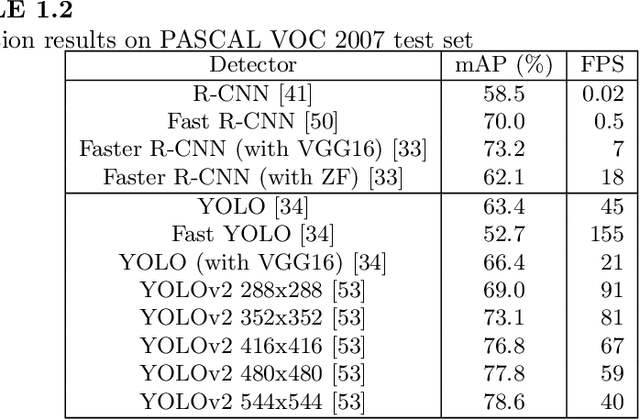
In this chapter, we present a brief overview of the recent development in object detection using convolutional neural networks (CNN). Several classical CNN-based detectors are presented. Some developments are based on the detector architectures, while others are focused on solving certain problems, like model degradation and small-scale object detection. The chapter also presents some performance comparison results of different models on several benchmark datasets. Through the discussion of these models, we hope to give readers a general idea about the developments of CNN-based object detection.