 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpleCall: A Lightweight Image Restoration Agent in Label-Free Environments with MLLM Perceptual Feedback
Dec 21, 2025Complex image restoration aims to recover high-quality images from inputs affected by multiple degradations such as blur, noise, rain, and compression artifacts. Recent restoration agents, powered by vision-language models and large language models, offer promising restoration capabilities but suffer from significant efficiency bottlenecks due to reflection, rollback, and iterative tool searching. Moreover, their performance heavily depends on degradation recognition models that require extensive annotations for training, limiting their applicability in label-free environments. To address these limitations, we propose a policy optimization-based restoration framework that learns an lightweight agent to determine tool-calling sequences. The agent operates in a sequential decision process, selecting the most appropriate restoration operation at each step to maximize final image quality. To enable training within label-free environments, we introduce a novel reward mechanism driven by multimodal large language models, which act as human-aligned evaluator and provide perceptual feedback for policy improvement. Once trained, our agent executes a deterministic restoration plans without redundant tool invocations, significantly accelerating inference while maintaining high restoration quality. Extensive experiments show that despite using no supervision, our method matches SOTA performance on full-reference metrics and surpasses existing approaches on no-reference metrics across diverse degradation scenarios.
Can Large Language Models Automatically Jailbreak GPT-4V?
Jul 23, 2024GPT-4V has attracted considerable attention due to its extraordinary capacity for integrating and processing multimodal information. At the same time, its ability of face recognition raises new safety concerns of privacy leakage. Despite researchers' efforts in safety alignment through RLHF or preprocessing filters, vulnerabilities might still be exploited. In our study, we introduce AutoJailbreak, an innovative automatic jailbreak technique inspired by prompt optimization. We leverage Large Language Models (LLMs) for red-teaming to refine the jailbreak prompt and employ weak-to-strong in-context learning prompts to boost efficiency. Furthermore, we present an effective search method that incorporates early stopping to minimize optimization time and token expenditure. Our experiments demonstrate that AutoJailbreak significantly surpasses conventional methods, achieving an Attack Success Rate (ASR) exceeding 95.3\%. This research sheds light on strengthening GPT-4V security, underscoring the potential for LLMs to be exploited in compromising GPT-4V integrity.
Jailbreaking GPT-4V via Self-Adversarial Attacks with System Prompts
Nov 15, 2023Existing work on jailbreak Multimodal Large Language Models (MLLMs) has focused primarily on adversarial examples in model inputs, with less attention to vulnerabilities in model APIs. To fill the research gap, we carry out the following work: 1) We discover a system prompt leakage vulnerability in GPT-4V. Through carefully designed dialogue, we successfully steal the internal system prompts of GPT-4V. This finding indicates potential exploitable security risks in MLLMs; 2)Based on the acquired system prompts, we propose a novel MLLM jailbreaking attack method termed SASP (Self-Adversarial Attack via System Prompt). By employing GPT-4 as a red teaming tool against itself, we aim to search for potential jailbreak prompts leveraging stolen system prompts. Furthermore, in pursuit of better performance, we also add human modification based on GPT-4's analysis, which further improves the attack success rate to 98.7\%; 3) We evaluated the effect of modifying system prompts to defend against jailbreaking attacks. Results show that appropriately designed system prompts can significantly reduce jailbreak success rates. Overall, our work provides new insights into enhancing MLLM security, demonstrating the important role of system prompts in jailbreaking, which could be leveraged to greatly facilitate jailbreak success rates while also holding the potential for defending against jailbreaks.
Branch-and-Pruning Optimization Towards Global Optimality in Deep Learning
Apr 05, 2021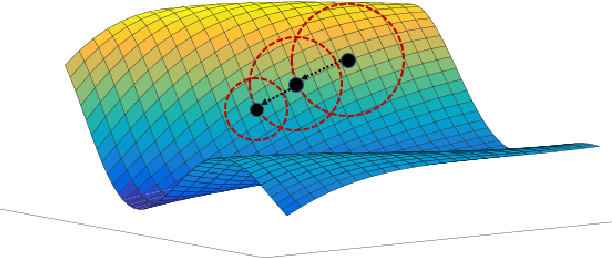
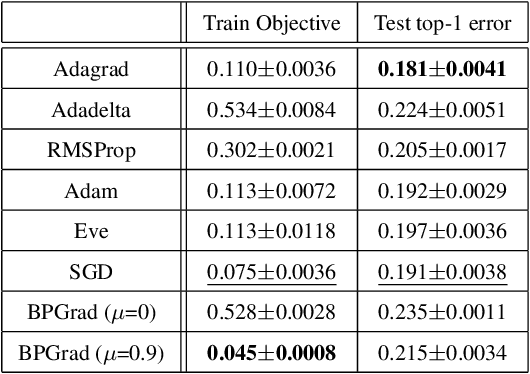
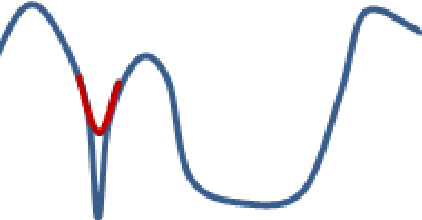
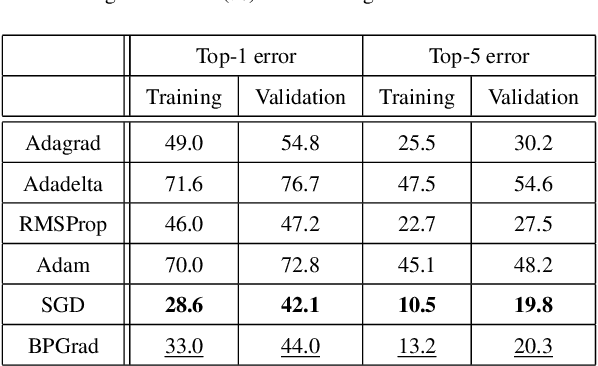
It has been attracting more and more attention to understand the global optimality in deep learning (DL) recently. However, conventional DL solvers, have not been developed intentionally to seek for such global optimality. In this paper, we propose a novel approximation algorithm, {\em BPGrad}, towards optimizing deep models globally via branch and pruning. The proposed BPGrad algorithm is based on the assumption of Lipschitz continuity in DL, and as a result, it can adaptively determine the step size for the current gradient given the history of previous updates, wherein theoretically no smaller steps can achieve the global optimality. We prove that, by repeating such a branch-and-pruning procedure, we can locate the global optimality within finite iterations. Empirically an efficient adaptive solver based on BPGrad for DL is proposed as well, and it outperforms conventional DL solvers such as Adagrad, Adadelta, RMSProp, and Adam in the tasks of object recognition, detection, and segmentation. The code is available at \url{https://github.com/RyanCV/BPGrad}.
Self-Orthogonality Module: A Network Architecture Plug-in for Learning Orthogonal Filters
Jan 17, 2020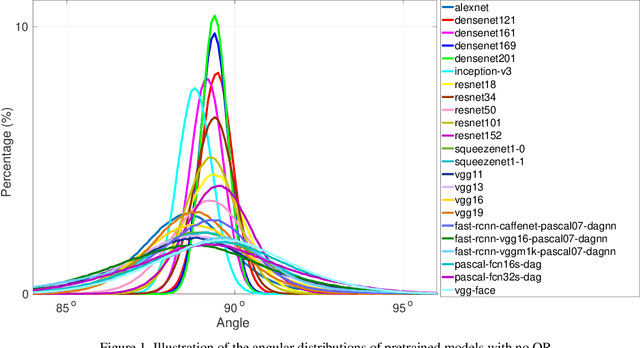
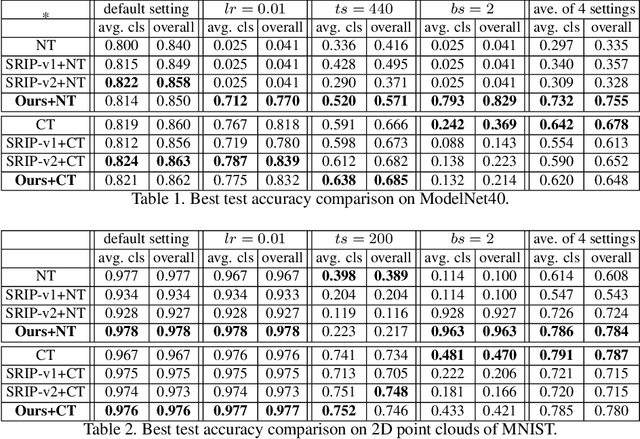
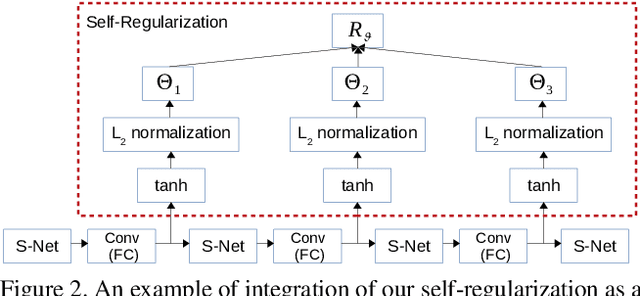
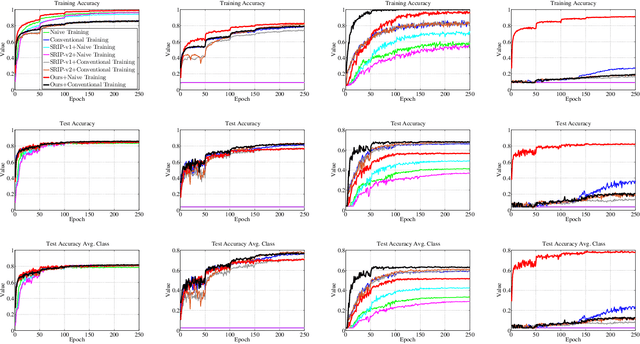
In this paper, we investigate the empirical impact of orthogonality regularization (OR) in deep learning, either solo or collaboratively. Recent works on OR showed some promising results on the accuracy. In our ablation study, however, we do not observe such significant improvement from existing OR techniques compared with the conventional training based on weight decay, dropout, and batch normalization. To identify the real gain from OR, inspired by the locality sensitive hashing (LSH) in angle estimation, we propose to introduce an implicit self-regularization into OR to push the mean and variance of filter angles in a network towards 90 and 0 simultaneously to achieve (near) orthogonality among the filters, without using any other explicit regularization. Our regularization can be implemented as an architectural plug-in and integrated with an arbitrary network. We reveal that OR helps stabilize the training process and leads to faster convergence and better generalization.
MDFN: Multi-Scale Deep Feature Learning Network for Object Detection
Dec 10, 2019
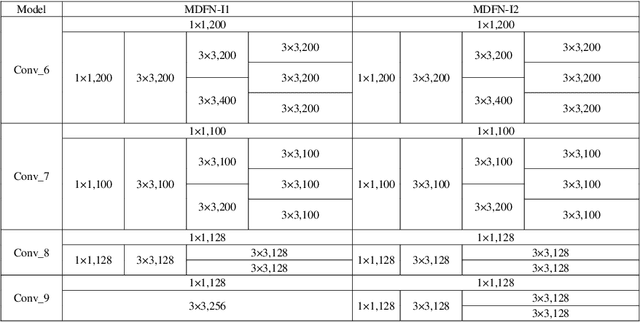
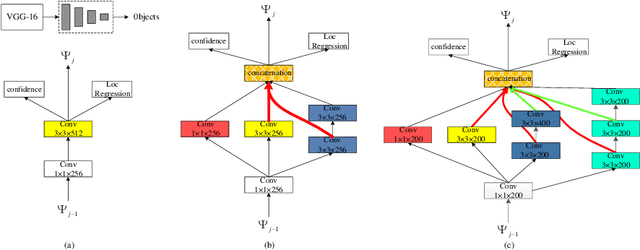
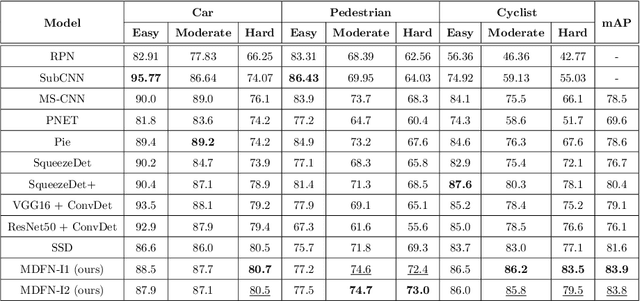
This paper proposes an innovative object detector by leveraging deep features learned in high-level layers. Compared with features produced in earlier layers, the deep features are better at expressing semantic and contextual information. The proposed deep feature learning scheme shifts the focus from concrete features with details to abstract ones with semantic information. It considers not only individual objects and local contexts but also their relationships by building a multi-scale deep feature learning network (MDFN). MDFN efficiently detects the objects by introducing information square and cubic inception modules into the high-level layers, which employs parameter-sharing to enhance the computational efficiency. MDFN provides a multi-scale object detector by integrating multi-box, multi-scale and multi-level technologies. Although MDFN employs a simple framework with a relatively small base network (VGG-16), it achieves better or competitive detection results than those with a macro hierarchical structure that is either very deep or very wide for stronger ability of feature extraction. The proposed technique is evaluated extensively on KITTI, PASCAL VOC, and COCO datasets, which achieves the best results on KITTI and leading performance on PASCAL VOC and COCO. This study reveals that deep features provide prominent semantic information and a variety of contextual contents, which contribute to its superior performance in detecting small or occluded objects. In addition, the MDFN model is computationally efficient, making a good trade-off between the accuracy and speed.
Object Detection with Convolutional Neural Networks
Dec 04, 2019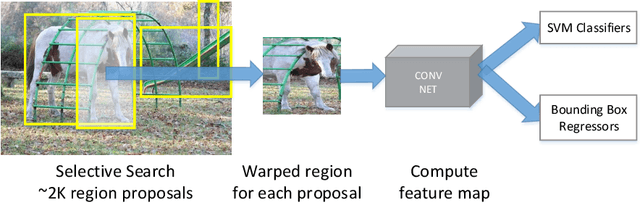

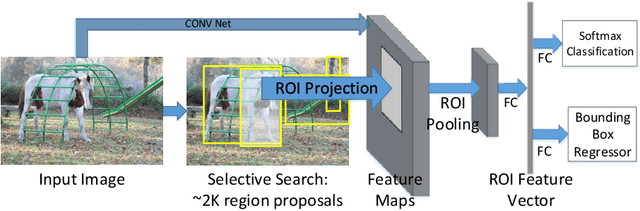
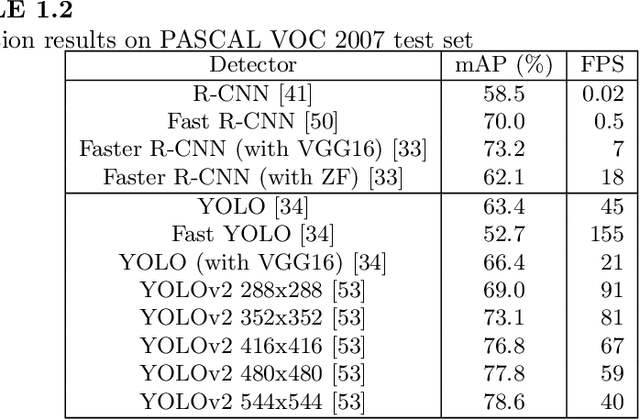
In this chapter, we present a brief overview of the recent development in object detection using convolutional neural networks (CNN). Several classical CNN-based detectors are presented. Some developments are based on the detector architectures, while others are focused on solving certain problems, like model degradation and small-scale object detection. The chapter also presents some performance comparison results of different models on several benchmark datasets. Through the discussion of these models, we hope to give readers a general idea about the developments of CNN-based object detection.
Adaptively Denoising Proposal Collection for Weakly Supervised Object Localization
Oct 19, 2019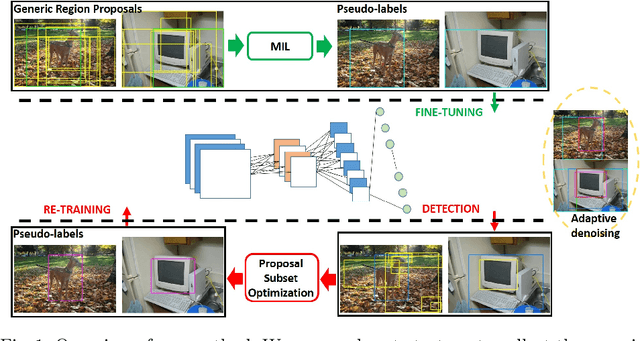
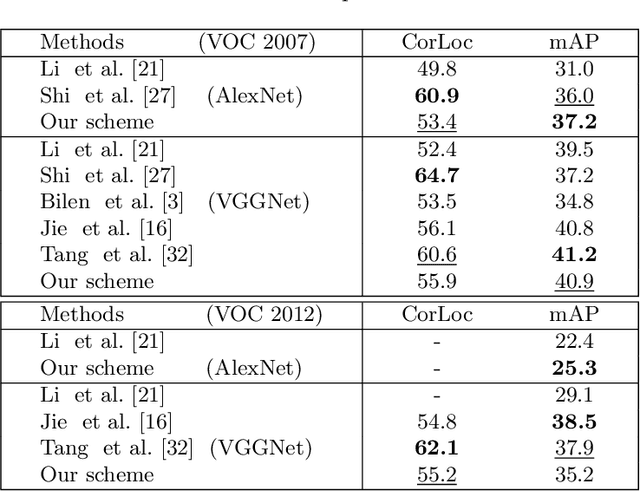


In this paper, we address the problem of weakly supervised object localization (WSL), which trains a detection network on the dataset with only image-level annotations. The proposed approach is built on the observation that the proposal set from the training dataset is a collection of background, object parts, and objects. Several strategies are taken to adaptively eliminate the noisy proposals and generate pseudo object-level annotations for the weakly labeled dataset. A multiple instance learning (MIL) algorithm enhanced by mask-out strategy is adopted to collect the class-specific object proposals, which are then utilized to adapt a pre-trained classification network to a detection network. In addition, the detection results from the detection network are re-weighted by jointly considering the detection scores and the overlap ratio of proposals in a proposal subset optimization framework. The optimal proposals work as object-level labels that enable a pseudo-strongly supervised dataset for training the detection network. Consequently, we establish a fully adaptive detection network. Extensive evaluations on the PASCAL VOC 2007 and 2012 datasets demonstrate a significant improvement compared with the state-of-the-art methods.
Unsupervised Deep Feature Transfer for Low Resolution Image Classification
Aug 27, 2019

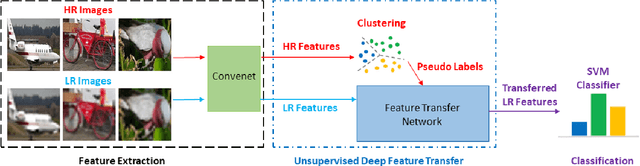
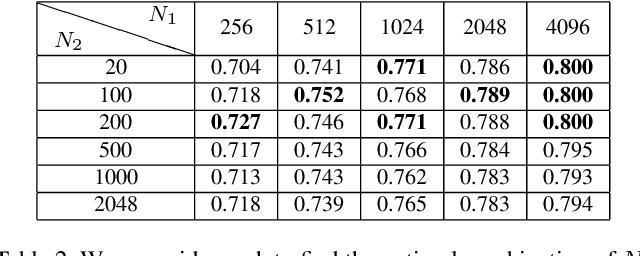
In this paper, we propose a simple while effective unsupervised deep feature transfer algorithm for low resolution image classification. No fine-tuning on convenet filters is required in our method. We use pre-trained convenet to extract features for both high- and low-resolution images, and then feed them into a two-layer feature transfer network for knowledge transfer. A SVM classifier is learned directly using these transferred low resolution features. Our network can be embedded into the state-of-the-art deep neural networks as a plug-in feature enhancement module. It preserves data structures in feature space for high resolution images, and transfers the distinguishing features from a well-structured source domain (high resolution features space) to a not well-organized target domain (low resolution features space). Extensive experiments on VOC2007 test set show that the proposed method achieves significant improvements over the baseline of using feature extraction.
MDCN: Multi-Scale, Deep Inception Convolutional Neural Networks for Efficient Object Detection
Sep 06, 2018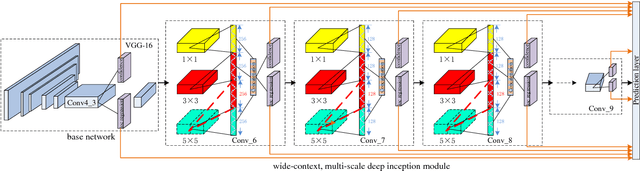

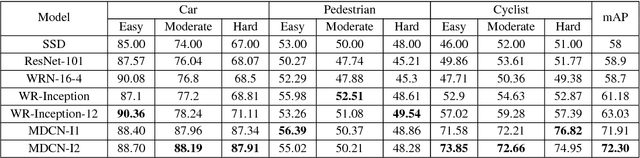
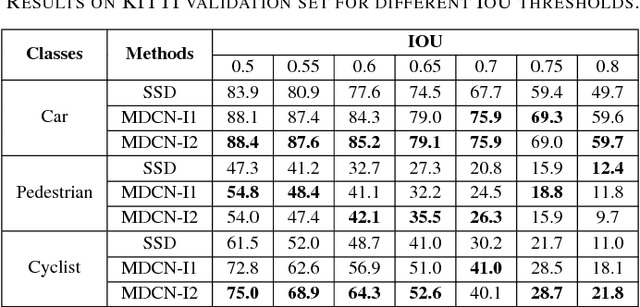
Object detection in challenging situations such as scale variation, occlusion, and truncation depends not only on feature details but also on contextual information. Most previous networks emphasize too much on detailed feature extraction through deeper and wider networks, which may enhance the accuracy of object detection to certain extent. However, the feature details are easily being changed or washed out after passing through complicated filtering structures. To better handle these challenges, the paper proposes a novel framework, multi-scale, deep inception convolutional neural network (MDCN), which focuses on wider and broader object regions by activating feature maps produced in the deep part of the network. Instead of incepting inner layers in the shallow part of the network, multi-scale inceptions are introduced in the deep layers. The proposed framework integrates the contextual information into the learning process through a single-shot network structure. It is computational efficient and avoids the hard training problem of previous macro feature extraction network designed for shallow layers. Extensive experiments demonstrate the effectiveness and superior performance of MDCN over the state-of-the-art models.