 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Feature Augmentation for Occluded Image Classification
Nov 02, 2020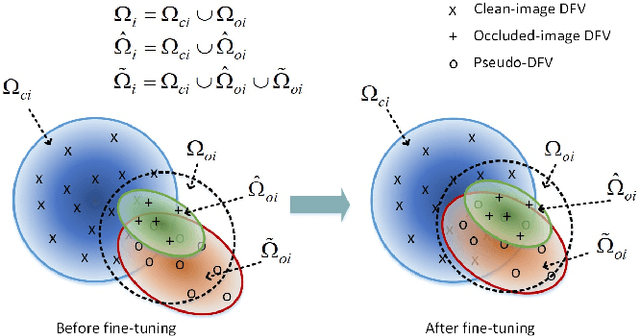

Due to the difficulty in acquiring massive task-specific occluded images, the classification of occluded images with deep convolutional neural networks (CNNs) remains highly challenging. To alleviate the dependency on large-scale occluded image datasets, we propose a novel approach to improve the classification accuracy of occluded images by fine-tuning the pre-trained models with a set of augmented deep feature vectors (DFVs). The set of augmented DFVs is composed of original DFVs and pseudo-DFVs. The pseudo-DFVs are generated by randomly adding difference vectors (DVs), extracted from a small set of clean and occluded image pairs, to the real DFVs. In the fine-tuning, the back-propagation is conducted on the DFV data flow to update the network parameters. The experiments on various datasets and network structures show that the deep feature augmentation significantly improves the classification accuracy of occluded images without a noticeable influence on the performance of clean images. Specifically, on the ILSVRC2012 dataset with synthetic occluded images, the proposed approach achieves 11.21% and 9.14% average increases in classification accuracy for the ResNet50 networks fine-tuned on the occlusion-exclusive and occlusion-inclusive training sets, respectively.
Boosting Occluded Image Classification via Subspace Decomposition Based Estimation of Deep Features
Jan 13, 2020



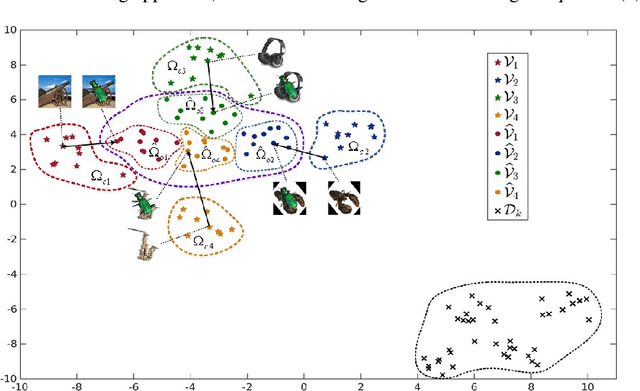
Classification of partially occluded images is a highly challenging computer vision problem even for the cutting edge deep learning technologies. To achieve a robust image classification for occluded images, this paper proposes a novel scheme using subspace decomposition based estimation (SDBE). The proposed SDBE-based classification scheme first employs a base convolutional neural network to extract the deep feature vector (DFV) and then utilizes the SDBE to compute the DFV of the original occlusion-free image for classification. The SDBE is performed by projecting the DFV of the occluded image onto the linear span of a class dictionary (CD) along the linear span of an occlusion error dictionary (OED). The CD and OED are constructed respectively by concatenating the DFVs of a training set and the occlusion error vectors of an extra set of image pairs. Two implementations of the SDBE are studied in this paper: the $l_1$-norm and the squared $l_2$-norm regularized least-squares estimates. By employing the ResNet-152, pre-trained on the ILSVRC2012 training set, as the base network, the proposed SBDE-based classification scheme is extensively evaluated on the Caltech-101 and ILSVRC2012 datasets. Extensive experimental results demonstrate that the proposed SDBE-based scheme dramatically boosts the classification accuracy for occluded images, and achieves around $22.25\%$ increase in classification accuracy under $20\%$ occlusion on the ILSVRC2012 dataset.
MDFN: Multi-Scale Deep Feature Learning Network for Object Detection
Dec 10, 2019
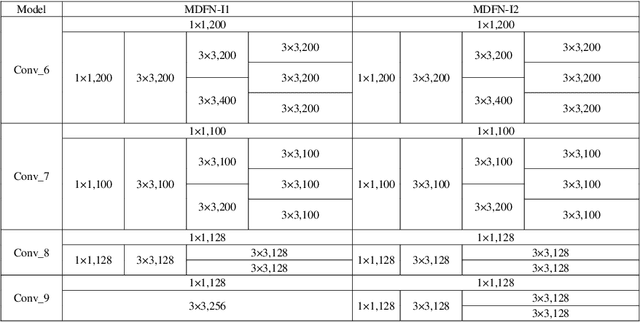
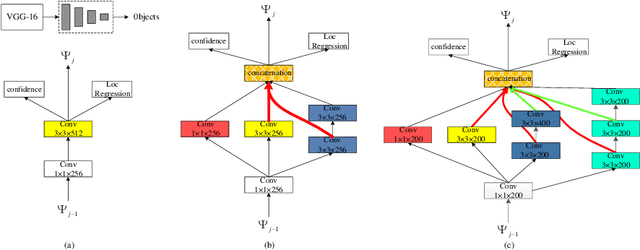
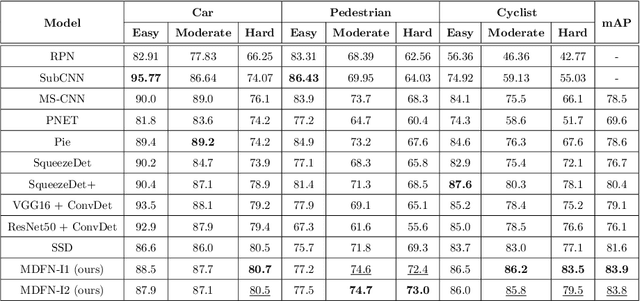
This paper proposes an innovative object detector by leveraging deep features learned in high-level layers. Compared with features produced in earlier layers, the deep features are better at expressing semantic and contextual information. The proposed deep feature learning scheme shifts the focus from concrete features with details to abstract ones with semantic information. It considers not only individual objects and local contexts but also their relationships by building a multi-scale deep feature learning network (MDFN). MDFN efficiently detects the objects by introducing information square and cubic inception modules into the high-level layers, which employs parameter-sharing to enhance the computational efficiency. MDFN provides a multi-scale object detector by integrating multi-box, multi-scale and multi-level technologies. Although MDFN employs a simple framework with a relatively small base network (VGG-16), it achieves better or competitive detection results than those with a macro hierarchical structure that is either very deep or very wide for stronger ability of feature extraction. The proposed technique is evaluated extensively on KITTI, PASCAL VOC, and COCO datasets, which achieves the best results on KITTI and leading performance on PASCAL VOC and COCO. This study reveals that deep features provide prominent semantic information and a variety of contextual contents, which contribute to its superior performance in detecting small or occluded objects. In addition, the MDFN model is computationally efficient, making a good trade-off between the accuracy and speed.