 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiti-DETR: Object Detection based on Transformers with Mitigatory Self-Attention Convergence
Dec 26, 2021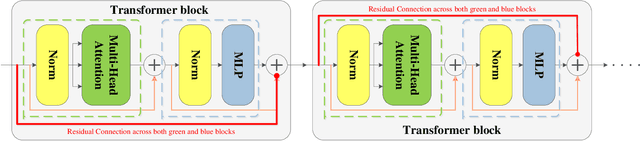



Object Detection with Transformers (DETR) and related works reach or even surpass the highly-optimized Faster-RCNN baseline with self-attention network architectures. Inspired by the evidence that pure self-attention possesses a strong inductive bias that leads to the transformer losing the expressive power with respect to network depth, we propose a transformer architecture with a mitigatory self-attention mechanism by applying possible direct mapping connections in the transformer architecture to mitigate the rank collapse so as to counteract feature expression loss and enhance the model performance. We apply this proposal in object detection tasks and develop a model named Miti-DETR. Miti-DETR reserves the inputs of each single attention layer to the outputs of that layer so that the "non-attention" information has participated in any attention propagation. The formed residual self-attention network addresses two critical issues: (1) stop the self-attention networks from degenerating to rank-1 to the maximized degree; and (2) further diversify the path distribution of parameter update so that easier attention learning is expected. Miti-DETR significantly enhances the average detection precision and convergence speed towards existing DETR-based models on the challenging COCO object detection dataset. Moreover, the proposed transformer with the residual self-attention network can be easily generalized or plugged in other related task models without specific customization.
Semantic Clustering based Deduction Learning for Image Recognition and Classification
Dec 25, 2021

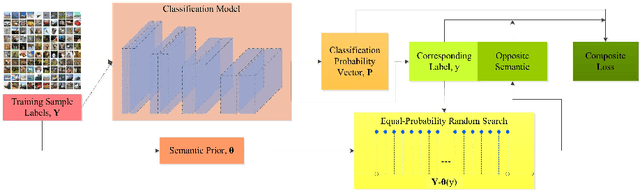

The paper proposes a semantic clustering based deduction learning by mimicking the learning and thinking process of human brains. Human beings can make judgments based on experience and cognition, and as a result, no one would recognize an unknown animal as a car. Inspired by this observation, we propose to train deep learning models using the clustering prior that can guide the models to learn with the ability of semantic deducing and summarizing from classification attributes, such as a cat belonging to animals while a car pertaining to vehicles. %Specifically, if an image is labeled as a cat, then the model is trained to learn that "this image is totally not any random class that is the outlier of animal". The proposed approach realizes the high-level clustering in the semantic space, enabling the model to deduce the relations among various classes during the learning process. In addition, the paper introduces a semantic prior based random search for the opposite labels to ensure the smooth distribution of the clustering and the robustness of the classifiers. The proposed approach is supported theoretically and empirically through extensive experiments. We compare the performance across state-of-the-art classifiers on popular benchmarks, and the generalization ability is verified by adding noisy labeling to the datasets. Experimental results demonstrate the superiority of the proposed approach.
Six-channel Image Representation for Cross-domain Object Detection
Jan 03, 2021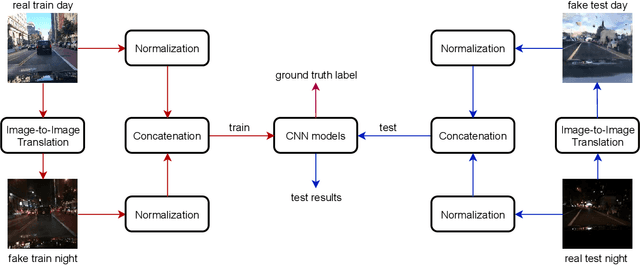



Most deep learning models are data-driven and the excellent performance is highly dependent on the abundant and diverse datasets. However, it is very hard to obtain and label the datasets of some specific scenes or applications. If we train the detector using the data from one domain, it cannot perform well on the data from another domain due to domain shift, which is one of the big challenges of most object detection models. To address this issue, some image-to-image translation techniques are employed to generate some fake data of some specific scenes to train the models. With the advent of Generative Adversarial Networks (GANs), we could realize unsupervised image-to-image translation in both directions from a source to a target domain and from the target to the source domain. In this study, we report a new approach to making use of the generated images. We propose to concatenate the original 3-channel images and their corresponding GAN-generated fake images to form 6-channel representations of the dataset, hoping to address the domain shift problem while exploiting the success of available detection models. The idea of augmented data representation may inspire further study on object detection and other applications.
Why Layer-Wise Learning is Hard to Scale-up and a Possible Solution via Accelerated Downsampling
Oct 15, 2020

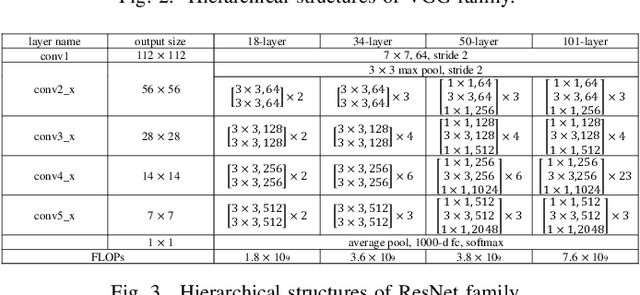

Layer-wise learning, as an alternative to global back-propagation, is easy to interpret, analyze, and it is memory efficient. Recent studies demonstrate that layer-wise learning can achieve state-of-the-art performance in image classification on various datasets. However, previous studies of layer-wise learning are limited to networks with simple hierarchical structures, and the performance decreases severely for deeper networks like ResNet. This paper, for the first time, reveals the fundamental reason that impedes the scale-up of layer-wise learning is due to the relatively poor separability of the feature space in shallow layers. This argument is empirically verified by controlling the intensity of the convolution operation in local layers. We discover that the poorly-separable features from shallow layers are mismatched with the strong supervision constraint throughout the entire network, making the layer-wise learning sensitive to network depth. The paper further proposes a downsampling acceleration approach to weaken the poor learning of shallow layers so as to transfer the learning emphasis to deep feature space where the separability matches better with the supervision restraint. Extensive experiments have been conducted to verify the new finding and demonstrate the advantages of the proposed downsampling acceleration in improving the performance of layer-wise learning.
Multi-Resolution Fusion and Multi-scale Input Priors Based Crowd Counting
Oct 04, 2020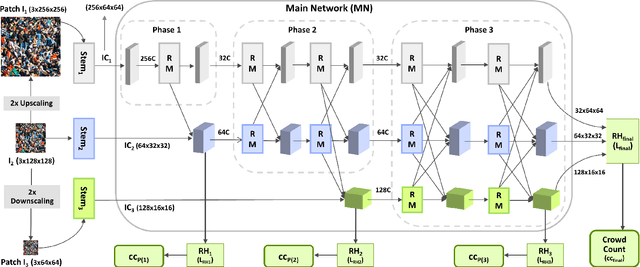



Crowd counting in still images is a challenging problem in practice due to huge crowd-density variations, large perspective changes, severe occlusion, and variable lighting conditions. The state-of-the-art patch rescaling module (PRM) based approaches prove to be very effective in improving the crowd counting performance. However, the PRM module requires an additional and compromising crowd-density classification process. To address these issues and challenges, the paper proposes a new multi-resolution fusion based end-to-end crowd counting network. It employs three deep-layers based columns/branches, each catering the respective crowd-density scale. These columns regularly fuse (share) the information with each other. The network is divided into three phases with each phase containing one or more columns. Three input priors are introduced to serve as an efficient and effective alternative to the PRM module, without requiring any additional classification operations. Along with the final crowd count regression head, the network also contains three auxiliary crowd estimation regression heads, which are strategically placed at each phase end to boost the overall performance. Comprehensive experiments on three benchmark datasets demonstrate that the proposed approach outperforms all the state-of-the-art models under the RMSE evaluation metric. The proposed approach also has better generalization capability with the best results during the cross-dataset experiments.
Location-Aware Box Reasoning for Anchor-Based Single-Shot Object Detection
Jul 13, 2020


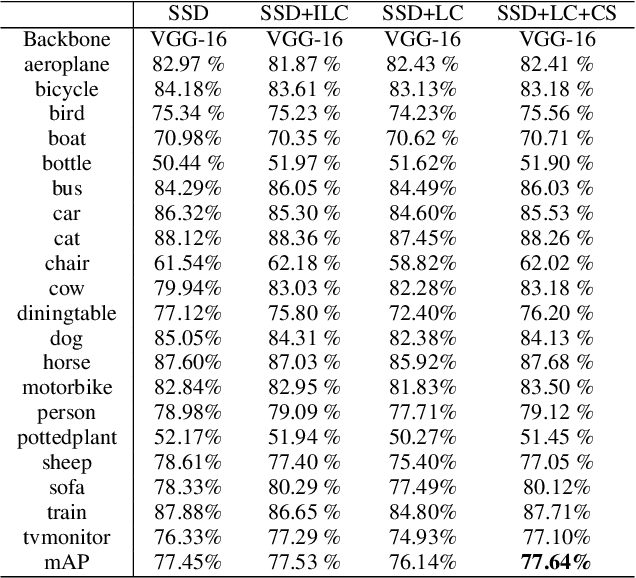
In the majority of object detection frameworks, the confidence of instance classification is used as the quality criterion of predicted bounding boxes, like the confidence-based ranking in non-maximum suppression (NMS). However, the quality of bounding boxes, indicating the spatial relations, is not only correlated with the classification scores. Compared with the region proposal network (RPN) based detectors, single-shot object detectors suffer the box quality as there is a lack of pre-selection of box proposals. In this paper, we aim at single-shot object detectors and propose a location-aware anchor-based reasoning (LAAR) for the bounding boxes. LAAR takes both the location and classification confidences into consideration for the quality evaluation of bounding boxes. We introduce a novel network block to learn the relative location between the anchors and the ground truths, denoted as a localization score, which acts as a location reference during the inference stage. The proposed localization score leads to an independent regression branch and calibrates the bounding box quality by scoring the predicted localization score so that the best-qualified bounding boxes can be picked up in NMS. Experiments on MS COCO and PASCAL VOC benchmarks demonstrate that the proposed location-aware framework enhances the performances of current anchor-based single-shot object detection frameworks and yields consistent and robust detection results.
Self-Orthogonality Module: A Network Architecture Plug-in for Learning Orthogonal Filters
Jan 17, 2020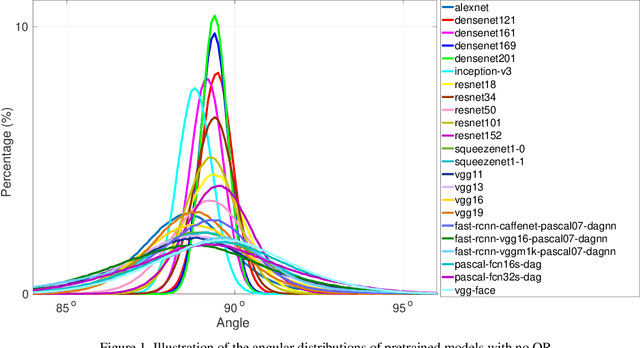
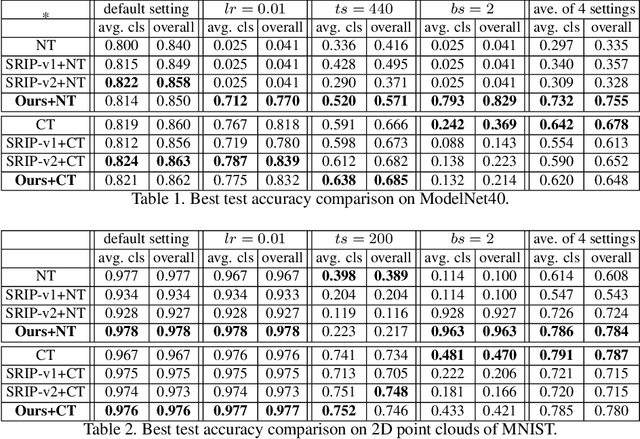
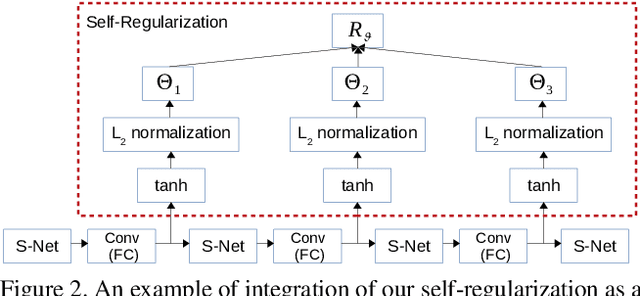
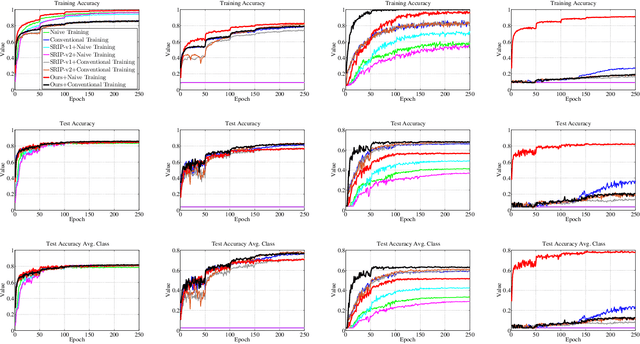
In this paper, we investigate the empirical impact of orthogonality regularization (OR) in deep learning, either solo or collaboratively. Recent works on OR showed some promising results on the accuracy. In our ablation study, however, we do not observe such significant improvement from existing OR techniques compared with the conventional training based on weight decay, dropout, and batch normalization. To identify the real gain from OR, inspired by the locality sensitive hashing (LSH) in angle estimation, we propose to introduce an implicit self-regularization into OR to push the mean and variance of filter angles in a network towards 90 and 0 simultaneously to achieve (near) orthogonality among the filters, without using any other explicit regularization. Our regularization can be implemented as an architectural plug-in and integrated with an arbitrary network. We reveal that OR helps stabilize the training process and leads to faster convergence and better generalization.
MDFN: Multi-Scale Deep Feature Learning Network for Object Detection
Dec 10, 2019
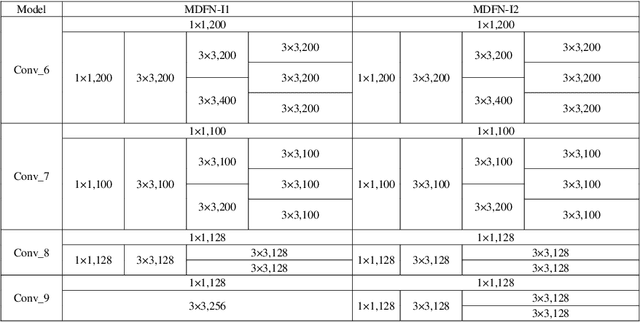
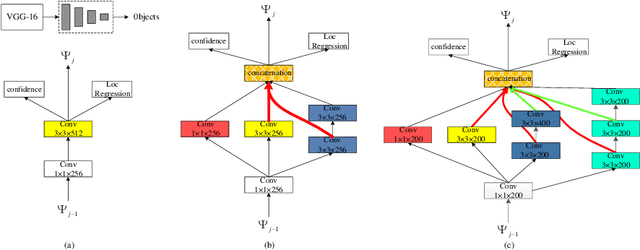
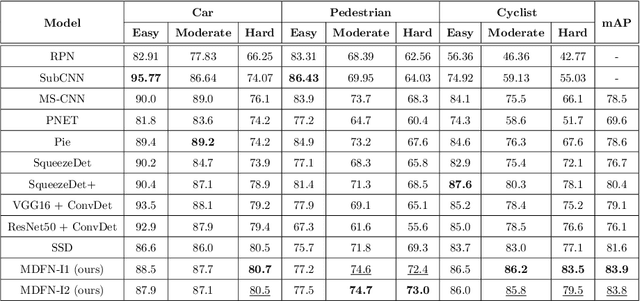
This paper proposes an innovative object detector by leveraging deep features learned in high-level layers. Compared with features produced in earlier layers, the deep features are better at expressing semantic and contextual information. The proposed deep feature learning scheme shifts the focus from concrete features with details to abstract ones with semantic information. It considers not only individual objects and local contexts but also their relationships by building a multi-scale deep feature learning network (MDFN). MDFN efficiently detects the objects by introducing information square and cubic inception modules into the high-level layers, which employs parameter-sharing to enhance the computational efficiency. MDFN provides a multi-scale object detector by integrating multi-box, multi-scale and multi-level technologies. Although MDFN employs a simple framework with a relatively small base network (VGG-16), it achieves better or competitive detection results than those with a macro hierarchical structure that is either very deep or very wide for stronger ability of feature extraction. The proposed technique is evaluated extensively on KITTI, PASCAL VOC, and COCO datasets, which achieves the best results on KITTI and leading performance on PASCAL VOC and COCO. This study reveals that deep features provide prominent semantic information and a variety of contextual contents, which contribute to its superior performance in detecting small or occluded objects. In addition, the MDFN model is computationally efficient, making a good trade-off between the accuracy and speed.
Object Detection with Convolutional Neural Networks
Dec 04, 2019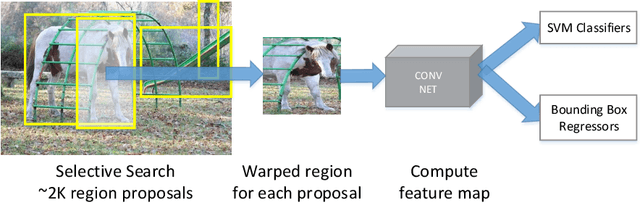

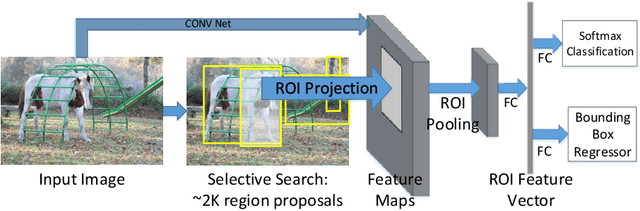
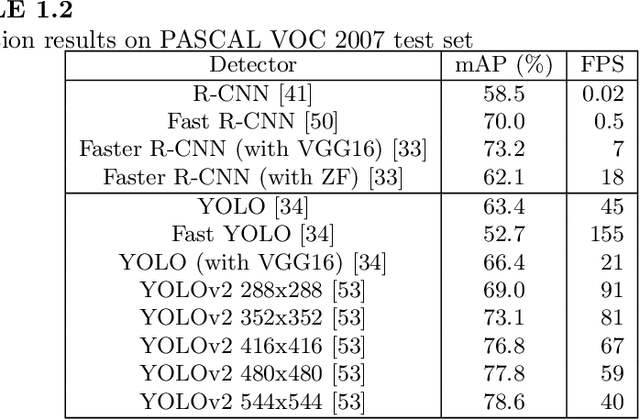
In this chapter, we present a brief overview of the recent development in object detection using convolutional neural networks (CNN). Several classical CNN-based detectors are presented. Some developments are based on the detector architectures, while others are focused on solving certain problems, like model degradation and small-scale object detection. The chapter also presents some performance comparison results of different models on several benchmark datasets. Through the discussion of these models, we hope to give readers a general idea about the developments of CNN-based object detection.
Adaptively Denoising Proposal Collection for Weakly Supervised Object Localization
Oct 19, 2019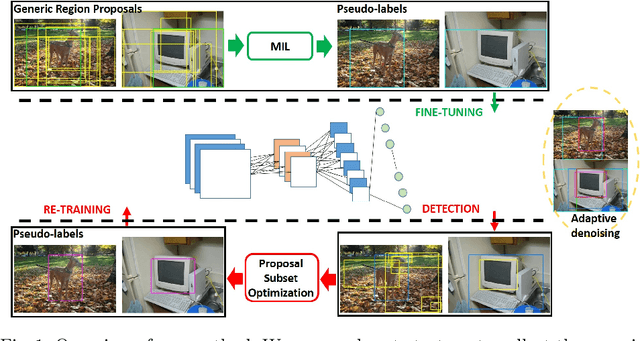
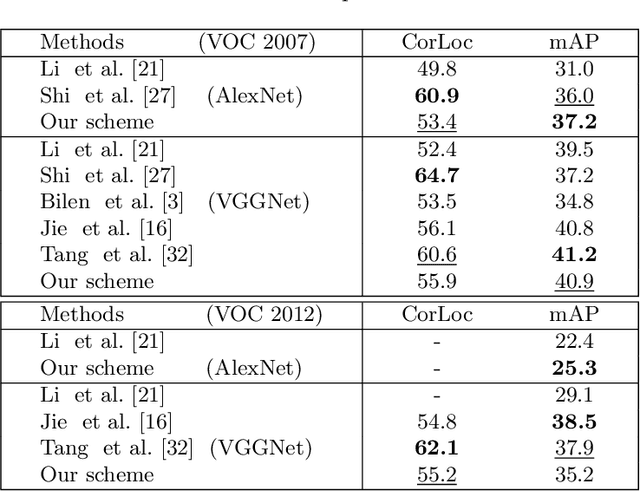


In this paper, we address the problem of weakly supervised object localization (WSL), which trains a detection network on the dataset with only image-level annotations. The proposed approach is built on the observation that the proposal set from the training dataset is a collection of background, object parts, and objects. Several strategies are taken to adaptively eliminate the noisy proposals and generate pseudo object-level annotations for the weakly labeled dataset. A multiple instance learning (MIL) algorithm enhanced by mask-out strategy is adopted to collect the class-specific object proposals, which are then utilized to adapt a pre-trained classification network to a detection network. In addition, the detection results from the detection network are re-weighted by jointly considering the detection scores and the overlap ratio of proposals in a proposal subset optimization framework. The optimal proposals work as object-level labels that enable a pseudo-strongly supervised dataset for training the detection network. Consequently, we establish a fully adaptive detection network. Extensive evaluations on the PASCAL VOC 2007 and 2012 datasets demonstrate a significant improvement compared with the state-of-the-art methods.