 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiti-DETR: Object Detection based on Transformers with Mitigatory Self-Attention Convergence
Paper and Code
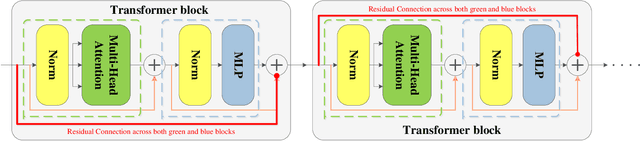



Object Detection with Transformers (DETR) and related works reach or even surpass the highly-optimized Faster-RCNN baseline with self-attention network architectures. Inspired by the evidence that pure self-attention possesses a strong inductive bias that leads to the transformer losing the expressive power with respect to network depth, we propose a transformer architecture with a mitigatory self-attention mechanism by applying possible direct mapping connections in the transformer architecture to mitigate the rank collapse so as to counteract feature expression loss and enhance the model performance. We apply this proposal in object detection tasks and develop a model named Miti-DETR. Miti-DETR reserves the inputs of each single attention layer to the outputs of that layer so that the "non-attention" information has participated in any attention propagation. The formed residual self-attention network addresses two critical issues: (1) stop the self-attention networks from degenerating to rank-1 to the maximized degree; and (2) further diversify the path distribution of parameter update so that easier attention learning is expected. Miti-DETR significantly enhances the average detection precision and convergence speed towards existing DETR-based models on the challenging COCO object detection dataset. Moreover, the proposed transformer with the residual self-attention network can be easily generalized or plugged in other related task models without specific customization.