 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDCN: Multi-Scale, Deep Inception Convolutional Neural Networks for Efficient Object Detection
Paper and Code
Sep 06, 2018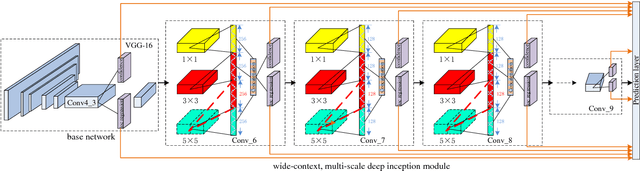

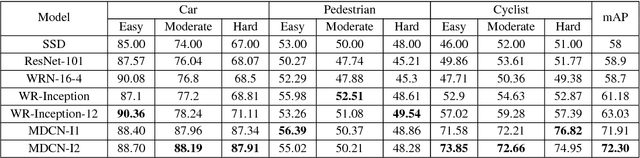
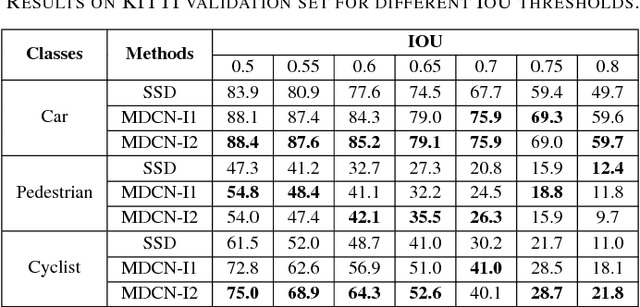
Object detection in challenging situations such as scale variation, occlusion, and truncation depends not only on feature details but also on contextual information. Most previous networks emphasize too much on detailed feature extraction through deeper and wider networks, which may enhance the accuracy of object detection to certain extent. However, the feature details are easily being changed or washed out after passing through complicated filtering structures. To better handle these challenges, the paper proposes a novel framework, multi-scale, deep inception convolutional neural network (MDCN), which focuses on wider and broader object regions by activating feature maps produced in the deep part of the network. Instead of incepting inner layers in the shallow part of the network, multi-scale inceptions are introduced in the deep layers. The proposed framework integrates the contextual information into the learning process through a single-shot network structure. It is computational efficient and avoids the hard training problem of previous macro feature extraction network designed for shallow layers. Extensive experiments demonstrate the effectiveness and superior performance of MDCN over the state-of-the-art models.