 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Scale-wise Attention Network for Effective Scene Text Recognition
Paper and Code
Apr 25, 2021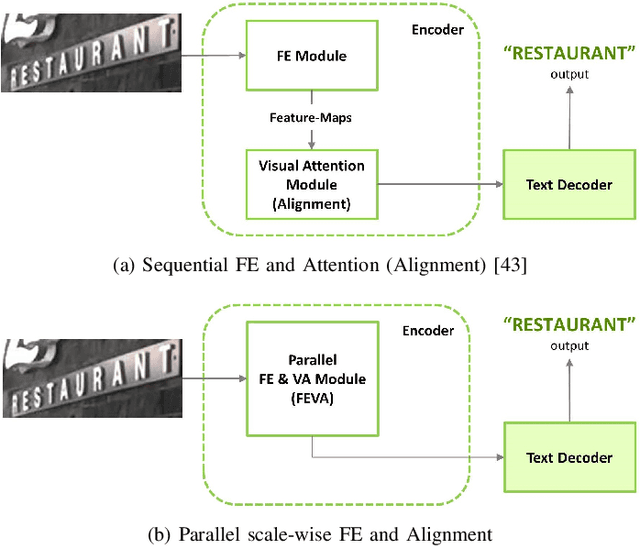
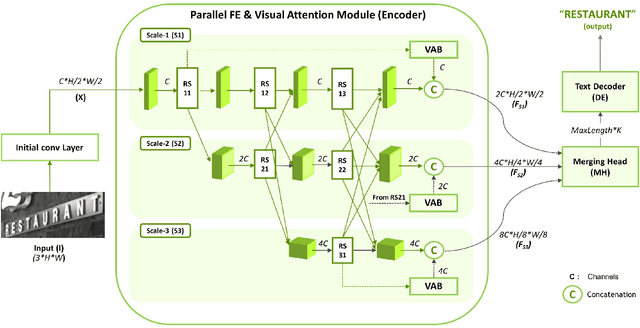
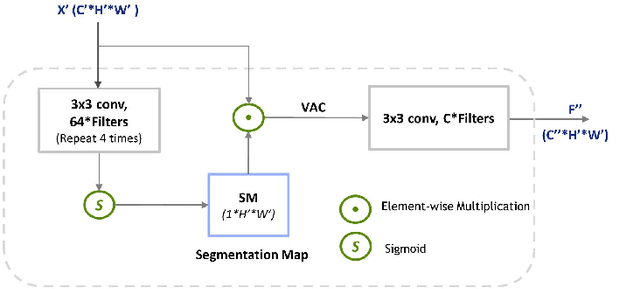

The paper proposes a new text recognition network for scene-text images. Many state-of-the-art methods employ the attention mechanism either in the text encoder or decoder for the text alignment. Although the encoder-based attention yields promising results, these schemes inherit noticeable limitations. They perform the feature extraction (FE) and visual attention (VA) sequentially, which bounds the attention mechanism to rely only on the FE final single-scale output. Moreover, the utilization of the attention process is limited by only applying it directly to the single scale feature-maps. To address these issues, we propose a new multi-scale and encoder-based attention network for text recognition that performs the multi-scale FE and VA in parallel. The multi-scale channels also undergo regular fusion with each other to develop the coordinated knowledge together. Quantitative evaluation and robustness analysis on the standard benchmarks demonstrate that the proposed network outperforms the state-of-the-art in most cases.