 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Domain Gap Aware Generative Adversarial Network for Multi-domain Image Translation
Paper and Code
Oct 21, 2021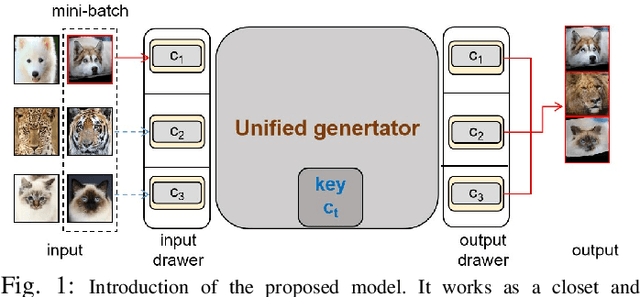



Recent image-to-image translation models have shown great success in mapping local textures between two domains. Existing approaches rely on a cycle-consistency constraint that supervises the generators to learn an inverse mapping. However, learning the inverse mapping introduces extra trainable parameters and it is unable to learn the inverse mapping for some domains. As a result, they are ineffective in the scenarios where (i) multiple visual image domains are involved; (ii) both structure and texture transformations are required; and (iii) semantic consistency is preserved. To solve these challenges, the paper proposes a unified model to translate images across multiple domains with significant domain gaps. Unlike previous models that constrain the generators with the ubiquitous cycle-consistency constraint to achieve the content similarity, the proposed model employs a perceptual self-regularization constraint. With a single unified generator, the model can maintain consistency over the global shapes as well as the local texture information across multiple domains. Extensive qualitative and quantitative evaluations demonstrate the effectiveness and superior performance over state-of-the-art models. It is more effective in representing shape deformation in challenging mappings with significant dataset variation across multiple domains.