 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMVP: A Multimodal MoCap Dataset with Vision and Pressure Sensors
Mar 30, 2024



Foot contact is an important cue for human motion capture, understanding, and generation. Existing datasets tend to annotate dense foot contact using visual matching with thresholding or incorporating pressure signals. However, these approaches either suffer from low accuracy or are only designed for small-range and slow motion. There is still a lack of a vision-pressure multimodal dataset with large-range and fast human motion, as well as accurate and dense foot-contact annotation. To fill this gap, we propose a Multimodal MoCap Dataset with Vision and Pressure sensors, named MMVP. MMVP provides accurate and dense plantar pressure signals synchronized with RGBD observations, which is especially useful for both plausible shape estimation, robust pose fitting without foot drifting, and accurate global translation tracking. To validate the dataset, we propose an RGBD-P SMPL fitting method and also a monocular-video-based baseline framework, VP-MoCap, for human motion capture. Experiments demonstrate that our RGBD-P SMPL Fitting results significantly outperform pure visual motion capture. Moreover, VP-MoCap outperforms SOTA methods in foot-contact and global translation estimation accuracy. We believe the configuration of the dataset and the baseline frameworks will stimulate the research in this direction and also provide a good reference for MoCap applications in various domains. Project page: https://metaverse-ai-lab-thu.github.io/MMVP-Dataset/.
Feature Representation Learning with Adaptive Displacement Generation and Transformer Fusion for Micro-Expression Recognition
Apr 10, 2023



Micro-expressions are spontaneous, rapid and subtle facial movements that can neither be forged nor suppressed. They are very important nonverbal communication clues, but are transient and of low intensity thus difficult to recognize. Recently deep learning based methods have been developed for micro-expression (ME) recognition using feature extraction and fusion techniques, however, targeted feature learning and efficient feature fusion still lack further study according to the ME characteristics. To address these issues, we propose a novel framework Feature Representation Learning with adaptive Displacement Generation and Transformer fusion (FRL-DGT), in which a convolutional Displacement Generation Module (DGM) with self-supervised learning is used to extract dynamic features from onset/apex frames targeted to the subsequent ME recognition task, and a well-designed Transformer Fusion mechanism composed of three Transformer-based fusion modules (local, global fusions based on AU regions and full-face fusion) is applied to extract the multi-level informative features after DGM for the final ME prediction. The extensive experiments with solid leave-one-subject-out (LOSO) evaluation results have demonstrated the superiority of our proposed FRL-DGT to state-of-the-art methods.
Self-supervised Contrastive Learning for EEG-based Sleep Staging
Sep 16, 2021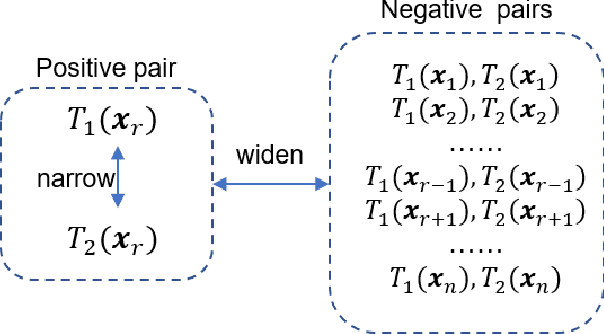
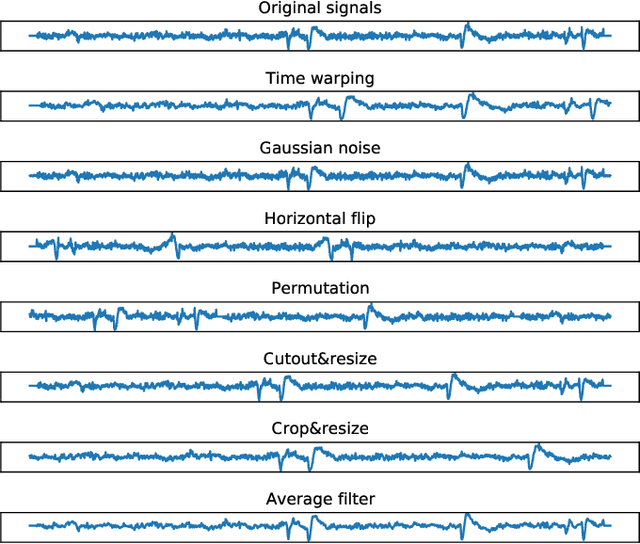
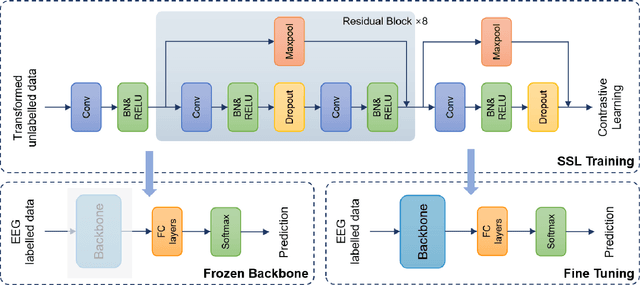
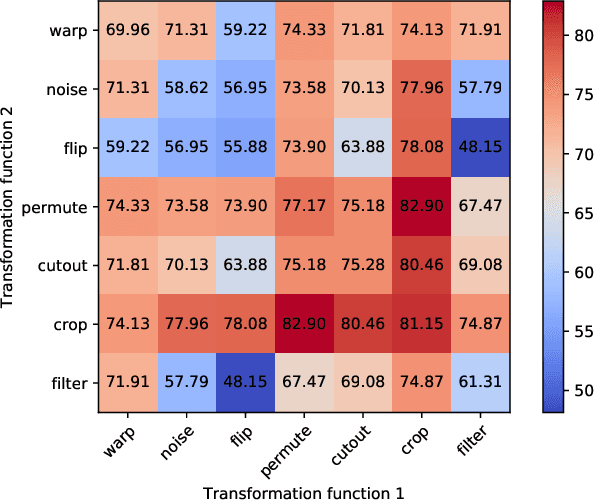
EEG signals are usually simple to obtain but expensive to label. Although supervised learning has been widely used in the field of EEG signal analysis, its generalization performance is limited by the amount of annotated data. Self-supervised learning (SSL), as a popular learning paradigm in computer vision (CV) and natural language processing (NLP), can employ unlabeled data to make up for the data shortage of supervised learning. In this paper, we propose a self-supervised contrastive learning method of EEG signals for sleep stage classification. During the training process, we set up a pretext task for the network in order to match the right transformation pairs generated from EEG signals. In this way, the network improves the representation ability by learning the general features of EEG signals. The robustness of the network also gets improved in dealing with diverse data, that is, extracting constant features from changing data. In detail, the network's performance depends on the choice of transformations and the amount of unlabeled data used in the training process of self-supervised learning. Empirical evaluations on the Sleep-edf dataset demonstrate the competitive performance of our method on sleep staging (88.16% accuracy and 81.96% F1 score) and verify the effectiveness of SSL strategy for EEG signal analysis in limited labeled data regimes. All codes are provided publicly online.
SimulCap : Single-View Human Performance Capture with Cloth Simulation
Mar 18, 2019
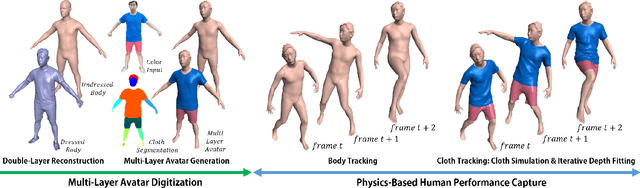

This paper proposes a new method for live free-viewpoint human performance capture with dynamic details (e.g., cloth wrinkles) using a single RGBD camera. Our main contributions are: (i) a multi-layer representation of garments and body, and (ii) a physics-based performance capture procedure. We first digitize the performer using multi-layer surface representation, which includes the undressed body surface and separate clothing meshes. For performance capture, we perform skeleton tracking, cloth simulation, and iterative depth fitting sequentially for the incoming frame. By incorporating cloth simulation into the performance capture pipeline, we can simulate plausible cloth dynamics and cloth-body interactions even in the occluded regions, which was not possible in previous capture methods. Moreover, by formulating depth fitting as a physical process, our system produces cloth tracking results consistent with the depth observation while still maintaining physical constraints. Results and evaluations show the effectiveness of our method. Our method also enables new types of applications such as cloth retargeting, free-viewpoint video rendering and animations.
DoubleFusion: Real-time Capture of Human Performances with Inner Body Shapes from a Single Depth Sensor
Apr 17, 2018
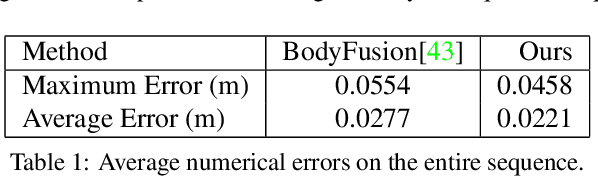


We propose DoubleFusion, a new real-time system that combines volumetric dynamic reconstruction with data-driven template fitting to simultaneously reconstruct detailed geometry, non-rigid motion and the inner human body shape from a single depth camera. One of the key contributions of this method is a double layer representation consisting of a complete parametric body shape inside, and a gradually fused outer surface layer. A pre-defined node graph on the body surface parameterizes the non-rigid deformations near the body, and a free-form dynamically changing graph parameterizes the outer surface layer far from the body, which allows more general reconstruction. We further propose a joint motion tracking method based on the double layer representation to enable robust and fast motion tracking performance. Moreover, the inner body shape is optimized online and forced to fit inside the outer surface layer. Overall, our method enables increasingly denoised, detailed and complete surface reconstructions, fast motion tracking performance and plausible inner body shape reconstruction in real-time. In particular, experiments show improved fast motion tracking and loop closure performance on more challenging scenarios.