 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Lenses: Plug-and-play Neural Modules for Transformation-Invariant Visual Representations
Paper and Code
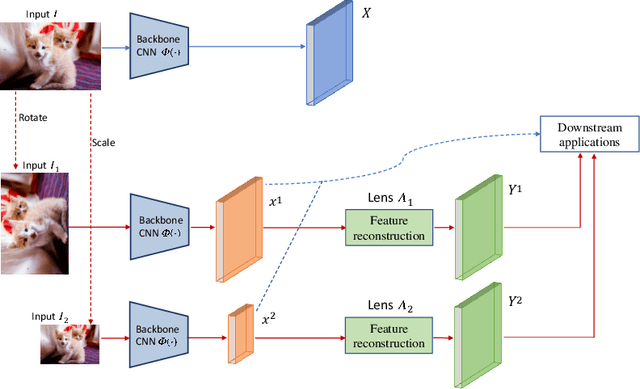
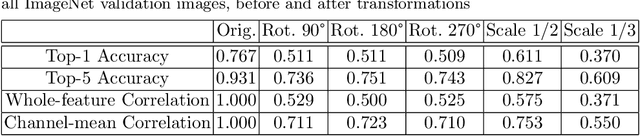
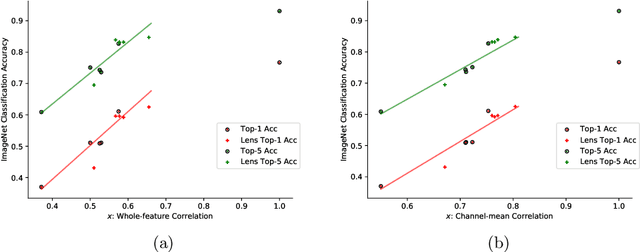
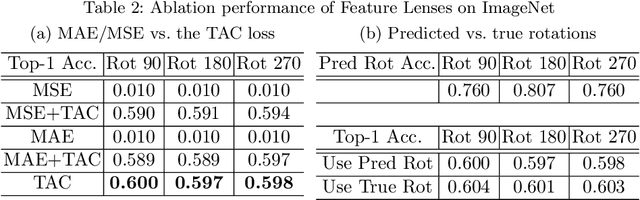
Convolutional Neural Networks (CNNs) are known to be brittle under various image transformations, including rotations, scalings, and changes of lighting conditions. We observe that the features of a transformed image are drastically different from the ones of the original image. To make CNNs more invariant to transformations, we propose "Feature Lenses", a set of ad-hoc modules that can be easily plugged into a trained model (referred to as the "host model"). Each individual lens reconstructs the original features given the features of a transformed image under a particular transformation. These lenses jointly counteract feature distortions caused by various transformations, thus making the host model more robust without retraining. By only updating lenses, the host model is freed from iterative updating when facing new transformations absent in the training data; as feature semantics are preserved, downstream applications, such as classifiers and detectors, automatically gain robustness without retraining. Lenses are trained in a self-supervised fashion with no annotations, by minimizing a novel "Top-K Activation Contrast Loss" between lens-transformed features and original features. Evaluated on ImageNet, MNIST-rot, and CIFAR-10, Feature Lenses show clear advantages over baseline methods.