 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOCUS: Frequency-Optimized Conditioning of DiffUSion Models for mitigating catastrophic forgetting during Test-Time Adaptation
Aug 20, 2025Test-time adaptation enables models to adapt to evolving domains. However, balancing the tradeoff between preserving knowledge and adapting to domain shifts remains challenging for model adaptation methods, since adapting to domain shifts can induce forgetting of task-relevant knowledge. To address this problem, we propose FOCUS, a novel frequency-based conditioning approach within a diffusion-driven input-adaptation framework. Utilising learned, spatially adaptive frequency priors, our approach conditions the reverse steps during diffusion-driven denoising to preserve task-relevant semantic information for dense prediction. FOCUS leverages a trained, lightweight, Y-shaped Frequency Prediction Network (Y-FPN) that disentangles high and low frequency information from noisy images. This minimizes the computational costs involved in implementing our approach in a diffusion-driven framework. We train Y-FPN with FrequencyMix, a novel data augmentation method that perturbs the images across diverse frequency bands, which improves the robustness of our approach to diverse corruptions. We demonstrate the effectiveness of FOCUS for semantic segmentation and monocular depth estimation across 15 corruption types and three datasets, achieving state-of-the-art averaged performance. In addition to improving standalone performance, FOCUS complements existing model adaptation methods since we can derive pseudo labels from FOCUS-denoised images for additional supervision. Even under limited, intermittent supervision with the pseudo labels derived from the FOCUS denoised images, we show that FOCUS mitigates catastrophic forgetting for recent model adaptation methods.
Generating Reliable Pixel-Level Labels for Source Free Domain Adaptation
Jul 03, 2023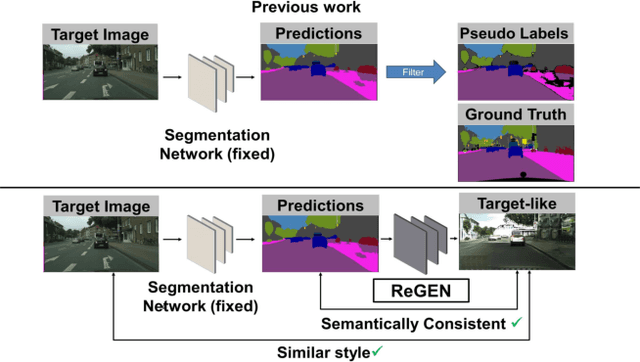

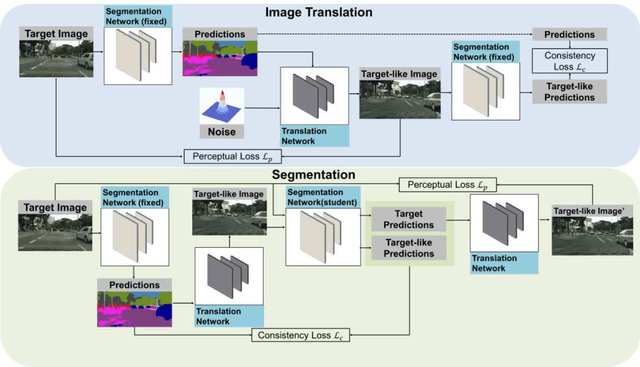
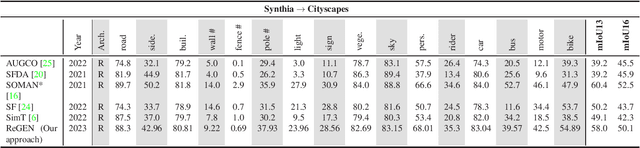
This work addresses the challenging domain adaptation setting in which knowledge from the labelled source domain dataset is available only from the pretrained black-box segmentation model. The pretrained model's predictions for the target domain images are noisy because of the distributional differences between the source domain data and the target domain data. Since the model's predictions serve as pseudo labels during self-training, the noise in the predictions impose an upper bound on model performance. Therefore, we propose a simple yet novel image translation workflow, ReGEN, to address this problem. ReGEN comprises an image-to-image translation network and a segmentation network. Our workflow generates target-like images using the noisy predictions from the original target domain images. These target-like images are semantically consistent with the noisy model predictions and therefore can be used to train the segmentation network. In addition to being semantically consistent with the predictions from the original target domain images, the generated target-like images are also stylistically similar to the target domain images. This allows us to leverage the stylistic differences between the target-like images and the target domain image as an additional source of supervision while training the segmentation model. We evaluate our model with two benchmark domain adaptation settings and demonstrate that our approach performs favourably relative to recent state-of-the-art work. The source code will be made available.
Adaptive Stylization Modulation for Domain Generalized Semantic Segmentation
Apr 20, 2023Obtaining sufficient labelled data for model training is impractical for most real-life applications. Therefore, we address the problem of domain generalization for semantic segmentation tasks to reduce the need to acquire and label additional data. Recent work on domain generalization increase data diversity by varying domain-variant features such as colour, style and texture in images. However, excessive stylization or even uniform stylization may reduce performance. Performance reduction is especially pronounced for pixels from minority classes, which are already more challenging to classify compared to pixels from majority classes. Therefore, we introduce a module, $ASH_{+}$, that modulates stylization strength for each pixel depending on the pixel's semantic content. In this work, we also introduce a parameter that balances the element-wise and channel-wise proportion of stylized features with the original source domain features in the stylized source domain images. This learned parameter replaces an empirically determined global hyperparameter, allowing for more fine-grained control over the output stylized image. We conduct multiple experiments to validate the effectiveness of our proposed method. Finally, we evaluate our model on the publicly available benchmark semantic segmentation datasets (Cityscapes and SYNTHIA). Quantitative and qualitative comparisons indicate that our approach is competitive with state-of-the-art. Code is made available at \url{https://github.com/placeholder}
Adversarial Semantic Hallucination for Domain Generalized Semantic Segmentation
Jun 08, 2021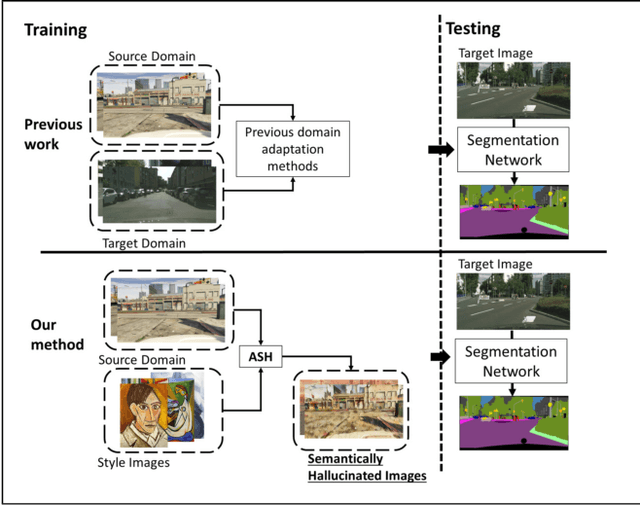
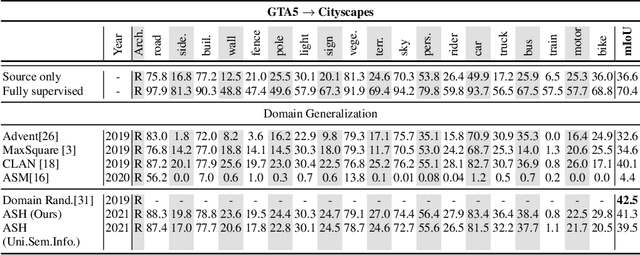
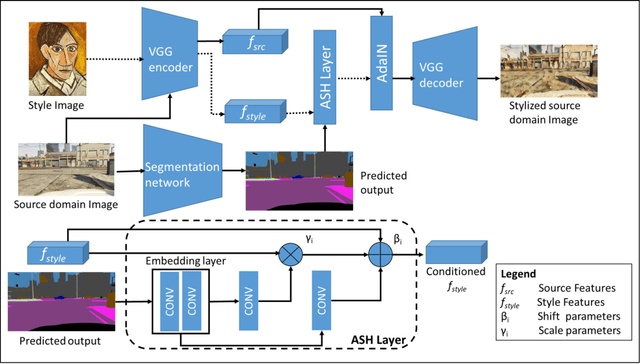
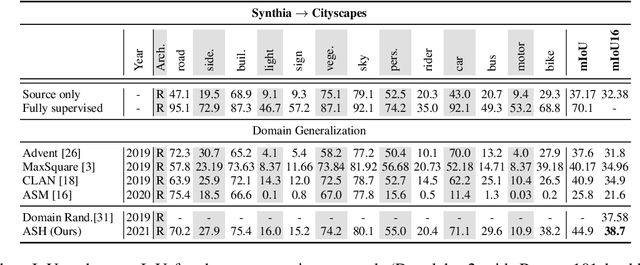
Convolutional neural networks may perform poorly when the test and train data are from different domains. While this problem can be mitigated by using the target domain data to align the source and target domain feature representations, the target domain data may be unavailable due to privacy concerns. Consequently, there is a need for methods that generalize well without access to target domain data during training. In this work, we propose an adversarial hallucination approach, which combines a class-wise hallucination module and a semantic segmentation module. Since the segmentation performance varies across different classes, we design a semantic-conditioned style hallucination layer to adaptively stylize each class. The classwise stylization parameters are generated from the semantic knowledge in the segmentation probability maps of the source domain image. Both modules compete adversarially, with the hallucination module generating increasingly 'difficult' style images to challenge the segmentation module. In response, the segmentation module improves its performance as it is trained with generated samples at an appropriate class-wise difficulty level. Experiments on state of the art domain adaptation work demonstrate the efficacy of our proposed method when no target domain data are available for training.
Accurate Tumor Tissue Region Detection with Accelerated Deep Convolutional Neural Networks
Apr 18, 2020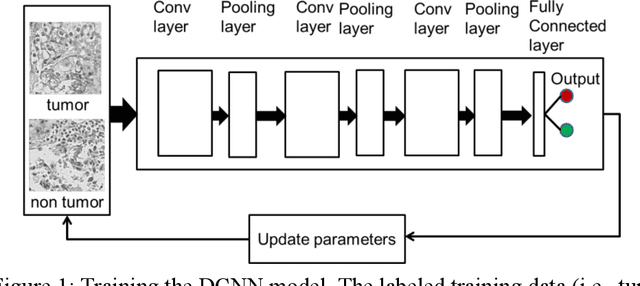
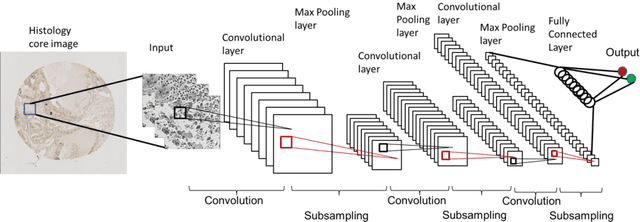

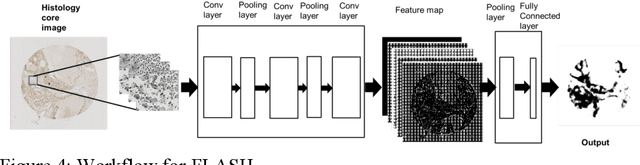
Manual annotation of pathology slides for cancer diagnosis is laborious and repetitive. Therefore, much effort has been devoted to develop computer vision solutions. Our approach, (FLASH), is based on a Deep Convolutional Neural Network (DCNN) architecture. It reduces computational costs and is faster than typical deep learning approaches by two orders of magnitude, making high throughput processing a possibility. In computer vision approaches using deep learning methods, the input image is subdivided into patches which are separately passed through the neural network. Features extracted from these patches are used by the classifier to annotate the corresponding region. Our approach aggregates all the extracted features into a single matrix before passing them to the classifier. Previously, the features are extracted from overlapping patches. Aggregating the features eliminates the need for processing overlapping patches, which reduces the computations required. DCCN and FLASH demonstrate high sensitivity (~ 0.96), good precision (~0.78) and high F1 scores (~0.84). The average time taken to process each sample for FLASH and DCNN is 96.6 seconds and 9489.20 seconds, respectively. Our approach was approximately 100 times faster than the original DCNN approach while simultaneously preserving high accuracy and precision.
Multi-Instance Multi-Scale CNN for Medical Image Classification
Jul 31, 2019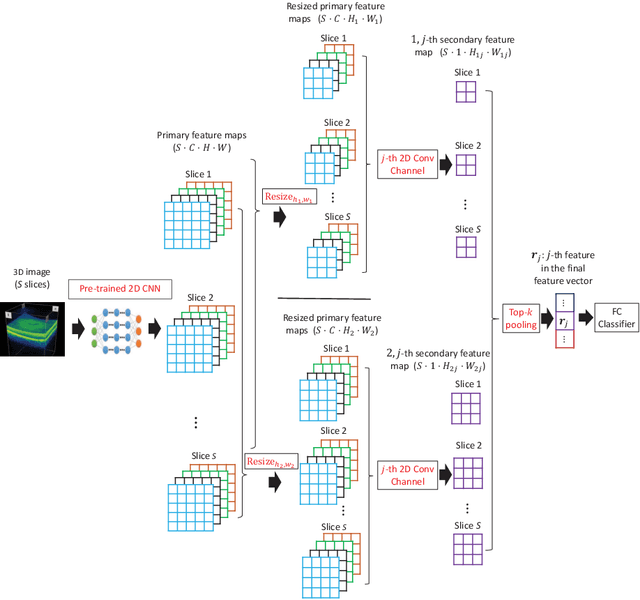
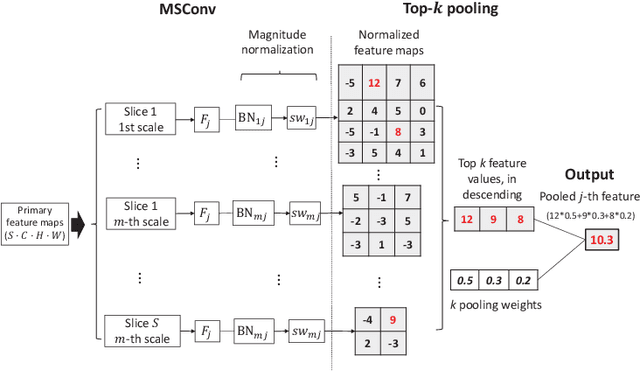

Deep learning for medical image classification faces three major challenges: 1) the number of annotated medical images for training are usually small; 2) regions of interest (ROIs) are relatively small with unclear boundaries in the whole medical images, and may appear in arbitrary positions across the x,y (and also z in 3D images) dimensions. However often only labels of the whole images are annotated, and localized ROIs are unavailable; and 3) ROIs in medical images often appear in varying sizes (scales). We approach these three challenges with a Multi-Instance Multi-Scale (MIMS) CNN: 1) We propose a multi-scale convolutional layer, which extracts patterns of different receptive fields with a shared set of convolutional kernels, so that scale-invariant patterns are captured by this compact set of kernels. As this layer contains only a small number of parameters, training on small datasets becomes feasible; 2) We propose a "top-k pooling" to aggregate the feature maps in varying scales from multiple spatial dimensions, allowing the model to be trained using weak annotations within the multiple instance learning (MIL) framework. Our method is shown to perform well on three classification tasks involving two 3D and two 2D medical image datasets.