 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Reliable Pixel-Level Labels for Source Free Domain Adaptation
Jul 03, 2023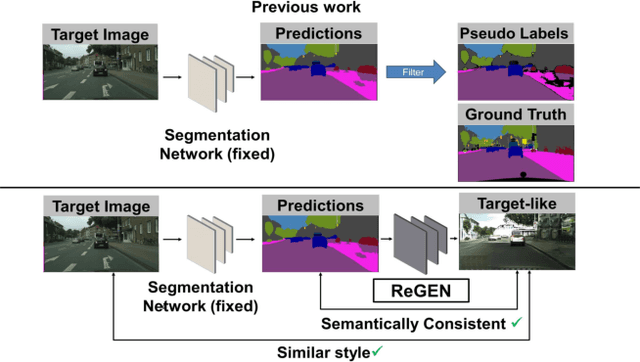

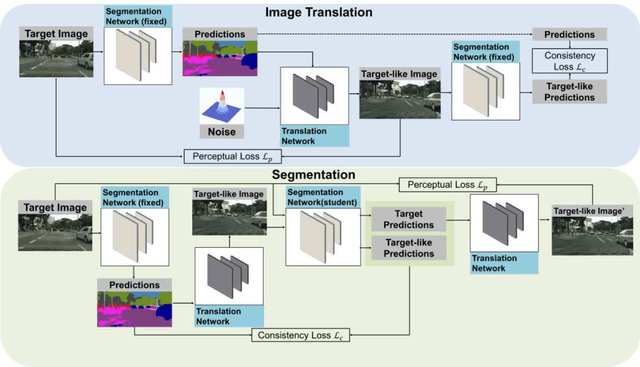
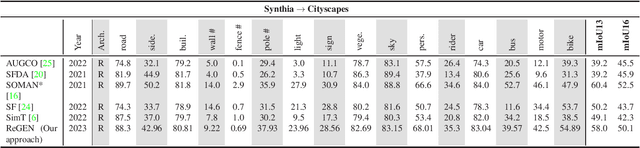
This work addresses the challenging domain adaptation setting in which knowledge from the labelled source domain dataset is available only from the pretrained black-box segmentation model. The pretrained model's predictions for the target domain images are noisy because of the distributional differences between the source domain data and the target domain data. Since the model's predictions serve as pseudo labels during self-training, the noise in the predictions impose an upper bound on model performance. Therefore, we propose a simple yet novel image translation workflow, ReGEN, to address this problem. ReGEN comprises an image-to-image translation network and a segmentation network. Our workflow generates target-like images using the noisy predictions from the original target domain images. These target-like images are semantically consistent with the noisy model predictions and therefore can be used to train the segmentation network. In addition to being semantically consistent with the predictions from the original target domain images, the generated target-like images are also stylistically similar to the target domain images. This allows us to leverage the stylistic differences between the target-like images and the target domain image as an additional source of supervision while training the segmentation model. We evaluate our model with two benchmark domain adaptation settings and demonstrate that our approach performs favourably relative to recent state-of-the-art work. The source code will be made available.